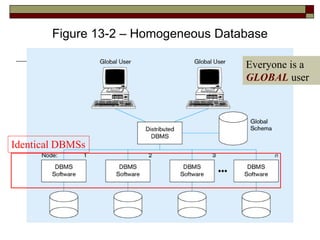
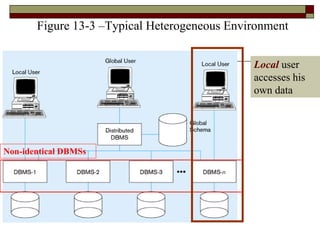
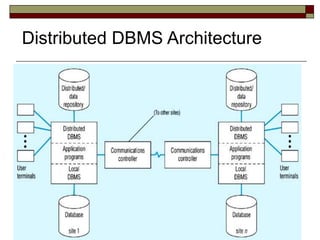
The document outlines the key concepts, objectives, advantages, and challenges of distributed databases, comparing them to decentralized databases and discussing replication methods, data partitioning, and DBMS functionality. It emphasizes the need for reliability, local autonomy, and efficient data access, while also addressing trade-offs in data integrity and system complexity. The advantages include increased availability and modular growth, while disadvantages involve costs and potential slowdowns based on data distribution strategies.