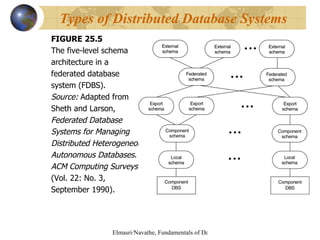
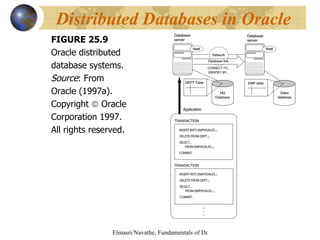
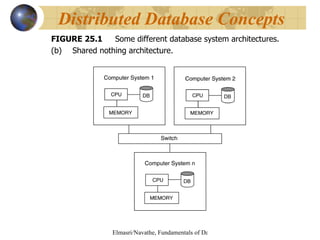
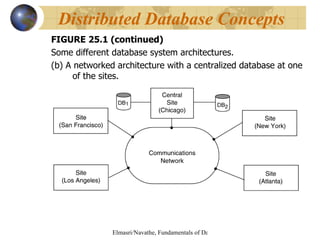
This document discusses distributed databases and client-server architectures. It covers topics such as distributed database concepts, data fragmentation and replication techniques, types of distributed database systems, query processing, concurrency control, and Oracle's implementation of distributed databases.






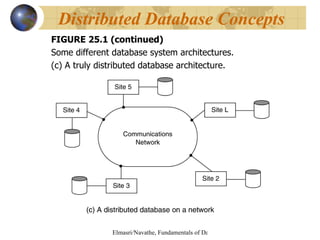


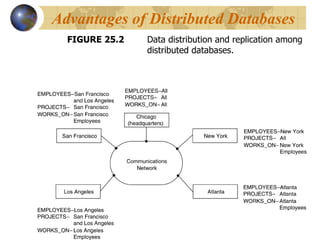






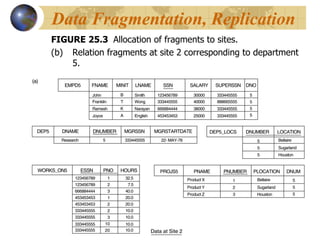

![FIGURE 25.4 Complete and disjoint fragments of the WORKS_ON relation. Fragments of WORKS_ON for employees working in department 5 (C=[ESSN IN (SELECT SSN FROM EMPLOYEE WHERE DNO=5)]). Data Fragmentation, Replication](https://image.slidesharecdn.com/chapter25-13059260921884-phpapp02-110520162459-phpapp02/85/Chapter25-20-320.jpg)
![FIGURE 25.4 (continued) Complete and disjoint fragments of the WORKS_ON relation. (b) Fragments of WORKS_ON for employees working in department 4 (C=[ESSN IN (SELECT SSN FROM EMPLOYEE WHERE DNO=4)]). Data Fragmentation, Replication](https://image.slidesharecdn.com/chapter25-13059260921884-phpapp02-110520162459-phpapp02/85/Chapter25-21-320.jpg)
![FIGURE 25.4 (continued) Complete and disjoint fragments of the WORKS_ON relation. Fragments of WORKS_ON for employees working in department 1 (C=[ESSN IN (SELECT SSN FROM EMPLOYEE WHERE DNO=1)]). Data Fragmentation, Replication](https://image.slidesharecdn.com/chapter25-13059260921884-phpapp02-110520162459-phpapp02/85/Chapter25-22-320.jpg)