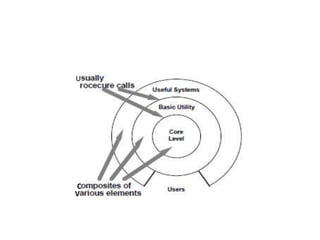
The document discusses several architectural styles for software systems, including pipe and filter, data abstraction/object-oriented organization, and event-based implicit invocation. Pipe and filter architectures treat components as independent filters connected by pipes. Data abstraction/object-oriented styles encapsulate data and operations in objects that interact through method calls. Event-based implicit invocation uses events to trigger the implicit invocation of registered component procedures. Each style has advantages like reusability and disadvantages like reduced control flow understanding.






































































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







