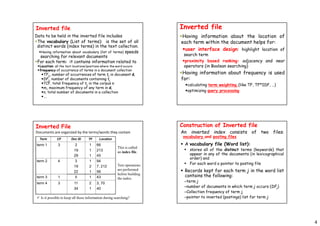
The document discusses various indexing structures used to improve efficiency of information retrieval from document collections. It describes sequential files which arrange records sequentially but sorted on a key. Inverted files list terms alphabetically with pointers to documents containing the term. Suffix trees and arrays store suffixes to enable fast lookups. The construction of inverted files involves extracting terms, building vocabulary and postings lists. Searching inverted files uses binary search on vocabulary and accesses postings lists. Suffix trees compactly store all suffixes to enable prefix matching.








![9
Suffix Tree Applications
•Suffix Tree can be used to solve a large number
of string problems that occur in:
–text-editing,
–free-text search,
–etc.
•Some examples of string problems are given
below.
–String matching
–Longest Common Substring
–Longest Repeated Substring
–Palindromes
–etc..
Complexity Analysis
The suffix tree for a string can be built in
O(n2) time.
Searching is very fast: The search time is
linear in the length of string S.
The number of leaves is n+1, where n is the number
of input strings.
Furthermore, in the leaves, we may store either the
strings themselves or pointers to the strings (that
is, integers).
Searching for a substring[1..m], in
string[1..n], can be solved in O(m) time.
Expensive memory-wise
Suffix trees consume a lot of space
How many bytes required to store MISSISSIPI ?
35
Thank you](https://image.slidesharecdn.com/chapter3-230522080510-8f474a1c/85/Chapter-3-Indexing-pdf-9-320.jpg)











































































