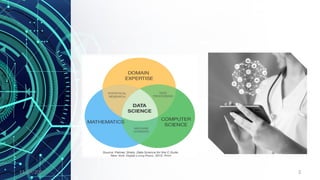
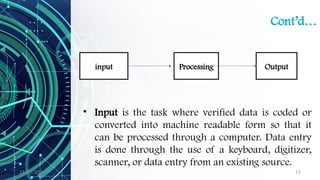
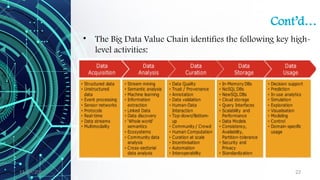
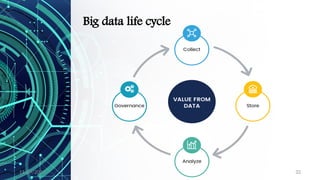
The document provides an overview of data science, including its definition, the distinction between data and information, and the data processing life cycle. It outlines the roles and skills of data scientists, the various types of data (structured, semi-structured, and unstructured), and introduces concepts related to big data and the Hadoop ecosystem. Additionally, it highlights the importance of understanding data types and metadata in the context of data analytics.



































![Chapter 2 - Intro to Data Sciences[2].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-introtodatasciences2-230326001432-ec8e4032-thumbnail.jpg?width=640&height=640&fit=bounds)




























































