Data science involves analyzing structured, semi-structured, and unstructured data to extract knowledge and insights. It employs techniques from fields like statistics, computer science, and information science. Data scientists possess strong skills in programming, statistics, data modeling, and machine learning. The data processing lifecycle involves data acquisition, analysis, curation, storage, and exploration. Big data is characterized by its volume, velocity, and variety. Technologies like Hadoop use clustered computing and distributed storage like HDFS to efficiently process and store large amounts of structured and unstructured data.













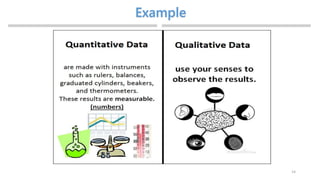








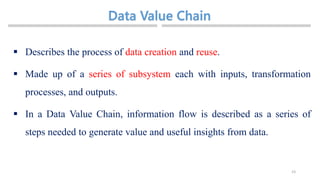
































![Chapter 2 - Intro to Data Sciences[2].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-introtodatasciences2-230326001432-ec8e4032-thumbnail.jpg?width=640&height=640&fit=bounds)






































