chapter 2 Data Science.pdf emerging ecnology freshman course
1.
Chapter 2: DataScience
Topics covered:
• Data and information.
• Data processing life cycle
• Different data types from diverse perspectives
• What is data science and the role of data scientists.
• Data value chain in emerging era of big data.
• Basics of Big Data.
• The purpose of the Hadoop ecosystem components
1
2.
What are Dataand Information
What is Data?
• Data can be defined as a representation of facts, concepts, or
instructions in a formalized manner, which should be suitable for
communication, interpretation, or processing, by human or electronic
machines.
• Data is a collection of raw facts and figures
• It can be described as unprocessed facts and figures
• It takes variety like numeric, text, voice and images.
• It is represented with the help of characters such as alphabets (A-Z, a-
z), digits (0-9) or special characters (+, -, /, *, <,>, =, etc.
2
3.
What are Dataand Information
What is Information?
• Information is processed data on which decisions and actions are
based
• Information is data that has been transformed into a meaningful
and useful context for a specific user.
• Information is data that has been processed into a form that is meaningful to
the recipient
• Information is interpreted data; created from organized, structured,
and processed data in a particular context
3
4.
Data Processing Cycle
•Data processing is the conversion of raw data to meaningful information
through a process.
• Data processing is the re-structuring or re-ordering of data by people or
machines to increase their usefulness and add values for a particular purpose.
• Data processing consists of the following basic steps - input, processing, and
output
Input Processing Output
• Input − in this step, the input data is prepared in some convenient form for
processing.
• Data entry is done through the use of a keyboard, CD, flash disk, scanner, etc.
4
5.
Data Processing Cycle
•Processing − in this step, the input data is changed to produce data in a more
useful form.
• For example, interest can be calculated on deposit to a bank.
• Output - the stage where processed information is now transmitted to
the user.
• Output is presented to users in various report formats like printed report, audio,
video, or on monitor.
5
6.
Data types andtheir representations
• Data types can be described from diverse perspectives.
• In computer science and computer programming, for instance, a data type is
simply an attribute of data that tells the compiler or interpreter how the
programmer intends to use the data.
Data types from Computer programming perspective
• Common data types include
• Integers(int)- is used to store whole numbers, mathematically known as integers
• Booleans(bool)- is used to represent restricted to one of two values: true or false
• Characters(char)- is used to store a single character
• Floating-point numbers(float)- is used to store real numbers
• Alphanumeric strings(string)- used to store a combination of characters and numbers
• Data type defines the operations that can be done on the data, the meaning of
the data, and the way values of that type can be stored
6
7.
Data types andtheir representations
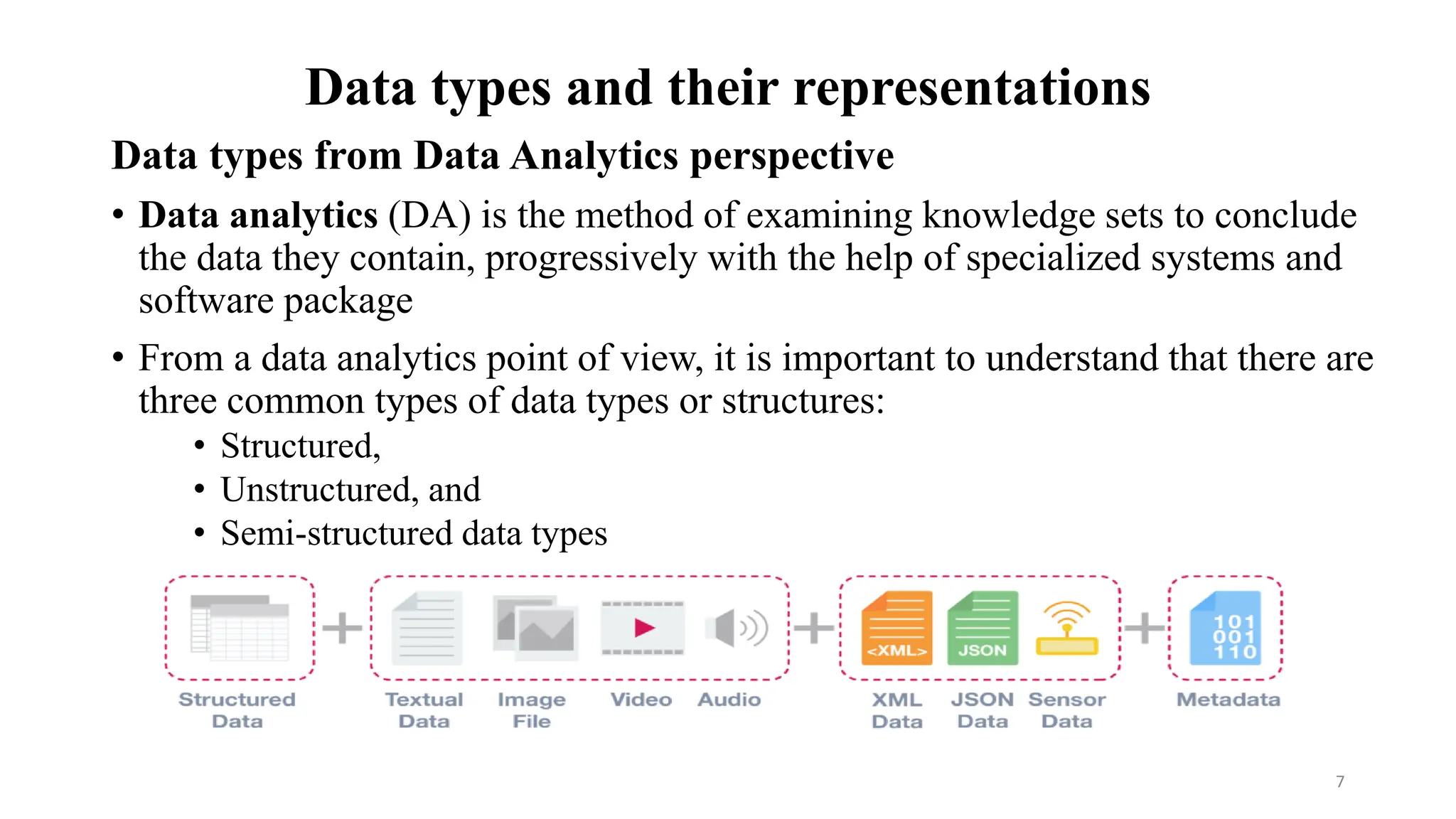
Data types from Data Analytics perspective
• Data analytics (DA) is the method of examining knowledge sets to conclude
the data they contain, progressively with the help of specialized systems and
software package
• From a data analytics point of view, it is important to understand that there are
three common types of data types or structures:
• Structured,
• Unstructured, and
• Semi-structured data types
• data types
7
8.
Structured Data
• Structureddata is data that adheres to a pre-defined data model and is
therefore straightforward to analyze.
• Structured data concerns all data which can be stored in database SQL in table
with rows and columns.
• They have relational key and can be easily mapped into pre-designed fields.
• Structured data is highly organized information that uploads neatly into a
relational database
• Structured data is relatively simple to enter, store, query, and analyze, but it
must be strictly defined in terms of field name and type
• Common examples of structured data are Excel files or SQL databases.
8
9.
Unstructured Data
• Unstructureddata is information that either does not have a predefined data
model or is not organized in a pre-defined manner.
• Unstructured data may have its own internal structure, but does not conform
neatly into a spreadsheet or database.
• Most business interactions, in fact, are unstructured in nature.
• Today more than 80% of the data generated is unstructured.
• The fundamental challenge of unstructured data sources is that they are
difficult for nontechnical business users and data analysts alike to understand
and prepare for analytic use.
• Common examples of unstructured data include audio, video files, word, PDF, text,
etc
9
10.
Semi structured Data
•Semi-structured data is a form of structured data that does not conform with the
formal structure of data models associated with relational databases or other forms
of data tables, but nonetheless, contains tags or other markers to separate semantic
elements and enforce hierarchies of records and fields within the data.
• Semi-structured data is information that doesn’t reside in a relational database but
that does have some organizational properties that make it easier to analyze.
• Examples of semi-structured data include JSON ( JavaScript Object Notation) and
XML (Extensible Markup Language) are forms of semi-structured data.
10
11.
Metadata – Dataabout Data
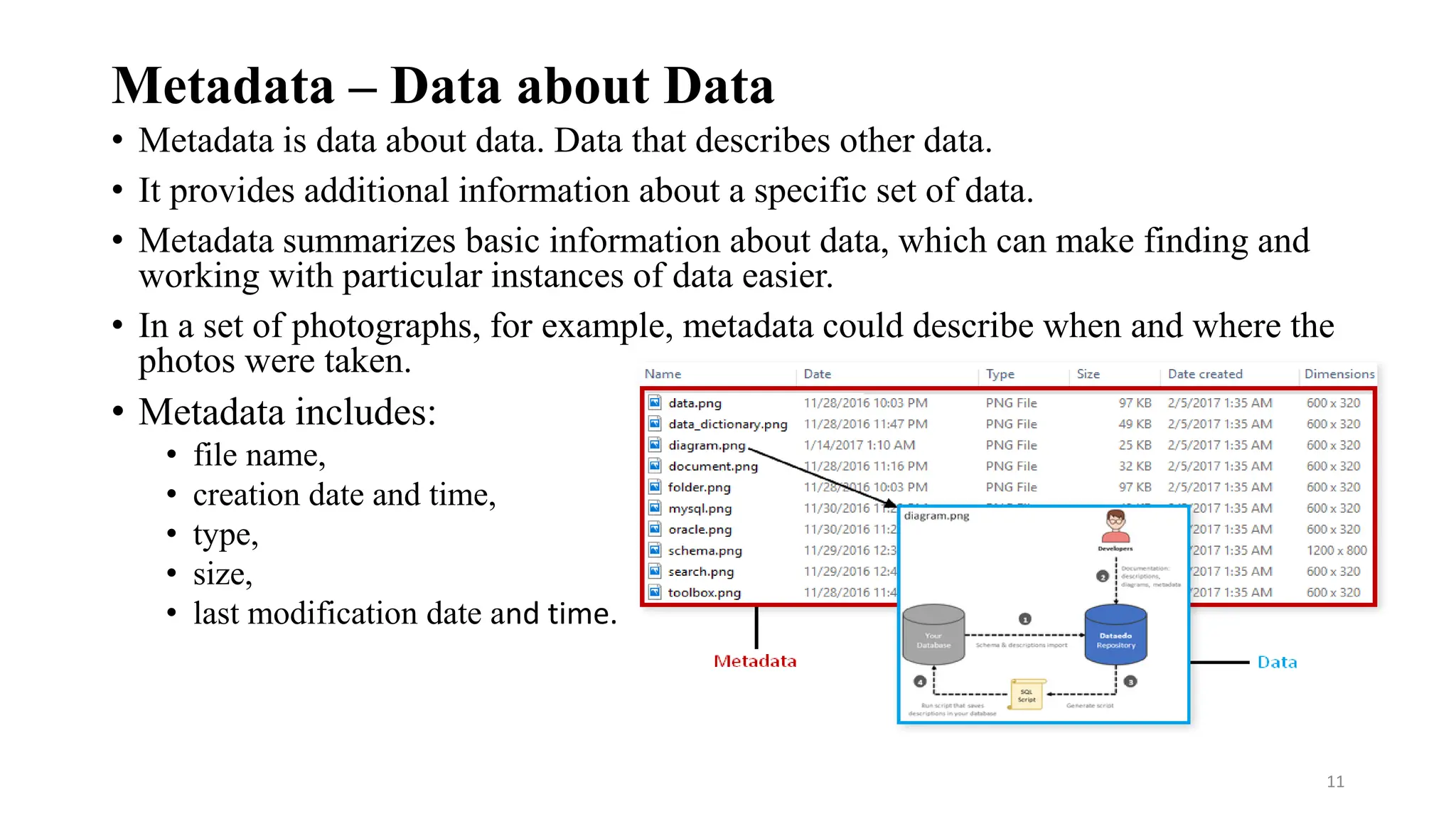
• Metadata is data about data. Data that describes other data.
• It provides additional information about a specific set of data.
• Metadata summarizes basic information about data, which can make finding and
working with particular instances of data easier.
• In a set of photographs, for example, metadata could describe when and where the
photos were taken.
• Metadata includes:
• file name,
• creation date and time,
• type,
• size,
• last modification date and time.
11
12.
What is Datascience
• Data science is now one of the most influential topics all around.
• Companies and enterprises are focusing a lot on gathering data science talent
further creating more viable roles in the data science industry.
• Data science is the field of study that combines domain expertise,
programming skills, and knowledge of mathematics and statistics to extract
knowledge and meaningful insights from data.
• Data science is a multi-disciplinary field that uses scientific methods,
processes, algorithms, and systems to extract knowledge and insights from
structured, semi-structured and unstructured data.
12
13.
What is DataScience
• Data Science defined as the extraction of actionable knowledge directly from
the data through the process of discovery, hypothesis, and analytical
hypotheses analysis.
• At its core, data science involves using automated methods to analyze
massive amounts of data (Big Data) and to extract knowledge from them.
• The purpose of data science is to solve scientific and business problems
by extracting knowledge from data
13
14.
What is DataScientist
• A data scientist (is a job title) is a person engaging in a systematic
activity to acquire knowledge from data.
• In a more restricted sense, a data scientist may refer to an individual who
uses the scientific method on existing data.
• A data scientist is a scientific professional who process large amount
of data to discover insights
• Data Scientists perform research toward a more comprehensive
understanding of products, systems, or nature, including physical,
mathematical and social realms.
14
15.
Roles of aData Scientist
• Advance the skills of analyzing large amounts of data, data mining,
programming and communication skills.
• a data scientist most likely explore and examine data from multiple disparate
sources.
• The processed and filtered data are handed to them which are then fed to various
analytics programs and machine learning with statistical methods to generate
data which will soon be used in predictive analysis and other fields
• Explore for more cryptic patterns to procure proper insights.
• Communicate findings to both business and IT leaders in a way that can influence
how an organization approaches a business challenge.
15
16.
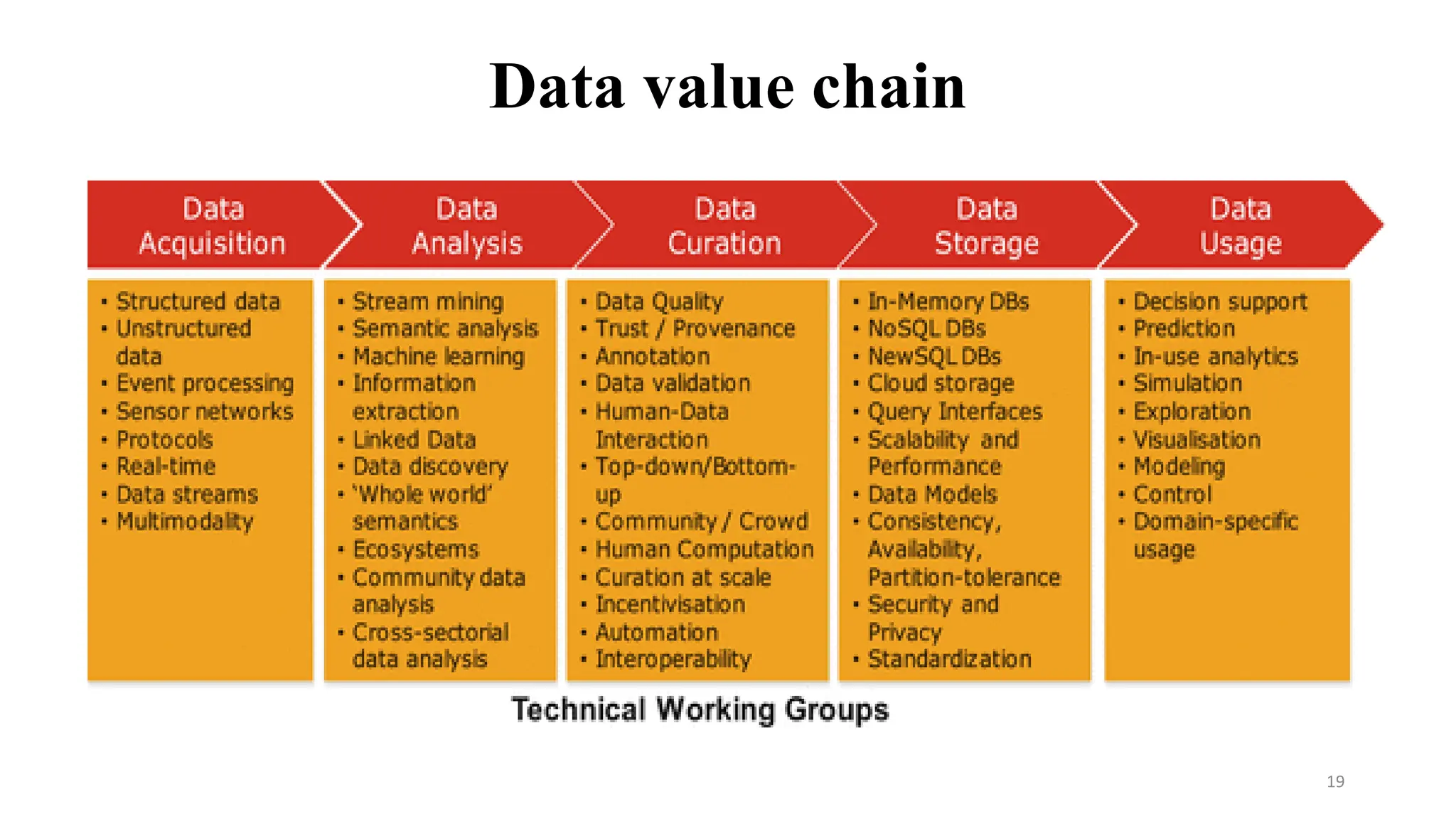
Data value chain
•The Data Value Chain is introduced to describe the information flow
within a big data system as a series of steps needed to generate value and
useful insights from data.
• The Big Data Value Chain identifies the following key high-level activities:
• Data acquisition, data analysis, data curation, data storage, data usage
• Data acquisition:
• is the process of digitizing data from the world around us so it can be displayed,
analyzed, and stored in a computer.
• It is the processes for bringing data that has been created by a source outside the
organization, into the organization, for production use.
• It is the process of gathering, filtering, and cleaning data before it is put in a data
warehouse or any other storage solution on which data analysis can be carried out.
16
17.
Data value chain
•Data analysis:
• Data from various sources is gathered, reviewed, and then
analyzed to form some sort of finding or conclusion.
• It is concerned with making the raw data acquired amenable
(open and responsive) to use in decision-making as well as
domain-specific usage.
• It is the process of evaluating data using analytical and logical
reasoning to examine each component of the data provided.
17
18.
Data value chain
•Data Curation:
• It is about managing data throughout its lifecycle to ensure it meets the necessary data
quality requirements for its effective usage.
• Data curation processes can be categorized into different activities such as Collecting,
organizing, cleaning, transformation, validation, and preservation.
• Data curators manage the data through various stages and make the data usable for data
analysts and scientists.
• Data storage:
• It is defined as a way of keeping information in the memory storage for use by a
computer. An example of data storage is a folder for storing Microsoft Word documents.
• Data usage:
• It is the amount of data (things like images, movies, photos, videos, and other files) that
you send, receive, download and/or upload.
• Data usage in business decision-making can enhance competitiveness through the
reduction of costs, increased added value, or any other parameter that can be measured
against existing performance criteria.
18
Basic concepts ofbig data
What is Big Data ? (Big refers to Big size, Big complexity)
• Big data is the term for a collection of data sets so large and complex
that it becomes difficult to process using on-hand database management
tools or traditional data processing applications.
• In this context, a “large dataset” means a dataset too large to reasonably
process or store with traditional tooling or on a single computer.
• Big Data is data whose scale, diversity, and complexity require new
architecture, techniques, algorithms, and analytics to manage it and extract
value and hidden knowledge from it…
• Big Data is analyzed for knowledge and insights that lead to better decisions.
20
21.
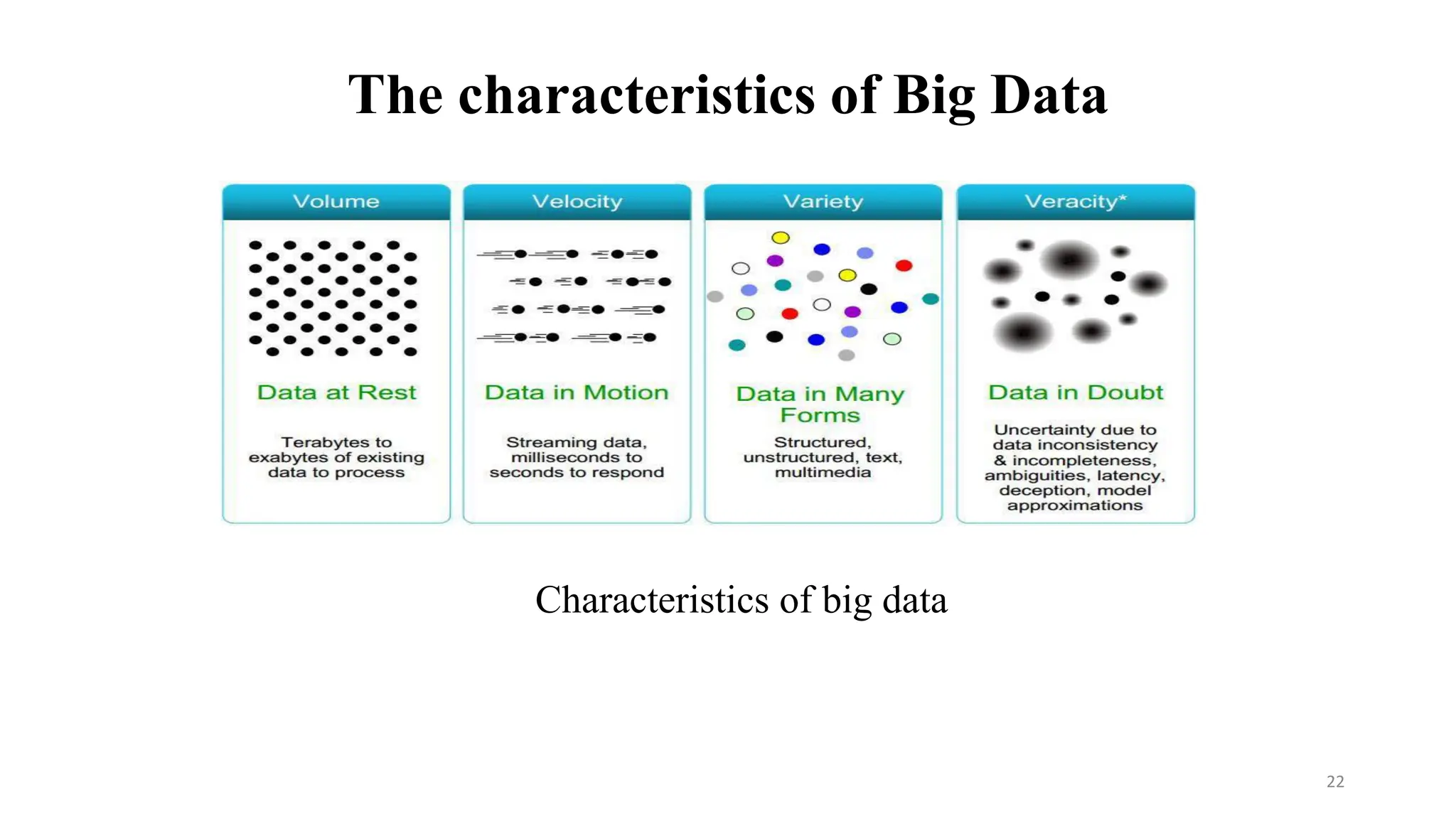
The characteristics ofBig Data
• Big data is characterized by 3V and more:
• Volume: large amounts of data Zeta bytes (ZB)/Massive datasets
• A zeta byte is a trillion gigabytes (GB) or a billion terabytes
• Velocity: Data is live streaming or in motion
• velocity is the rate at which data arrives at the enterprise and is
processed or well understood
• Variety: data comes in many different forms from diverse sources
• trying to capture all of the data that pertains to our decision-making
process.
• Veracity: can we trust the data? How accurate is it? etc.
• Veracity refers to the quality or trustworthiness of the data
21
Clustered Computing
• “Computercluster” basically refers to a set of connected computer
working together.
• The cluster represents one system and the objective is to improve
performance.
• So, when this cluster of computers works to perform some tasks and gives
an impression of only a single entity, it is called “cluster computing”.
• Because of the qualities of big data, individual computers are often
inadequate for handling the data at most stages.
• To better address the high storage and computational needs of big data,
computer clusters are a better fit.
23
24.
Clustered Computing
• Bigdata clustering software combines the resources of many smaller
machines, seeking to provide a number of benefits:
• Resource Pooling:
• Combining the available storage space to hold data is a clear benefit, but
CPU and memory pooling are also extremely important.
• Processing large datasets requires large amounts of all three of these
resources.
24
25.
Clustered Computing
• HighAvailability:
• In computing, the term availability is used to describe the period of time
when a service is available, as well as the time required by a system to
respond to a request made by a user.
• High availability is a quality of a system or component that assures a high
level of operational performance for a given period of time.
• Clusters can provide varying levels of fault tolerance and availability
guarantees to prevent hardware or software failures from affecting access to
data and processing. This becomes increasingly important as we continue to
emphasize the importance of real-time analytics.
• Easy Scalability:
• Clusters make it easy to scale horizontally by adding additional machines to the
group. This means the system can react to changes in resource requirements
without expanding the physical resources on a machine.
25
26.
Hadoop and itsEcosystem
• Hadoop is an open-source software framework intended to make
interaction with big data easier.
• It is used for distributed storage and distributed processing of large
datasets across clusters of computers using simple programming models.
• Hadoop is a distributed data processing and management system.
• Hadoop is used by companies (Facebook, Twitter, LinkedIn, eBay and
Amazon) with very large volumes of data to process.
26
27.
Hadoop and itsEcosystem
• The four key characteristics of Hadoop are:
• Economical: Its systems are highly economical as ordinary computers can
be used for data processing.
• Reliable: It is reliable as it stores copies of the data on different machines
and is resistant to hardware failure.
• Scalable: It is easily scalable both, horizontally and vertically. A few extra
nodes help in scaling up the framework.
• it is easy to add new hardware
• Flexible: It is flexible and you can store as much structured and
unstructured data as you need to and decide to use them later.
27
28.
Hadoop and itsEcosystem
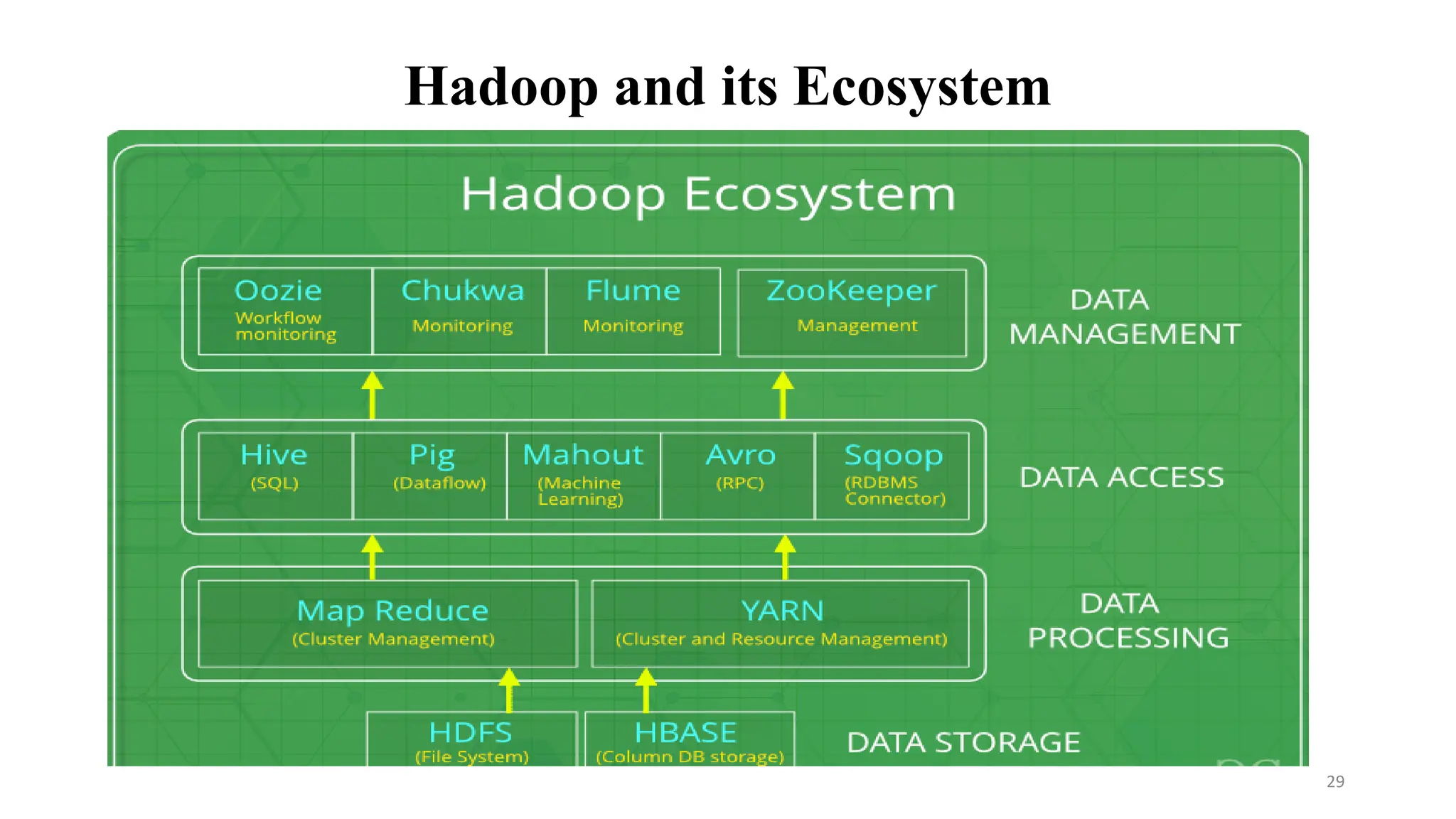
• Hadoop has an ecosystem that has evolved from its four core components:
data management, data access, data processing, and data storage.
• It is continuously growing to meet the needs of Big Data.
• It comprises the following components and many others:
• HDFS: Hadoop Distributed File System
• YARN: Yet Another Resource Negotiator (Cluster membership and resource allocation )
• MapReduce: Programming based Data Processing
• Spark: In-Memory data processing
• PIG, HIVE: Query-based processing of data services
• HBase: NoSQL Database
• Mahout, Spark MLLib: Machine Learning algorithm libraries
• Solar, Lucene: Searching and Indexing
• Zookeeper: Managing cluster
• Oozie: Job Scheduling
28
Big Data LifeCycle with Hadoop
• Ingesting data into the system:
• The first stage of Big Data processing is Ingest.
• The data is ingested or transferred to Hadoop from various sources such
as relational databases, systems, or local files.
• Processing the data in storage:
• In this stage, the data is stored and processed
• The data is stored in the distributed file system, HDFS, and the NoSQL
distributed data, HBase. Spark and MapReduce perform data processing.
• Computing and analyzing data:
• Here, the data is analyzed by processing frameworks
• Visualizing the results:
• The fourth stage is Access, In this stage, the analyzed data can be accessed by
users.
30































![Chapter 2 - Intro to Data Sciences[2].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-introtodatasciences2-230326001432-ec8e4032-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














