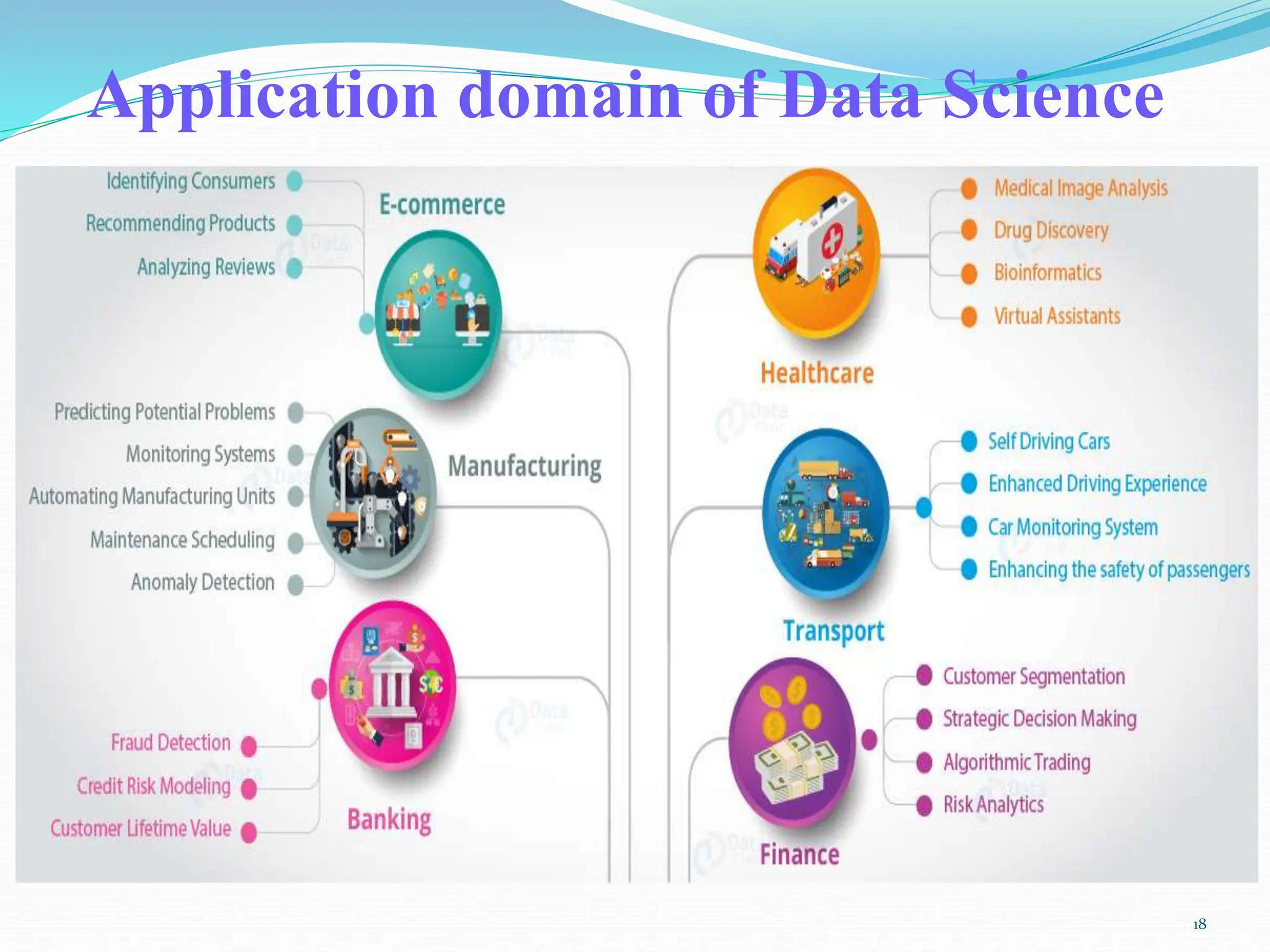
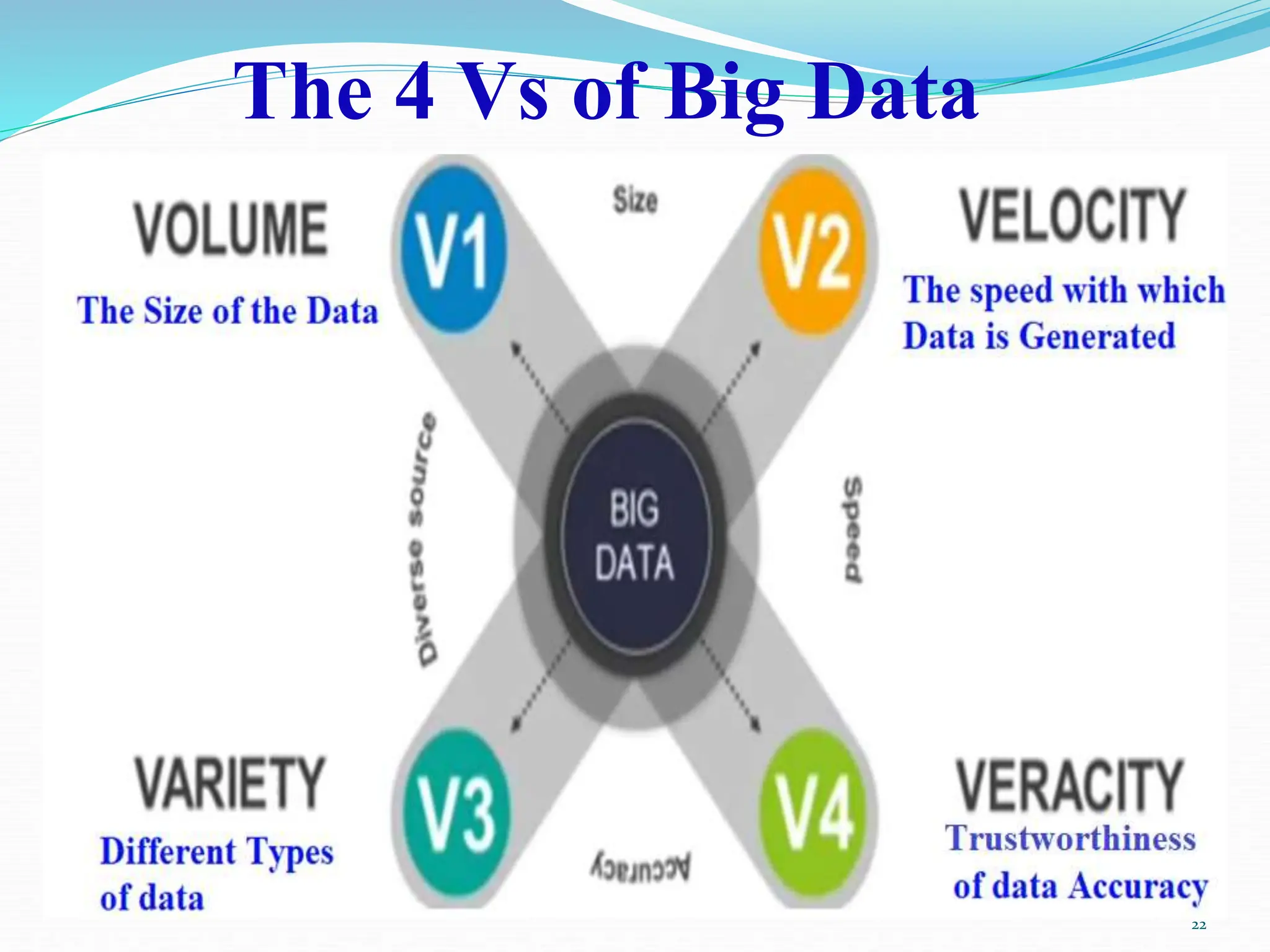
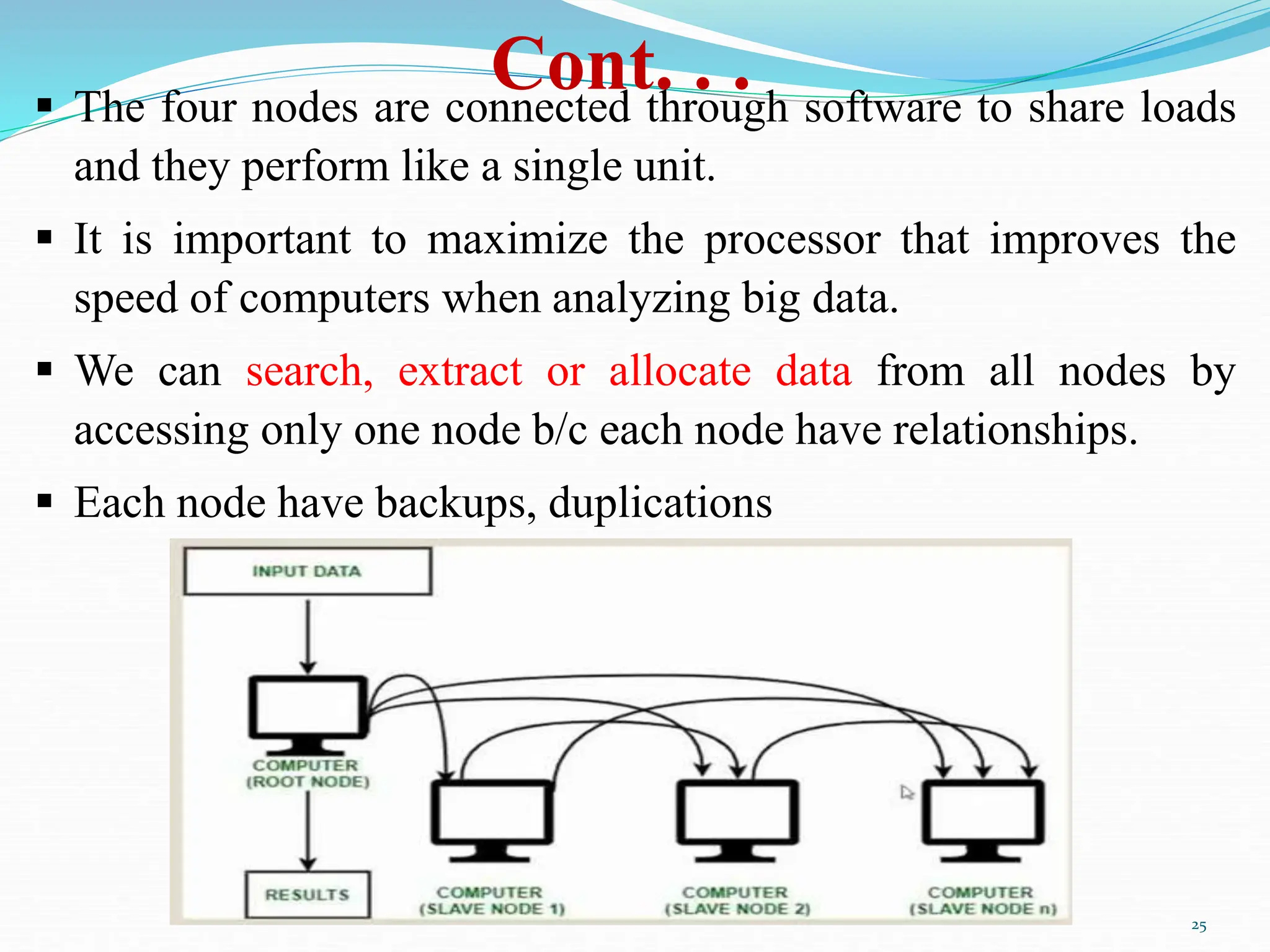
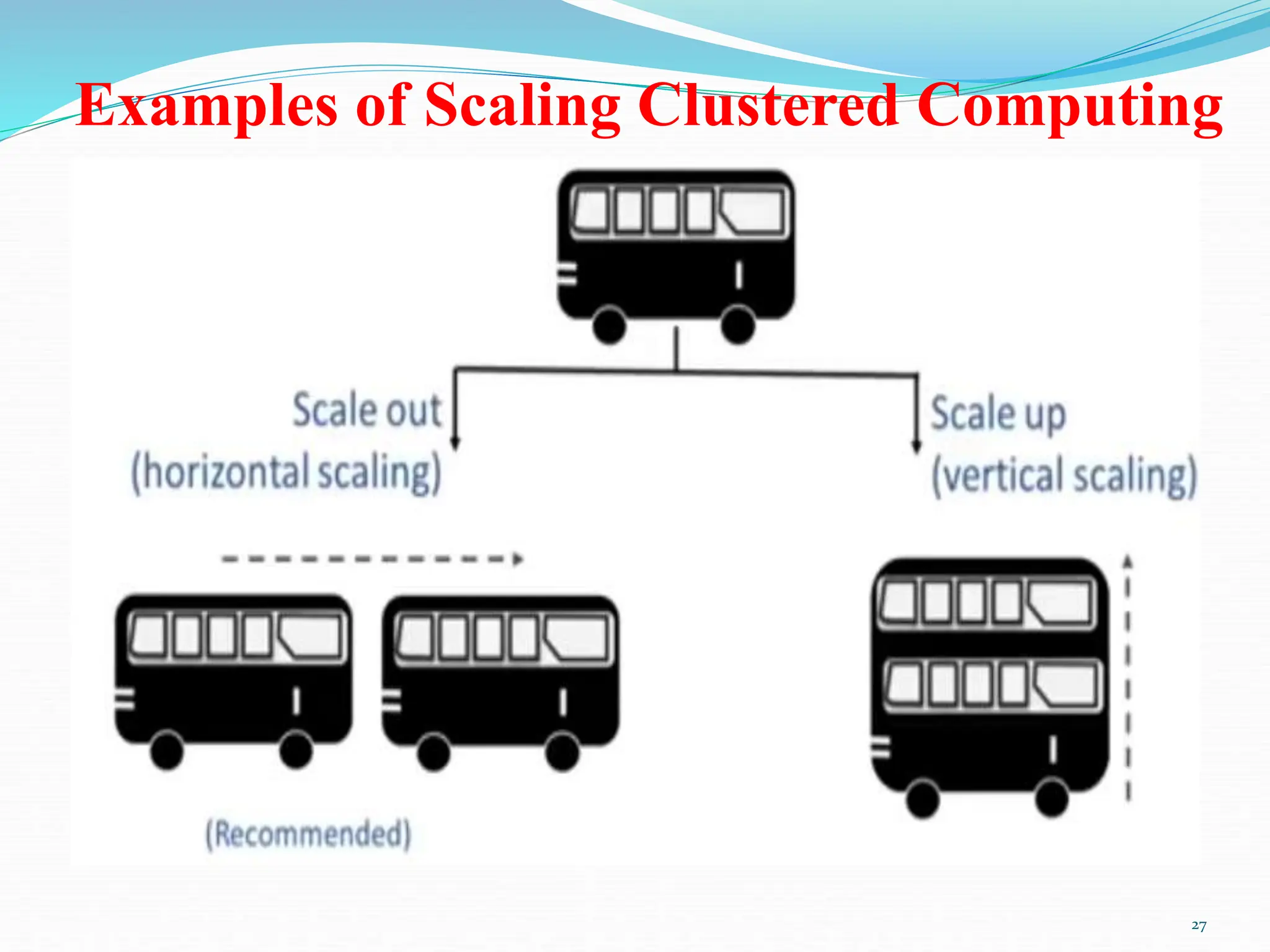
Chapter two of the document provides an overview of data science, discussing its definition, importance, and the roles of data scientists. It details the data processing cycle, data types, and the data value chain, emphasizing the concepts of big data and clustered computing. Additionally, the chapter highlights Hadoop and its ecosystem as essential tools for managing and analyzing big data.

































![Chapter 2 - Intro to Data Sciences[2].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-introtodatasciences2-230326001432-ec8e4032-thumbnail.jpg?width=640&height=640&fit=bounds)






































