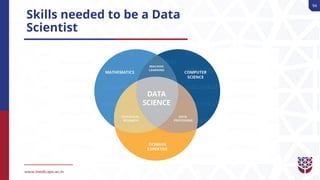
Introduction to Data Science, Definition and Description of Data Science, History and Development of Data Science, Terminologies Related with Data Science, Basic Framework and Architecture, Importance of Data Science in Today’s Business World, Primary Components of Data Science, Users of Data Science and its Hierarchy, Overview of Different Data Science Techniques






































































































![Introduction to Datascience [R20DS501].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontodatasciencer20ds501-251019152941-d61074d9-thumbnail.jpg?width=640&height=640&fit=bounds)



















































