Downloaded 20 times














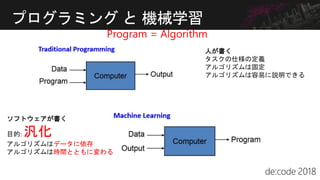







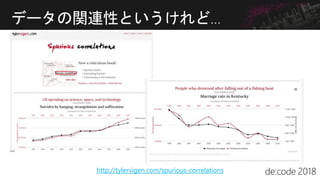





![Confusion Matrix for カルガモ
カルガモ が写っているの
に、
モデルは推定できなかっ
た
▶モデルの見逃し
あり[実
際]
なし[実
際]
あり[予
測]
XX XX
なし[予
測]
XX XX](https://image.slidesharecdn.com/gbusas8iq9kmuvgba7kz-signature-cb28296465397d212b2ef487934756469f82c6278f7350c08d764132987f81bb-poli-180710141838/85/Chalk-Talk-de-code-in-Osaka-43-320.jpg)
![Confusion Matrix for カルガモ
あり[実
際]
なし[実
際]
あり[予
測]
XX XX
なし[予
測]
XX XX
カルガモ でないもの
に、
カルガモ と推定
▶モデルの過検知?](https://image.slidesharecdn.com/gbusas8iq9kmuvgba7kz-signature-cb28296465397d212b2ef487934756469f82c6278f7350c08d764132987f81bb-poli-180710141838/85/Chalk-Talk-de-code-in-Osaka-44-320.jpg)
![混同行列 (Confusion Matrix)
あり [実際] なし [実際]
あり [予測] 14 0
なし [予測] 2 9
なし と 予測(緑線の下)
実際はあり (緑線の下の赤2
つ)
▶モデルの見逃し](https://image.slidesharecdn.com/gbusas8iq9kmuvgba7kz-signature-cb28296465397d212b2ef487934756469f82c6278f7350c08d764132987f81bb-poli-180710141838/85/Chalk-Talk-de-code-in-Osaka-45-320.jpg)





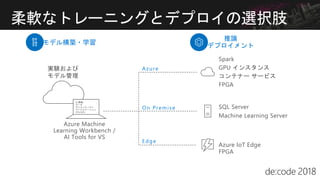
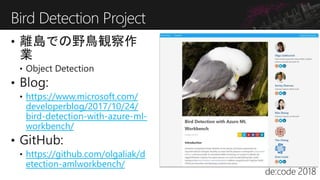
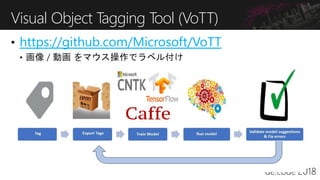
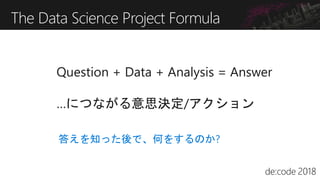
機械学習を実プロジェクトで試そうという方は多いと思います。ご存じの通り、実際には多くの失敗プロジェクトもあり、そこには多くの学びがあります。また、そもそも機械学習のプロジェクトの現場がよくわからないという方も多いのではないでしょうか? このChalkTalkは、経験はなくてもAI/機械学習でやってみたいこと(アイデア、意思)がある人を対象として、どのように機械学習のプロジェクトの成功率を上げるのかを話し合います。経験が無いわけですから、どんな発言も受け入れましょう!




















![[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~](https://cdn.slidesharecdn.com/ss_thumbnails/20181117devfestasapporoazureaipublic-181119035506-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築](https://cdn.slidesharecdn.com/ss_thumbnails/20180215developerssummitmicrosoftaiplatform-180218215607-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第50回 Machine Learning 15minutes! Broadcast] Azure Machine Learning - Ignite ...](https://cdn.slidesharecdn.com/ss_thumbnails/20201205ml15minazuremlignite-201205101214-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Japan Tech summit 2017] MAI 003](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai003-171116035458-thumbnail.jpg?width=640&height=640&fit=bounds)



























