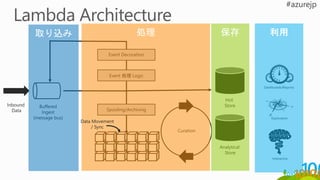
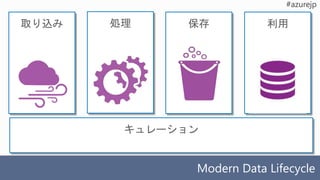
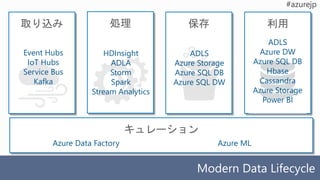
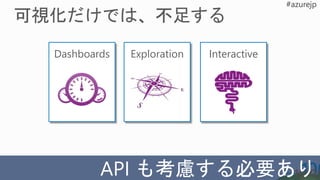
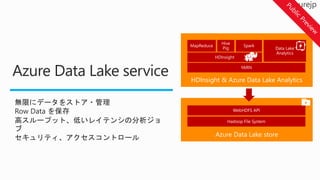
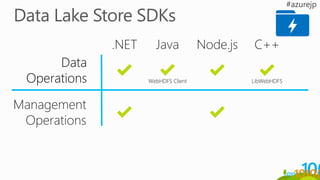
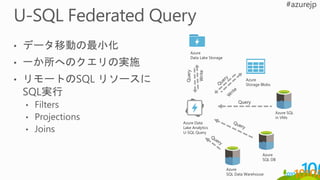
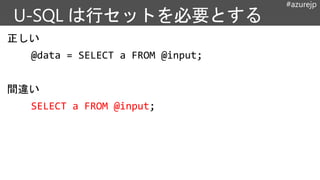
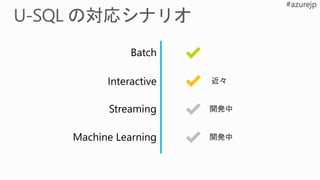
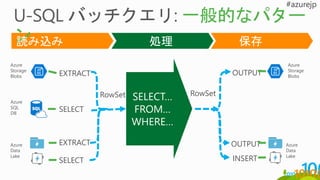
取り込み
Modern Data Lifecycle
処理保存 利用
Event Hubs
IoT Hubs
Service Bus
Kafka
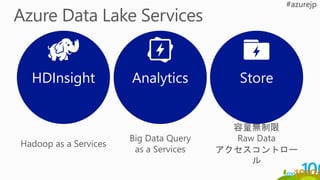
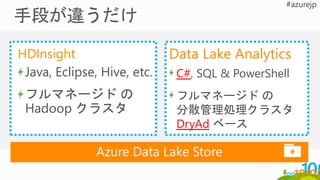
HDInsight
ADLA
Storm
Spark
Stream Analytics
ADLS
Azure Storage
Azure SQL DB
Azure SQL DW
ADLS
Azure DW
Azure SQL DB
Hbase
Cassandra
Azure Storage
Power BI
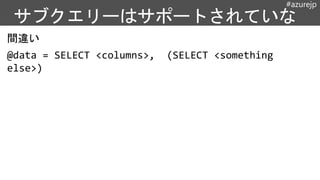
キュレーション
Azure Data Factory Azure ML
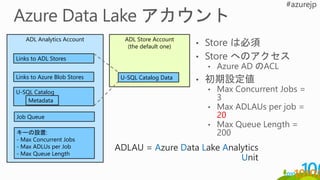
ADL Analytics Account
Linksto ADL Stores
ADL Store Account
(the default one)
Job Queue
キーの設置:
- Max Concurrent Jobs
- Max ADLUs per Job
- Max Queue Length
Links to Azure Blob Stores
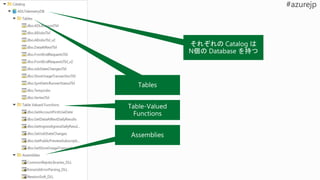
U-SQL Catalog
Metadata
U-SQL Catalog Data
ADLAU = Azure Data Lake Analytics
Unit
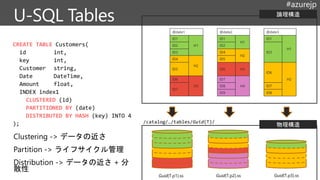
14.
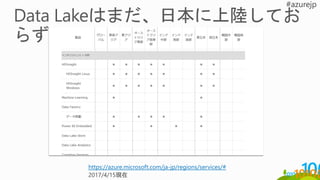
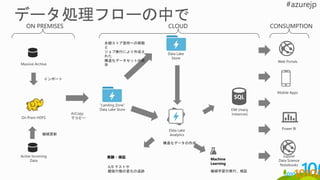
ON PREMISES CLOUD
MassiveArchive
On Prem HDFS
インポート
Active Incoming
Data
継続更新
“Landing Zone”
Data Lake Store
AzCopy
でコピー
Data Lake
Store
Data Lake
Analytics
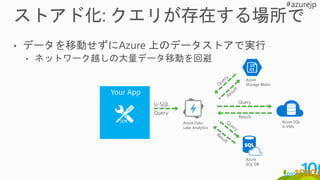
永続ストア箇所への移動
と
ジョブ実行により作成さ
れた
構造化データセットの保
存
DW (many
instances)
構造化データの作成。
CONSUMPTION
Machine
Learning
機械学習の実行、検証
Web Portals
Mobile Apps
Power BI
実験・検証
A/B テストや
顧客行動の変化の追跡
Jupyter
Data Science
Notebooks
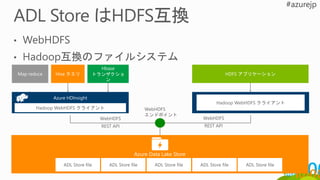
Map reduce
Hbase
トランザクショ
ン
HDFS アプリケーションHiveクエリ
Azure HDInsight
Hadoop WebHDFS クライアント
Hadoop WebHDFS クライアント
WebHDFS
エンドポイント
WebHDFS
REST API
WebHDFS
REST API
ADL Store file ADL Store file ADL Store file ADL Store fileADL Store file
Azure Data Lake Store
17.
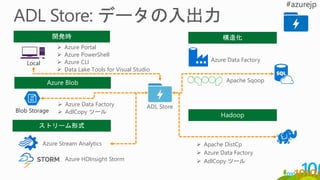
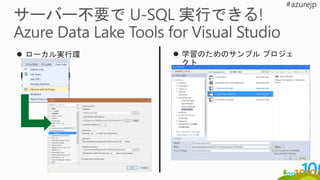
Local
ADL Store
AzurePortal
Azure PowerShell
Azure CLI
Data Lake Tools for Visual Studio
Azure Data Factory
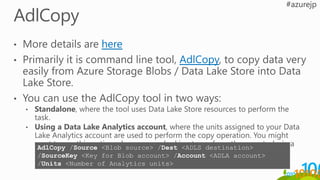
AdlCopy ツール
Azure Stream Analytics
Azure HDInsight Storm
Azure Data Factory
Apache Sqoop
Apache DistCp
Azure Data Factory
AdlCopy ツール
Azure Data LakeStore file
…Block 1 Block 2 Block 2
Backend Storage
Data node Data node Data node Data node Data nodeData node
Block Block Block Block Block Block
20.
AdlCopy /Source <Blobsource> /Dest <ADLS destination>
/SourceKey <Key for Blob account> /Account <ADLA account>
/Units <Number of Analytics units>
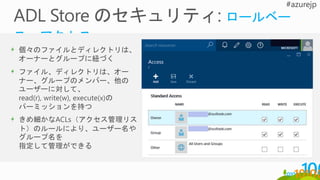
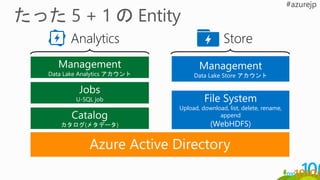
Management
Data Lake Analyticsアカウント
Jobs
U-SQL job
Catalog
カタログ(メタデータ)
Management
Data Lake Store アカウント
File System
Upload, download, list, delete, rename,
append
(WebHDFS)
Analytics Store
Azure Active Directory
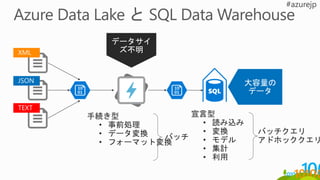
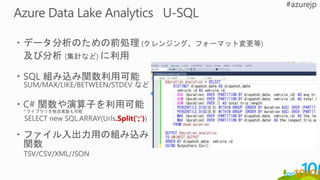
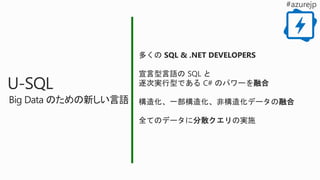
多くの SQL &.NET DEVELOPERS
宣言型言語の SQL と
逐次実行型である C# のパワーを融合
構造化、一部構造化、非構造化データの融合
全てのデータに分散クエリの実施
U-SQL
Big Data のための新しい言語
40.
#azurejp
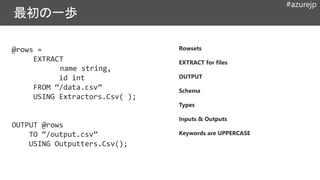
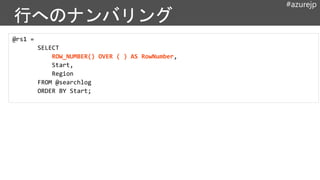
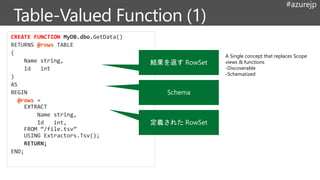
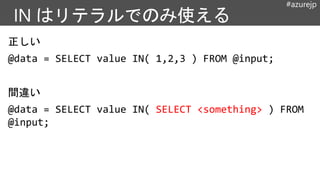
@rows =
EXTRACT
name string,
idint
FROM “/data.csv”
USING Extractors.Csv( );
OUTPUT @rows
TO “/output.csv”
USING Outputters.Csv();
Rowsets
EXTRACT for files
OUTPUT
Schema
Types
Inputs & Outputs
Keywords are UPPERCASE
41.
#azurejp
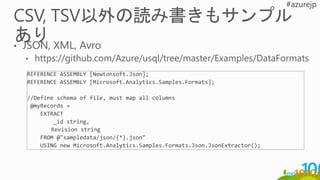
REFERENCE ASSEMBLY WebLogExtASM;
@rs=
EXTRACT
UserID string,
Start DateTime,
End DateTime,
Region string,
SitesVisited string,
PagesVisited string
FROM "swebhdfs://Logs/WebLogRecords.csv"
USING WebLogExtractor ();
@result = SELECT UserID,
(End.Subtract(Start)).TotalSeconds AS Duration
FROM @rs ORDER BY Duration DESC FETCH 10;
OUTPUT @result TO "swebhdfs://Logs/Results/top10.txt"
USING Outputter.Tsv();
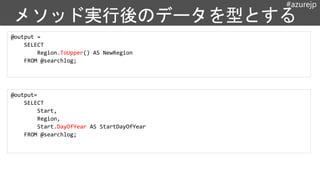
• 型定義は C# の型定義と同じ
• データをファイルから抽出・読
み込み
するときに、スキーマを定義
Data Lake Store のファイ
ル独自形式を解析するカスタム
関数
C# の関数
行セット:
(中間テーブ
ルの概念に近
い)
TSV形式で読み取る関数
42.
DECLARE @endDate DateTime= DateTime.Now;
DECLARE @startDate DateTime = @endDate.AddDays(-7);
@orders =
EXTRACT
OrderId int,
Customer string,
Date DateTime,
Amount float
FROM "/input/orders.txt"
USING Extractors.Tsv();
@orders = SELECT * FROM @orders
WHERE Date >= startDate AND Date <= endDate;
@orders = SELECT * FROM @orders
WHERE Customer.Contains(“Contoso”);
OUTPUT @orders
TO "/output/output.txt"
USING Outputters.Tsv();
U-SQL
Basics
(1) DECLARE C# の式で変数宣言
(2) EXTRACT ファイル読み込み時に
スキーマを決定し、結果を RowSet
に
(3) RowSet 式を使ってデータを再定
義
(4) OUTPUT データをファイルへ出
力
1
2
3
4
43.
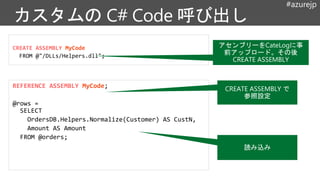
CREATE ASSEMBLY OrdersDB.SampleDotNetCode
FROM@"/Assemblies/Helpers.dll";
REFERENCE ASSEMBLY OrdersDB.Helpers;
@rows =
SELECT
OrdersDB.Helpers.Normalize(Customer) AS Customer,
Amount AS Amount
FROM @orders;
@rows =
PROCESS @rows
PRODUCE OrderId string, FraudDetectionScore double
USING new OrdersDB.Detection.FraudAnalyzer();
OUTPUT @rows
TO "/output/output.dat"
USING OrdersDB.CustomOutputter();
U-SQL
.NET Code 利用
(1) CREATE ASSEMBLY アセンブ
リーをU-SQL Catalog へ登録
(2) REFERENCE ASSEMBLY アセン
ブリーへの参照宣言
(3) U-SQL 式の中で、C# メソッドの
呼び出し
(4) PROCESS User Defined Operator
を使って、行ごとの処理を実行
(5) OUTPUT 独自のデータ形式で出
力
1
2
3
4
5
45.
#azurejp
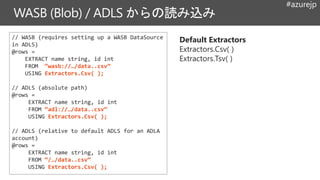
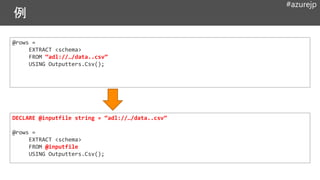
// WASB (requiressetting up a WASB DataSource
in ADLS)
@rows =
EXTRACT name string, id int
FROM “wasb://…/data..csv”
USING Extractors.Csv( );
// ADLS (absolute path)
@rows =
EXTRACT name string, id int
FROM “adl://…/data..csv”
USING Extractors.Csv( );
// ADLS (relative to default ADLS for an ADLA
account)
@rows =
EXTRACT name string, id int
FROM “/…/data..csv”
USING Extractors.Csv( );
Default Extractors
Extractors.Csv( )
Extractors.Tsv( )
#azurejp
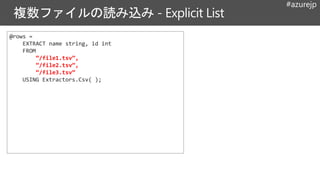
@rows =
EXTRACT namestring, id int
FROM “adl://…/data..csv”
USING Extractors.Csv();
OUTPUT @rows
TO “/data.tsv”
USING Outputters.Csv();
Default Outputters
Outputters.Csv( )
Outputters.Tsv( )
48.
#azurejp
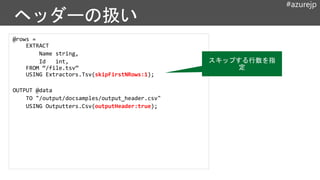
@rows =
EXTRACT
Name string,
Idint,
FROM “/file.tsv”
USING Extractors.Tsv(skipFirstNRows:1);
OUTPUT @data
TO "/output/docsamples/output_header.csv"
USING Outputters.Csv(outputHeader:true);
スキップする行数を指
定
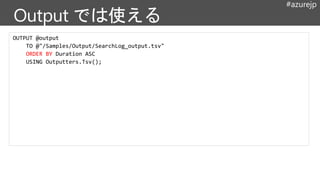
#azurejp
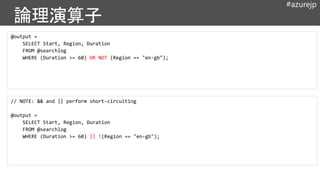
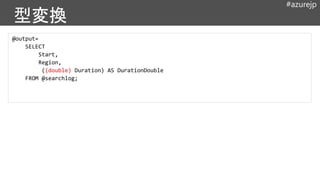
@output =
SELECT
Region,
COUNT() ASNumSessions,
SUM(Duration) AS TotalDuration,
AVG(Duration) AS AvgDwellTtime,
MAX(Duration) AS MaxDuration,
MIN(Duration) AS MinDuration
FROM @searchlog
GROUP BY Region;
67.
#azurejp
// NO GROUPBY
@output =
SELECT
SUM(Duration) AS TotalDuration
FROM @searchlog;
// WITH GROUP BY
@output =
SELECT
Region,
SUM(Duration) AS TotalDuration
FROM searchlog
GROUP BY Region;
68.
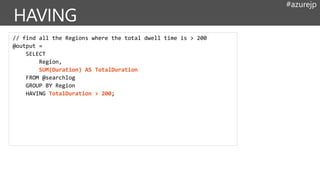
#azurejp
// find allthe Regions where the total dwell time is > 200
@output =
SELECT
Region,
SUM(Duration) AS TotalDuration
FROM @searchlog
GROUP BY Region
HAVING TotalDuration > 200;
69.
#azurejp
// Option 1
@output=
SELECT
Region,
SUM(Duration) AS TotalDuration
FROM @searchlog
GROUP BY Region;
@output2 =
SELECT *
FROM @output
WHERE TotalDuration > 200;
// Option 2
@output =
SELECT
Region,
SUM(Duration) AS TotalDuration
FROM @searchlog
GROUP BY Region
HAVING SUM(Duration) > 200;
71.
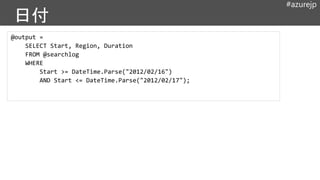
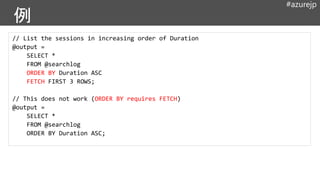
#azurejp
// List thesessions in increasing order of Duration
@output =
SELECT *
FROM @searchlog
ORDER BY Duration ASC
FETCH FIRST 3 ROWS;
// This does not work (ORDER BY requires FETCH)
@output =
SELECT *
FROM @searchlog
ORDER BY Duration ASC;
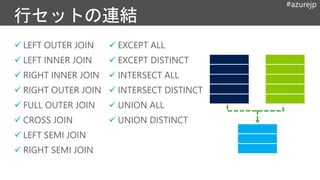
#azurejp
LEFT OUTERJOIN
LEFT INNER JOIN
RIGHT INNER JOIN
RIGHT OUTER JOIN
FULL OUTER JOIN
CROSS JOIN
LEFT SEMI JOIN
RIGHT SEMI JOIN
EXCEPT ALL
EXCEPT DISTINCT
INTERSECT ALL
INTERSECT DISTINCT
UNION ALL
UNION DISTINCT
#azurejp
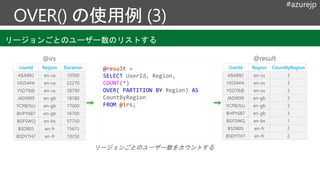
UserId Region Duration
A$A892en-us 10500
HG54#A en-us 22270
YSD78@ en-us 38790
JADI899 en-gb 18780
YCPB(%U en-gb 17000
BHPY687 en-gb 16700
BGFSWQ en-bs 57750
BSD805 en-fr 15675
BSDYTH7 en-fr 10250
UserId Region Rank
YSD78@ en-us 1
HG54#A en-us 2
JADI899 en-gb 1
YCPB(%U en-gb 2
BGFSWQ en-bs 1
BSD805 en-fr 1
BSDYTH7 en-fr 2
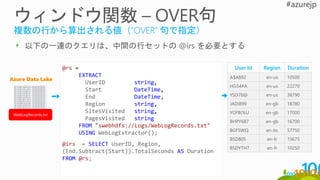
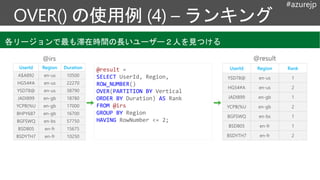
@irs @result
@result =
SELECT UserId, Region,
ROW_NUMBER()
OVER(PARTITION BY Vertical
ORDER BY Duration) AS Rank
FROM @irs
GROUP BY Region
HAVING RowNumber <= 2;
各リージョンで最も滞在時間の長いユーザー2人を見つける
83.
#azurejp
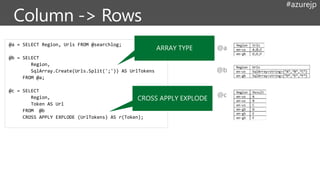
@a = SELECTRegion, Urls FROM @searchlog;
@b = SELECT
Region,
SqlArray.Create(Urls.Split(';')) AS UrlTokens
FROM @a;
@c = SELECT
Region,
Token AS Url
FROM @b
CROSS APPLY EXPLODE (UrlTokens) AS r(Token);
@a
@b
@c
CROSS APPLY EXPLODE
ARRAY TYPE
84.
#azurejp
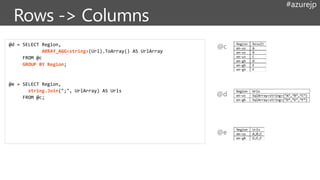
@d = SELECTRegion,
ARRAY_AGG<string>(Url).ToArray() AS UrlArray
FROM @c
GROUP BY Region;
@e = SELECT Region,
string.Join(";", UrlArray) AS Urls
FROM @c;
@c
@e
@d
#azurejp
CREATE FUNCTION MyDB.dbo.
RETURNS@rows TABLE
(
Name string,
Id int
)
AS
BEGIN
@rows =
EXTRACT
Name string,
Id int,
FROM “/file.tsv”
USING Extractors.Tsv();
RETURN;
END;
結果を返す RowSet
Schema
定義された RowSet
A Single concept that replaces Scope
views & functions
-Discoverable
-Schematized
USE DATABASE [AdventureWorksLT_ExternalDB];
CREATEEXTERNAL TABLE IF NOT EXISTS
dbo.CustomersExternal
(
CustomerID int?,
NameStyle bool,
Title string,
FirstName string,
MiddleName string,
LastName string,
Suffix string,
CompanyName string,
SalesPerson string,
EmailAddress string,
Phone string,
PasswordHash string,
PasswordSalt string,
Rowguid Guid,
ModifiedDate DateTime?
)
FROM AdventureWorksLT_DS LOCATION
"[SalesLT].[Customer]";
USE DATABASE
[AdventureWorksLT_ExternalDB];
@customers =
SELECT *
FROM dbo.CustomersExternal;
OUTPUT @customers
TO @"/SalesLT_Customer.csv"
USING Outputters.Csv();
External Table からの読み取り
112.
#azurejp
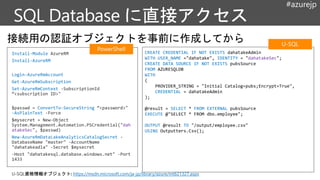
CREATE CREDENTIAL IFNOT EXISTS dahatakeAdmin
WITH USER_NAME ="dahatake", IDENTITY = "dahatakeSec";
CREATE DATA SOURCE IF NOT EXISTS pubsSource
FROM AZURESQLDB
WITH
(
PROVIDER_STRING = "Initial Catalog=pubs;Encrypt=True",
CREDENTIAL = dahatakeAdmin
);
@result = SELECT * FROM EXTERNAL pubsSource
EXECUTE @"SELECT * FROM dbo.employee";
OUTPUT @result TO "/output/employee.csv"
USING Outputters.Csv();
Install-Module AzureRM
Install-AzureRM
Login-AzureRmAccount
Get-AzureRmSubscription
Set-AzureRmContext -SubscriptionId
“<subscription ID>"
$passwd = ConvertTo-SecureString “<password>"
-AsPlainText -Force
$mysecret = New-Object
System.Management.Automation.PSCredential("dah
atakeSec", $passwd)
New-AzureRmDataLakeAnalyticsCatalogSecret -
DatabaseName "master" -AccountName
"dahatakeadla" -Secret $mysecret
-Host "dahatakesql.database.windows.net" -Port
1433
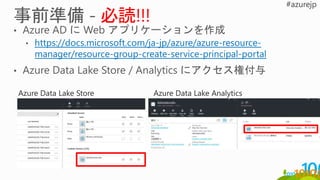
資格情報オブジェクト: https://msdn.microsoft.com/ja-jp/library/azure/mt621327.aspx
115.
Input Data
(K, A,B, C, D)
REDUCE ON K
Partition
K0
Partition
K1
Partition
K2
REDUCER
Python/R
REDUCER
Python/R
REDUCER
Python/R
Output for
K0
Output for
K0
Output for
K0
Extensions の追加
REFERENCE ASSEMBLY [ExtPython]
REFERENCE ASSEMBLY [ExtR]
特別な Reducers によって Python or R code
を分散実行
• Extension.Python.Reducer
• Extension.R.Reducer
Standard DataFrame を Reducerの入出力とし
て使える
NOTE: Reducer は、Aggregate を含んでいな
い
116.
REFERENCE ASSEMBLY [ExtPython];
DECLARE@myScript = @"
def get_mentions(tweet):
return ';'.join( ( w[1:] for w in tweet.split() if w[0]=='@' ) )
def usqlml_main(df):
del df['time']
del df['author']
df['mentions'] = df.tweet.apply(get_mentions)
del df['tweet']
return df
";
@t =
SELECT * FROM
(VALUES
("D1","T1","A1","@foo Hello World @bar"),
("D2","T2","A2","@baz Hello World @beer")
) AS
D( date, time, author, tweet );
@m =
REDUCE @t ON date
PRODUCE date string, mentions string
USING new Extension.Python.Reducer(pyScript:@myScript);
Python Extensions
U-SQLを並列分散処理に使用する
Python code を多くのノード上で実
行
NumPy、Pandasのような、Python
の標準ライブラリが利用できる
117.
REFERENCE ASSEMBLY ImageCommon;
REFERENCEASSEMBLY FaceSdk;
REFERENCE ASSEMBLY ImageEmotion;
REFERENCE ASSEMBLY ImageTagging;
REFERENCE ASSEMBLY ImageOcr;
@imgs =
EXTRACT FileName string, ImgData byte[]
FROM @"/images/{FileName:*}.jpg"
USING new Cognition.Vision.ImageExtractor();
// Extract the number of objects on each image and tag them
@objects =
PROCESS @imgs
PRODUCE FileName,
NumObjects int,
Tags string
READONLY FileName
USING new Cognition.Vision.ImageTagger();
OUTPUT @objects
TO "/objects.tsv"
USING Outputters.Tsv();
Imaging
118.
REFERENCE ASSEMBLY [TextCommon];
REFERENCEASSEMBLY [TextSentiment];
REFERENCE ASSEMBLY [TextKeyPhrase];
@WarAndPeace =
EXTRACT No int,
Year string,
Book string, Chapter string,
Text string
FROM @"/usqlext/samples/cognition/war_and_peace.csv"
USING Extractors.Csv();
@sentiment =
PROCESS @WarAndPeace
PRODUCE No,
Year,
Book, Chapter,
Text,
Sentiment string,
Conf double
USING new Cognition.Text.SentimentAnalyzer(true);
OUTPUT @sentinment
TO "/sentiment.tsv"
USING Outputters.Tsv();
Text Analysis
119.
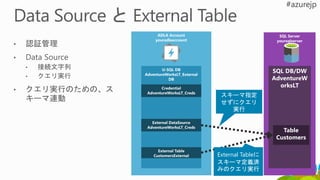
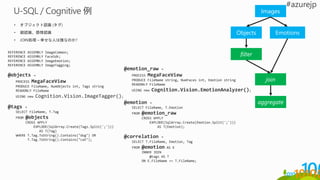
• オブジェクト認識 (タグ)
•顔認識、感情認識
• JOIN処理 – 幸せな人は誰なのか?
REFERENCE ASSEMBLY ImageCommon;
REFERENCE ASSEMBLY FaceSdk;
REFERENCE ASSEMBLY ImageEmotion;
REFERENCE ASSEMBLY ImageTagging;
@objects =
PROCESS MegaFaceView
PRODUCE FileName, NumObjects int, Tags string
READONLY FileName
USING new Cognition.Vision.ImageTagger();
@tags =
SELECT FileName, T.Tag
FROM @objects
CROSS APPLY
EXPLODE(SqlArray.Create(Tags.Split(';')))
AS T(Tag)
WHERE T.Tag.ToString().Contains("dog") OR
T.Tag.ToString().Contains("cat");
@emotion_raw =
PROCESS MegaFaceView
PRODUCE FileName string, NumFaces int, Emotion string
READONLY FileName
USING new Cognition.Vision.EmotionAnalyzer();
@emotion =
SELECT FileName, T.Emotion
FROM @emotion_raw
CROSS APPLY
EXPLODE(SqlArray.Create(Emotion.Split(';')))
AS T(Emotion);
@correlation =
SELECT T.FileName, Emotion, Tag
FROM @emotion AS E
INNER JOIN
@tags AS T
ON E.FileName == T.FileName;
Images
Objects Emotions
filter
join
aggregate
Job Front End
JobScheduler Compiler Service
Job Queue
Job Manager
U-SQL Catalog
YARN
Job 投入
Job 実行
U-SQL Runtime vertex 実行
141.
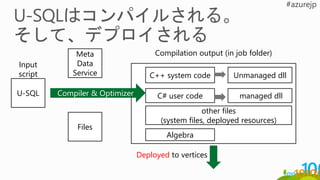
U-SQL C# usercode
C++ system code
Algebra
other files
(system files, deployed resources)
managed dll
Unmanaged dll
Input
script
Compilation output (in job folder)
Files
Meta
Data
Service
Deployed to vertices
Compiler & Optimizer
<><><><>
<><><><>
<><><><>
<><><><>
<><><><>
<><><><>
Extent 1
Region =“en-us”
<><><><>
<><><><>
<><><><>
<><><><>
<><><><>
<><><><>
Extent 2
Region = “en-gb”
<><><><>
<><><><>
<><><><>
<><><><>
<><><><>
<><><><>
Extent 3
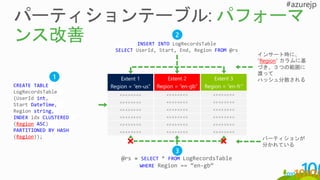
Region = “en-fr”CREATE TABLE
LogRecordsTable
(UserId int,
Start DateTime,
Region string,
INDEX idx CLUSTERED
(Region ASC)
PARTITIONED BY HASH
(Region));
インサート時に、
“Region” カラムに基
づき、3つの範囲に
渡って
ハッシュ分散される
INSERT INTO LogRecordsTable
SELECT UserId, Start, End, Region FROM @rs
パーティションが
分かれている
@rs = SELECT * FROM LogRecordsTable
WHERE Region == “en-gb”
1
2
3
150.
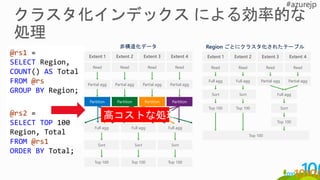
Full agg
Region ごとにクラスタ化されたテーブル
ReadRead Read Read
Full agg Full agg Partial agg Partial agg
Extent 1 Extent 2 Extent 3 Extent 4
Sort Sort
Top 100 Top 100 Sort
Top 100
Top 100
Read Read Read Read
非構造化データ
Partial agg Partial agg Partial agg Partial agg
Full agg Full agg Full agg
Sort Sort Sort
Top 100 Top 100 Top 100
Extent 1 Extent 2 Extent 3 Extent 4
Partition Partition Partition Partition
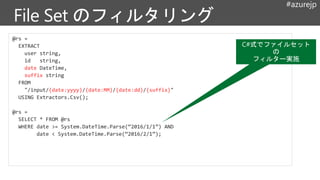
@rs1 =
SELECT Region,
COUNT() AS Total
FROM @rs
GROUP BY Region;
@rs2 =
SELECT TOP 100
Region, Total
FROM @rs1
ORDER BY Total;
高コストな処理























![#azurejp
DECLARE @a string = "Hello World";
DECLARE @b int = 2;
DECLARE @c dateTime = System.DateTime.Parse("1979/03/31");
DECLARE @d dateTime = DateTime.Now;
DECLARE @e Guid = System.Guid.Parse("BEF7A4E8-F583-4804-9711-7E608215EBA6");
DECLARE @f byte [] = new byte[] { 0, 1, 2, 3, 4};
@変数名 で定義](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-53-320.jpg)
















![#azurejp
[SUM = 207715]
UserId Region Duration
A$A892 en-us 10500
HG54#A en-us 22270
YSD78@ en-us 38790
JADI899 en-gb 18780
YCPB(%U en-gb 17000
BHPY687 en-gb 16700
BGFSWQ en-bs 57750
BSD805 en-fr 15675
BSDYTH7 en-fr 10250
UserId TotalDuration
A$A892 207715
HG54#A 207715
YSD78@ 207715
JADI899 207715
YCPB(%U 207715
BHPY687 207715
BGFSWQ 207715
BSD805 207715
BSDYTH7 207715
全行のウィンドウを通じて
期間をサマリーする
@result =
SELECT UserID,
SUM(Duration) OVER() AS TotalDuration
FROM @irs;
@irs @result
ユーザーIDと、ウェブサイトにおける全ユーザーの滞在時間の総計をリストする](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-78-320.jpg)















![USE DATABASE [AdventureWorksLT_ExternalDB];
CREATE DATA SOURCE IF NOT EXISTS AdventureWorksLT_DS
FROM AZURESQLDB WITH
( PROVIDER_STRING =
"Database=AdventureWorksLT;Trusted_Connection=False;Encrypt=True",
CREDENTIAL = AdventureWorksLT_Creds,
REMOTABLE_TYPES = (bool, byte, sbyte, short, ushort, int, uint, long, ulong,
decimal, float, double, string, DateTime)
);
Remotable types](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-109-320.jpg)
![USE DATABASE [AdventureWorksLT_ExternalDB];
@customers =
SELECT *
FROM EXTERNAL AdventureWorksLT_DS LOCATION "[SalesLT].[Customer]";
OUTPUT @customers
TO @"/SalesLT_Customer.csv"
USING Outputters.Csv();](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-110-320.jpg)
![USE DATABASE [AdventureWorksLT_ExternalDB];
CREATE EXTERNAL TABLE IF NOT EXISTS
dbo.CustomersExternal
(
CustomerID int?,
NameStyle bool,
Title string,
FirstName string,
MiddleName string,
LastName string,
Suffix string,
CompanyName string,
SalesPerson string,
EmailAddress string,
Phone string,
PasswordHash string,
PasswordSalt string,
Rowguid Guid,
ModifiedDate DateTime?
)
FROM AdventureWorksLT_DS LOCATION
"[SalesLT].[Customer]";
USE DATABASE
[AdventureWorksLT_ExternalDB];
@customers =
SELECT *
FROM dbo.CustomersExternal;
OUTPUT @customers
TO @"/SalesLT_Customer.csv"
USING Outputters.Csv();
External Table からの読み取り](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-111-320.jpg)


![Input Data
(K, A, B, C, D)
REDUCE ON K
Partition
K0
Partition
K1
Partition
K2
REDUCER
Python/R
REDUCER
Python/R
REDUCER
Python/R
Output for
K0
Output for
K0
Output for
K0
Extensions の追加
REFERENCE ASSEMBLY [ExtPython]
REFERENCE ASSEMBLY [ExtR]
特別な Reducers によって Python or R code
を分散実行
• Extension.Python.Reducer
• Extension.R.Reducer
Standard DataFrame を Reducerの入出力とし
て使える
NOTE: Reducer は、Aggregate を含んでいな
い](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-115-320.jpg)
![REFERENCE ASSEMBLY [ExtPython];
DECLARE @myScript = @"
def get_mentions(tweet):
return ';'.join( ( w[1:] for w in tweet.split() if w[0]=='@' ) )
def usqlml_main(df):
del df['time']
del df['author']
df['mentions'] = df.tweet.apply(get_mentions)
del df['tweet']
return df
";
@t =
SELECT * FROM
(VALUES
("D1","T1","A1","@foo Hello World @bar"),
("D2","T2","A2","@baz Hello World @beer")
) AS
D( date, time, author, tweet );
@m =
REDUCE @t ON date
PRODUCE date string, mentions string
USING new Extension.Python.Reducer(pyScript:@myScript);
Python Extensions
U-SQLを並列分散処理に使用する
Python code を多くのノード上で実
行
NumPy、Pandasのような、Python
の標準ライブラリが利用できる](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-116-320.jpg)
![REFERENCE ASSEMBLY ImageCommon;
REFERENCE ASSEMBLY FaceSdk;
REFERENCE ASSEMBLY ImageEmotion;
REFERENCE ASSEMBLY ImageTagging;
REFERENCE ASSEMBLY ImageOcr;
@imgs =
EXTRACT FileName string, ImgData byte[]
FROM @"/images/{FileName:*}.jpg"
USING new Cognition.Vision.ImageExtractor();
// Extract the number of objects on each image and tag them
@objects =
PROCESS @imgs
PRODUCE FileName,
NumObjects int,
Tags string
READONLY FileName
USING new Cognition.Vision.ImageTagger();
OUTPUT @objects
TO "/objects.tsv"
USING Outputters.Tsv();
Imaging](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-117-320.jpg)
![REFERENCE ASSEMBLY [TextCommon];
REFERENCE ASSEMBLY [TextSentiment];
REFERENCE ASSEMBLY [TextKeyPhrase];
@WarAndPeace =
EXTRACT No int,
Year string,
Book string, Chapter string,
Text string
FROM @"/usqlext/samples/cognition/war_and_peace.csv"
USING Extractors.Csv();
@sentiment =
PROCESS @WarAndPeace
PRODUCE No,
Year,
Book, Chapter,
Text,
Sentiment string,
Conf double
USING new Cognition.Text.SentimentAnalyzer(true);
OUTPUT @sentinment
TO "/sentiment.tsv"
USING Outputters.Tsv();
Text Analysis](https://image.slidesharecdn.com/azuredatalake-170725025826/85/Azure-DataLake-118-320.jpg)



































![[Azureビッグデータ関連サービスとHortonworks勉強会] Azureビッグデータ関連サービス最新情報](https://cdn.slidesharecdn.com/ss_thumbnails/20160719hortonworksmeetupazuredata-160721074638-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~](https://cdn.slidesharecdn.com/ss_thumbnails/20181117devfestasapporoazureaipublic-181119035506-thumbnail.jpg?width=640&height=640&fit=bounds)





![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [概要編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180215-180219043331-thumbnail.jpg?width=640&height=640&fit=bounds)
![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180308-180308093647-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/di07-170605024557-thumbnail.jpg?width=640&height=640&fit=bounds)

































