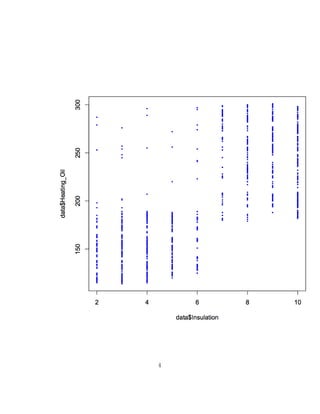
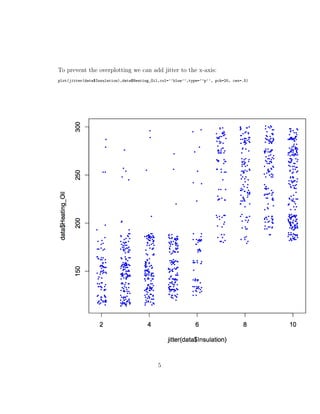
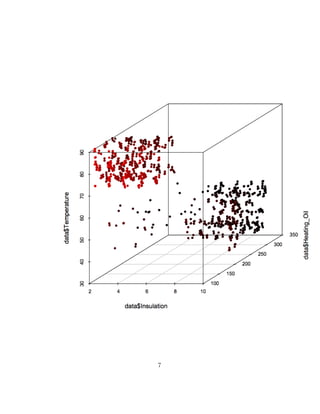
This document discusses using R to analyze a dataset and create correlation matrices and scatter plots from chapter 4 of the book "Data Mining for the Masses". It shows how to import the dataset into R, use the built-in cor() function to generate a correlation matrix matching the example in the book, and create 2D and 3D scatter plots of attributes in the data to illustrate correlations. The plots can be customized by adding jitter, color, and other graphical parameters.


































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





