Huang Xiao presented on causative adversarial learning techniques. The presentation discussed:
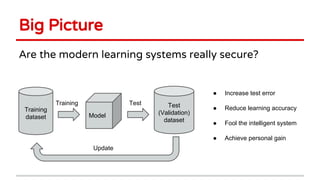
1) Two types of adversarial attacks - causative attacks which poison training data to change a model's discriminant function, and exploratory attacks which manipulate test points to circumvent detection.
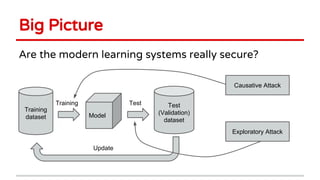
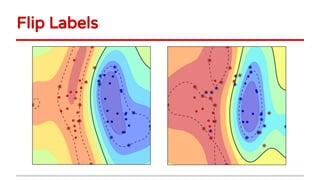
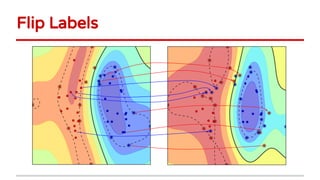
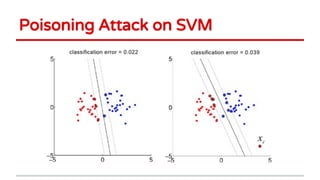
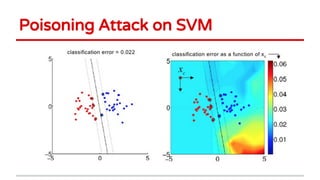
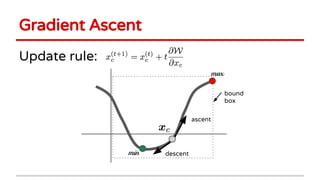
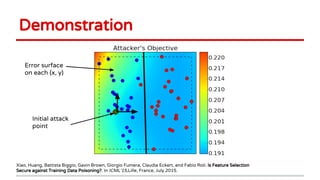
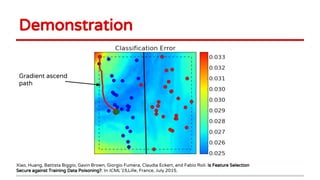
2) Examples of causative attacks including flipping labels on support vector machines and adding malicious points to maximize test error. Gradient ascent methods were used to optimize attack points.
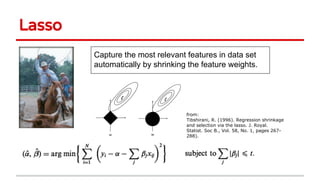
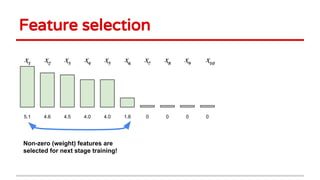
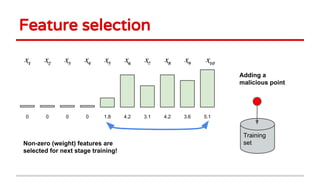
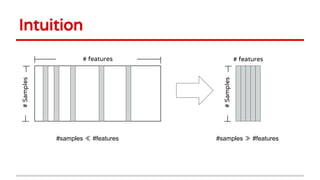
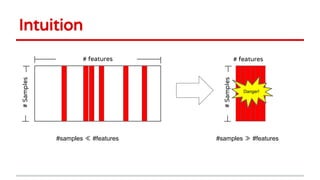
3) Feature selection algorithms like Lasso were also shown to be vulnerable to poisoning attacks by contaminating training data to mislead feature selection. Gradient methods optimized attacks to maximize generalization error.
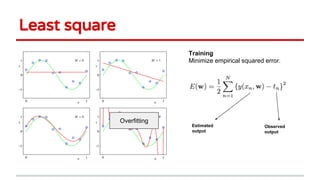
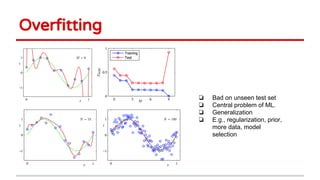
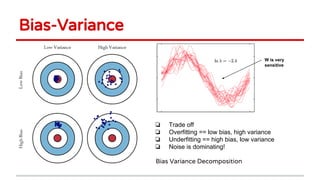
4) The talk concluded machine learning systems need to be more robust and


![Motivation
Deep networks can be easily fooled … [1]
Evolution Algor.
generated images
99.99%
confidence
“It turns out some DNNs only
focus on discriminative
features in images.”
[1] Nguyen A, Yosinski J, Clune J. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. In Computer Vision and
Pattern Recognition (CVPR '15), IEEE, 2015.](https://image.slidesharecdn.com/02xiaocausaadvlearn-150711090828-lva1-app6892/85/Causative-Adversarial-Learning-2-320.jpg)


















![[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Reinforcement Learning with Deep Energy-Based Policies](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170406-170407002545-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SOTIF US Conference] Introduction to Safe ML](https://cdn.slidesharecdn.com/ss_thumbnails/20190930crdcccsafemlv1-190930165846-thumbnail.jpg?width=640&height=640&fit=bounds)




































