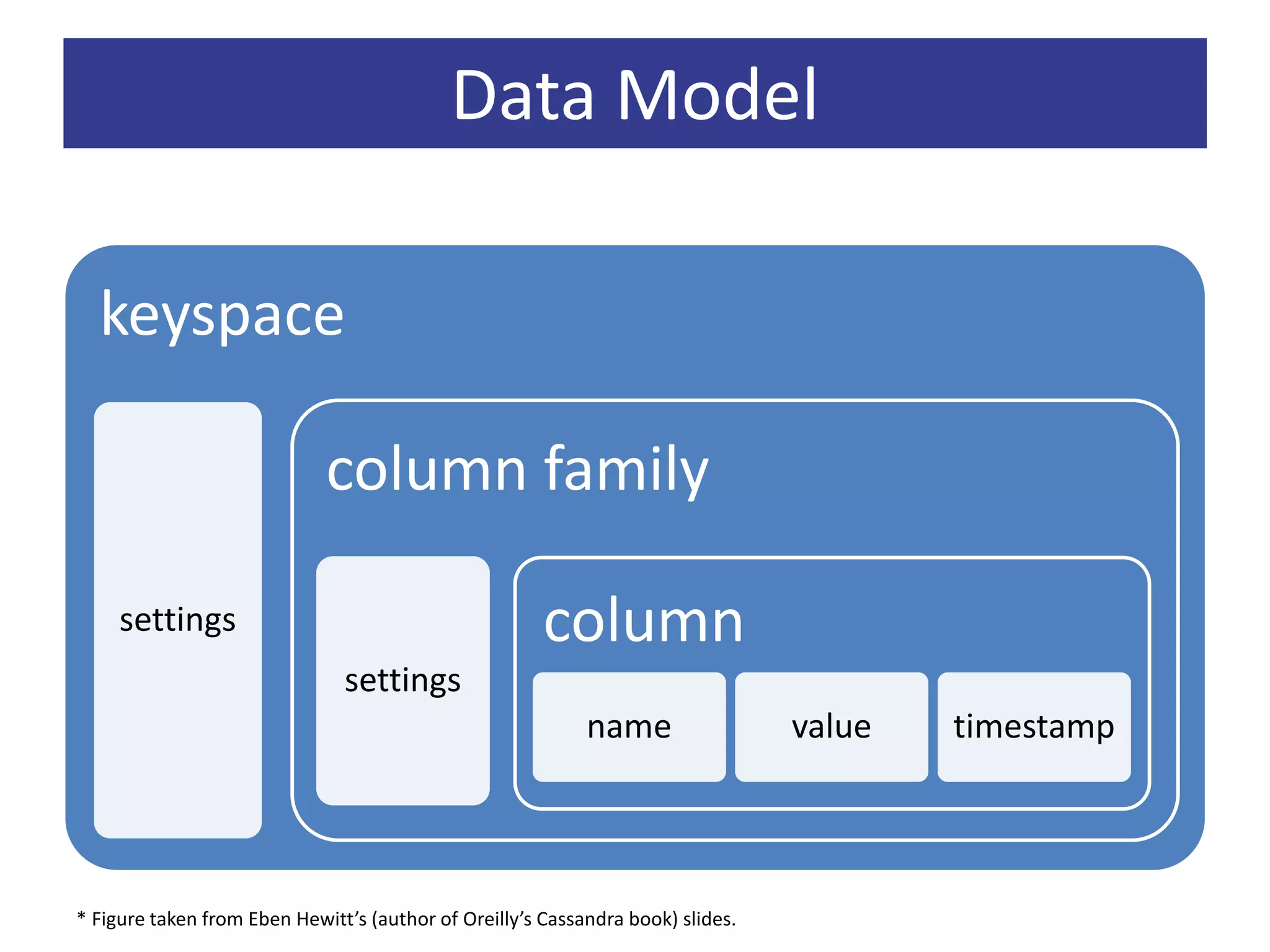
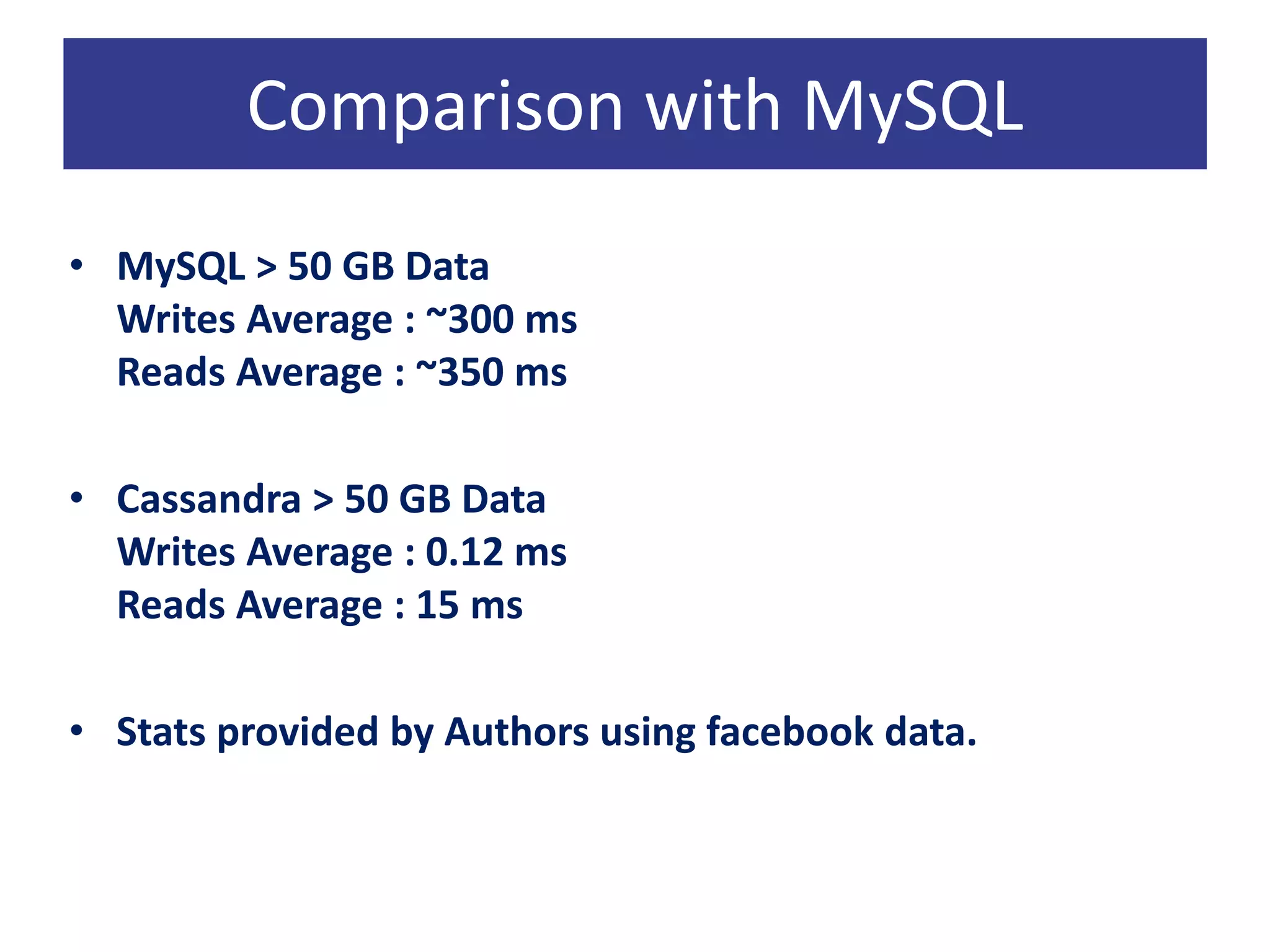
Cassandra is a decentralized structured storage system developed at Facebook as an extension of Bigtable with aspects of Dynamo. It provides high availability, high write throughput, and failure tolerance. Cassandra uses a gossip-based protocol for node communication and management, and a ring topology for data partitioning and replication across nodes. Tests on Facebook data showed Cassandra providing lower latency for writes and reads compared to MySQL, and it scaled well to large datasets and workloads based on YCSB benchmarking.