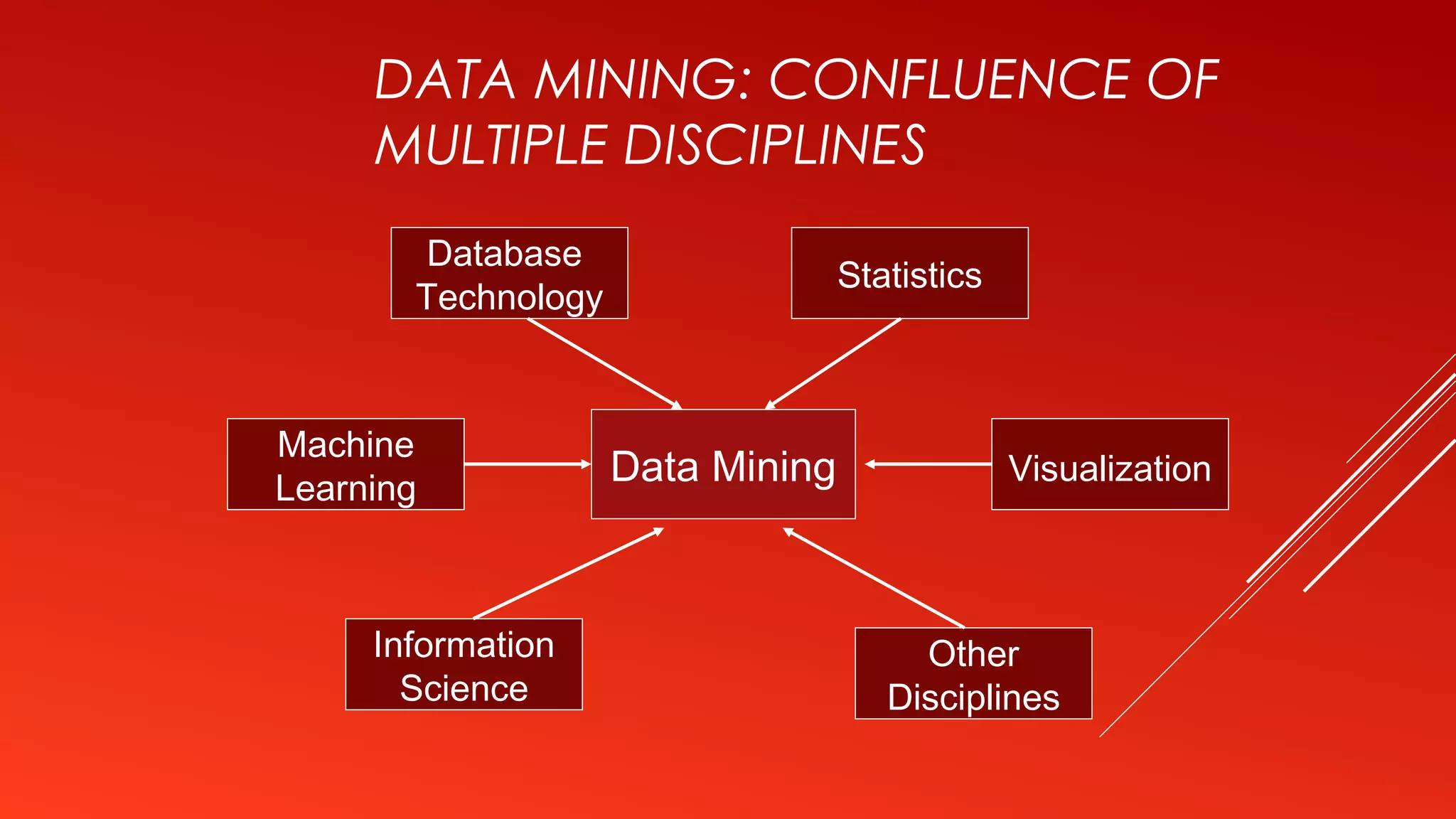
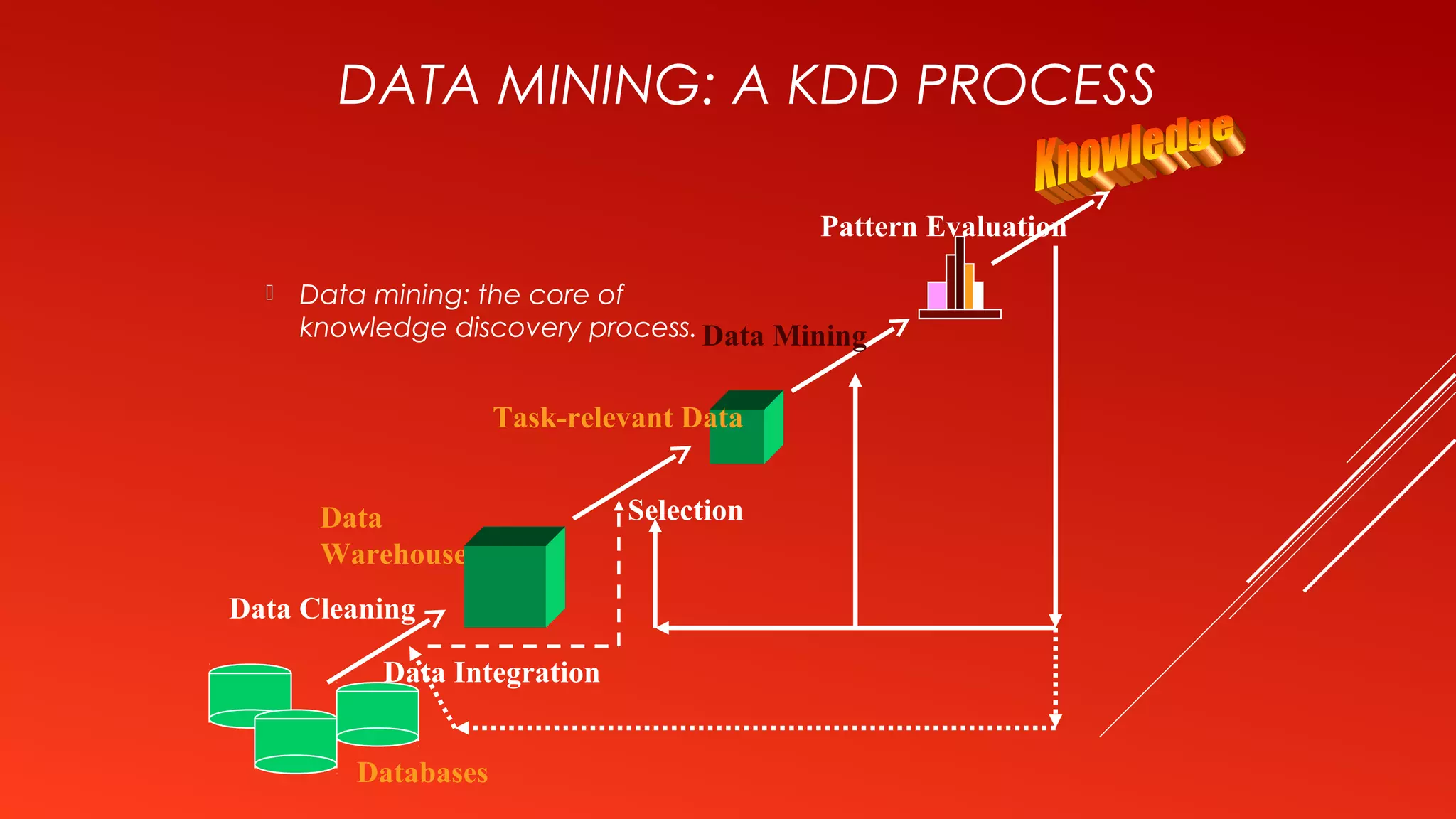
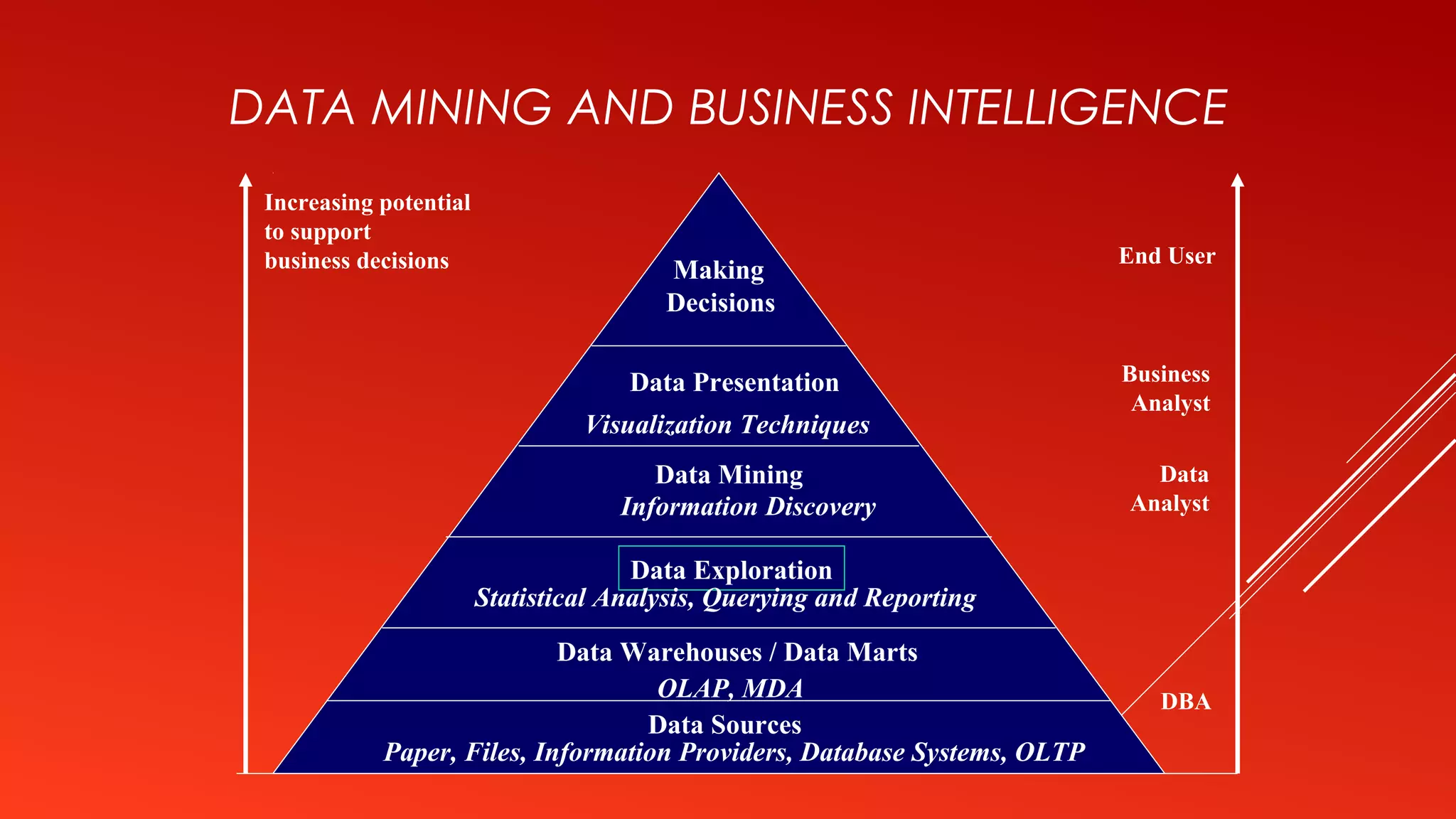
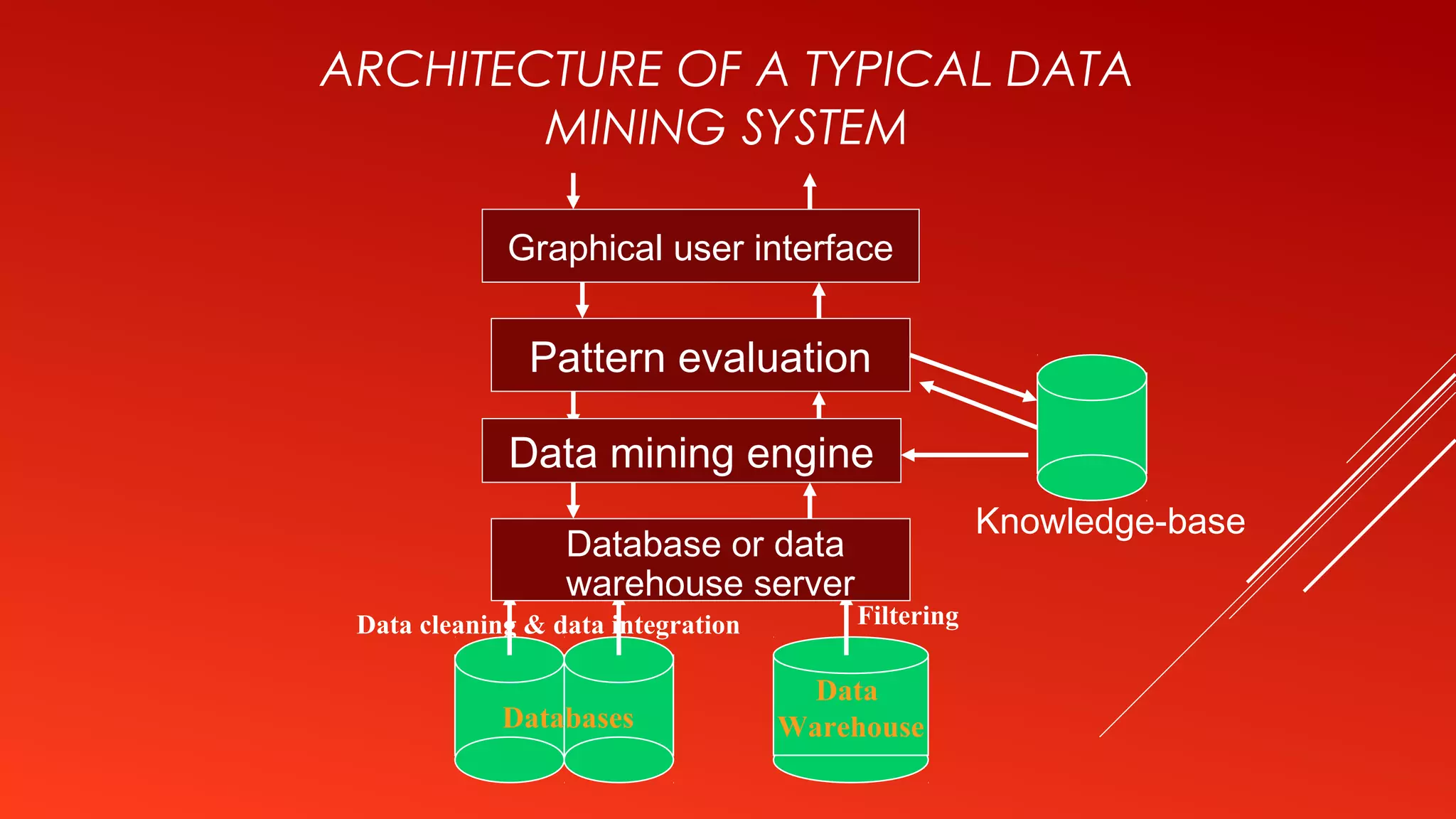
This document provides an introduction to data mining. It defines data mining as the process of extracting interesting and useful patterns from large amounts of data. The document outlines some common applications of data mining such as market analysis, risk analysis, and fraud detection. It also describes the typical steps involved in a data mining process including data cleaning, pattern evaluation, and knowledge presentation. Finally, the document discusses different data mining functionalities like classification, association rule mining, and clustering.














![DATA MINING FUNCTIONALITIES
(1)
Concept description: Characterization and discrimination
Generalize, summarize, and contrast data characteristics, e.g.,
dry vs. wet regions
Association (correlation and causality)
Multi-dimensional vs. single-dimensional association
age(X, “20..29”) ^ income(X, “20..29K”) buys(X, “PC”) [support =
2%, confidence = 60%]
contains(T, “computer”) contains(x, “software”) [1%, 75%]](https://image.slidesharecdn.com/datamining6months-140806235236-phpapp02/75/Data-mining-final-year-project-in-jalandhar-18-2048.jpg)