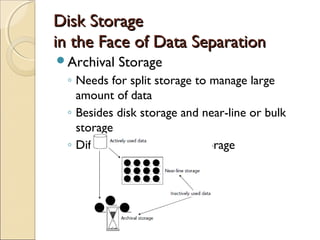
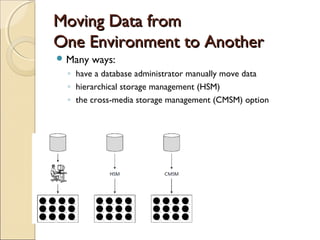
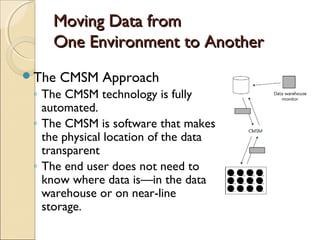
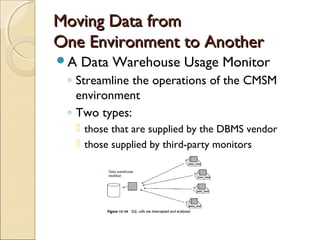
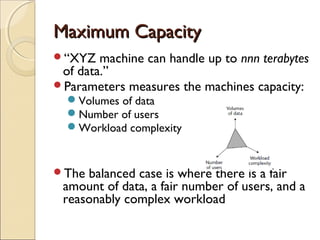
This chapter discusses challenges with very large data warehouses. As data warehouses grow larger over time by collecting granular historical data from many sources, normal database operations require more resources and storage costs increase dramatically. To manage costs and capacity for large volumes of data, it is important to separate infrequently used "dormant" data from actively used data and store dormant data in cheaper near-line or archival storage. Transparent cross-media storage management techniques can automatically move data between online, near-line, and archival storage tiers. These techniques help mitigate the rising costs of large data warehouses and maximize their storage capacity over time.