



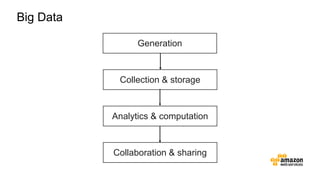

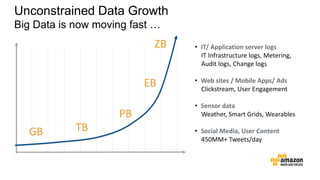

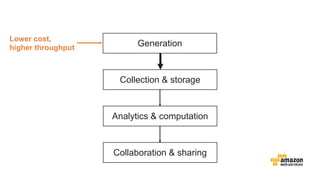
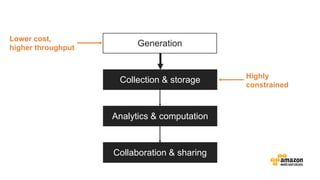
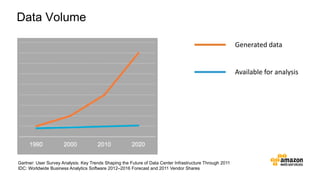
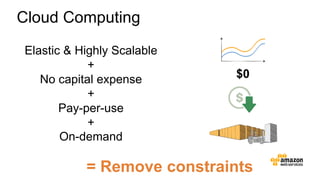
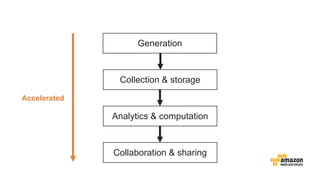





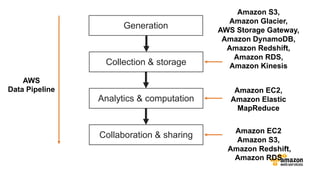
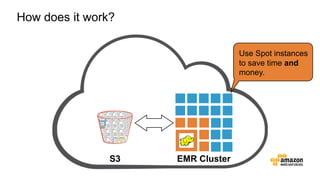
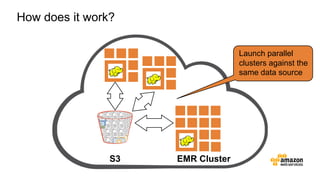
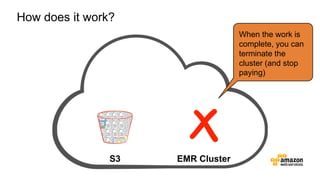




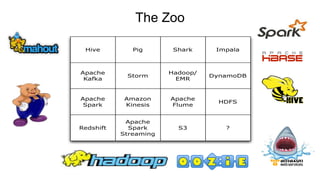






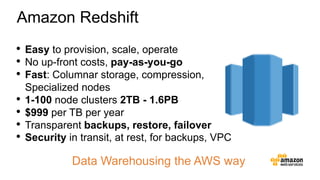
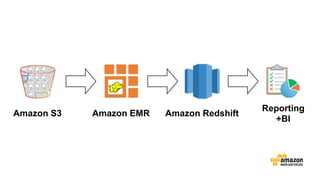
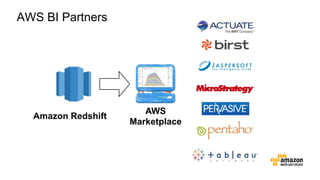
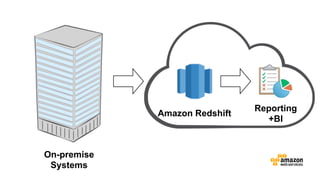
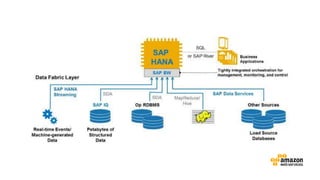
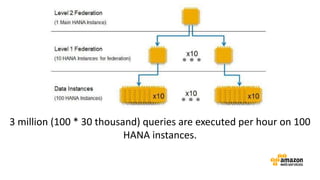
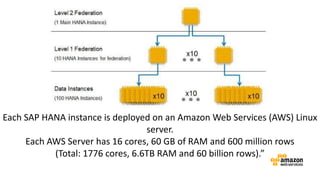
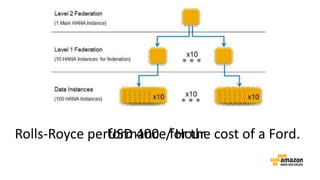




The document discusses the concept of big data and its implications for data collection, storage, and analysis, emphasizing the challenges posed by its velocity, volume, and variety. It highlights the role of cloud computing, specifically AWS services, in efficiently managing big data with tools such as Amazon EMR and Redshift, which facilitate scalable data processing and analytics. Additionally, it showcases successful case studies illustrating significant returns on investment achieved through targeted advertising campaigns leveraging big data technologies.






























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
















