






![curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X POST -d {"ServiceInfo":{"service_name":"PIG"}} http://bluedata-
71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/services
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X POST http://bluedata-
71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/services/PIG/components/PIG
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X POST -d@pig-env.json http://bluedata-
71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/configurations
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X POST -d@pig-properties.json http://bluedata-
71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/configurations
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X POST -d@pig-log4j.json
http://bluedata-71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/configurations
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X PUT -d {"Clusters":{"desired_configs":{"type":"pig-
env","tag":"bluedata"}}} http://bluedata-71.openstacklocal:8080/api/v1/clusters/Ambari_vm7
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X PUT -d {"Clusters":{"desired_configs":{"type":"pig-
properties","tag":"bluedata"}}} http://bluedata-71.openstacklocal:8080/api/v1/clusters/Ambari_vm7
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X PUT -d {"Clusters":{"desired_configs":{"type":"pig-
log4j","tag":"bluedata"}}} http://bluedata-71.openstacklocal:8080/api/v1/clusters/Ambari_vm7
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X POST -d {"host_components":[{"HostRoles":{"component_name":"PIG"}}]}
http://bluedata-71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/hosts?Hosts/host_name=bluedata-71.openstacklocal
curl -kib /root/BD_Setup/cookie_jar -H 'X-Requested-By: ambari' -X PUT -d {"ServiceInfo":{"state":"INSTALLED"}} http://bluedata-
71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/services/PIG
curl -u admin:admin -i -H 'X-Requested-By: ambari' -X GET http://bluedata-71.openstacklocal:8080/api/v1/clusters/Ambari_vm7/services/PIG
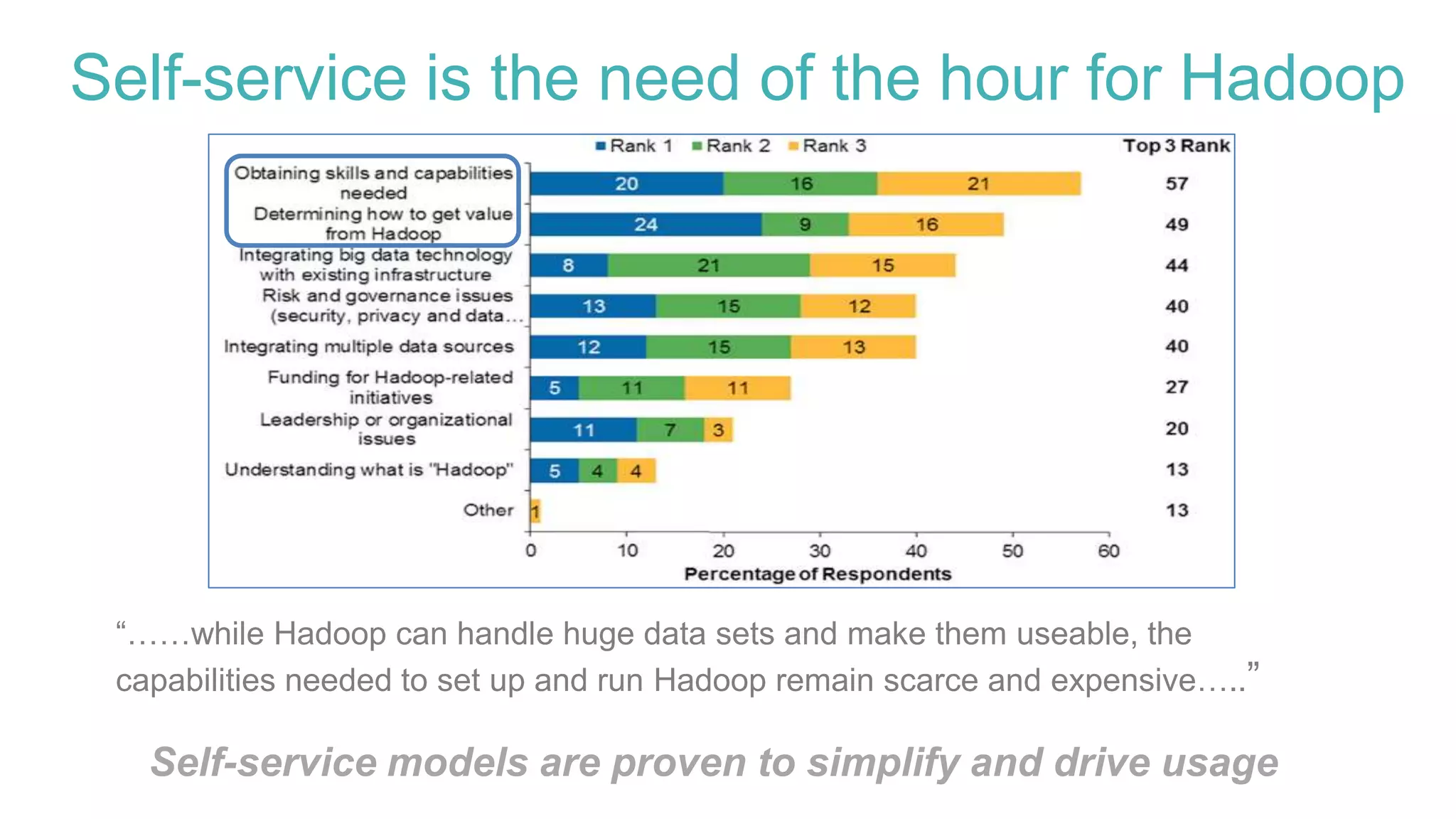
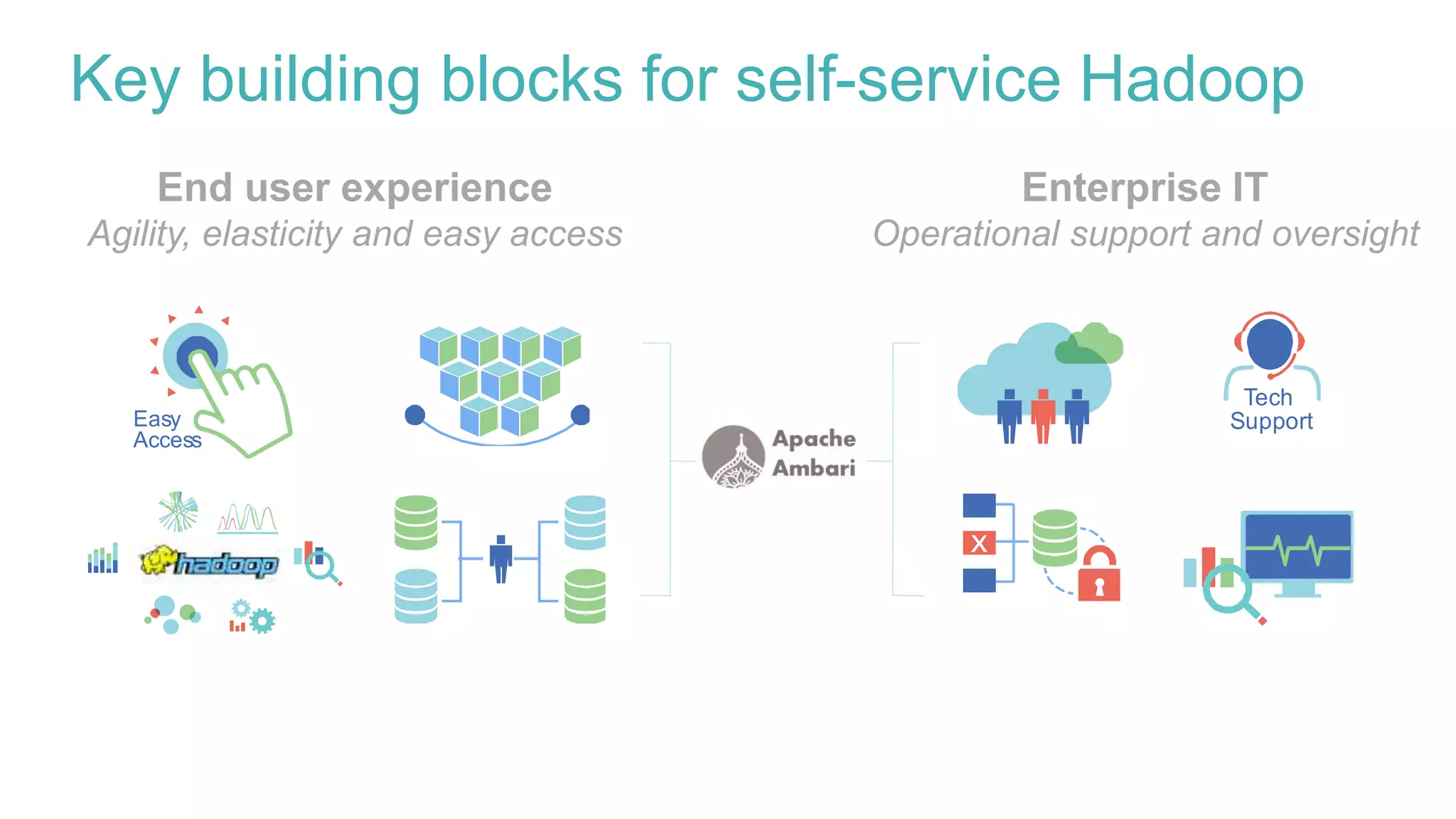
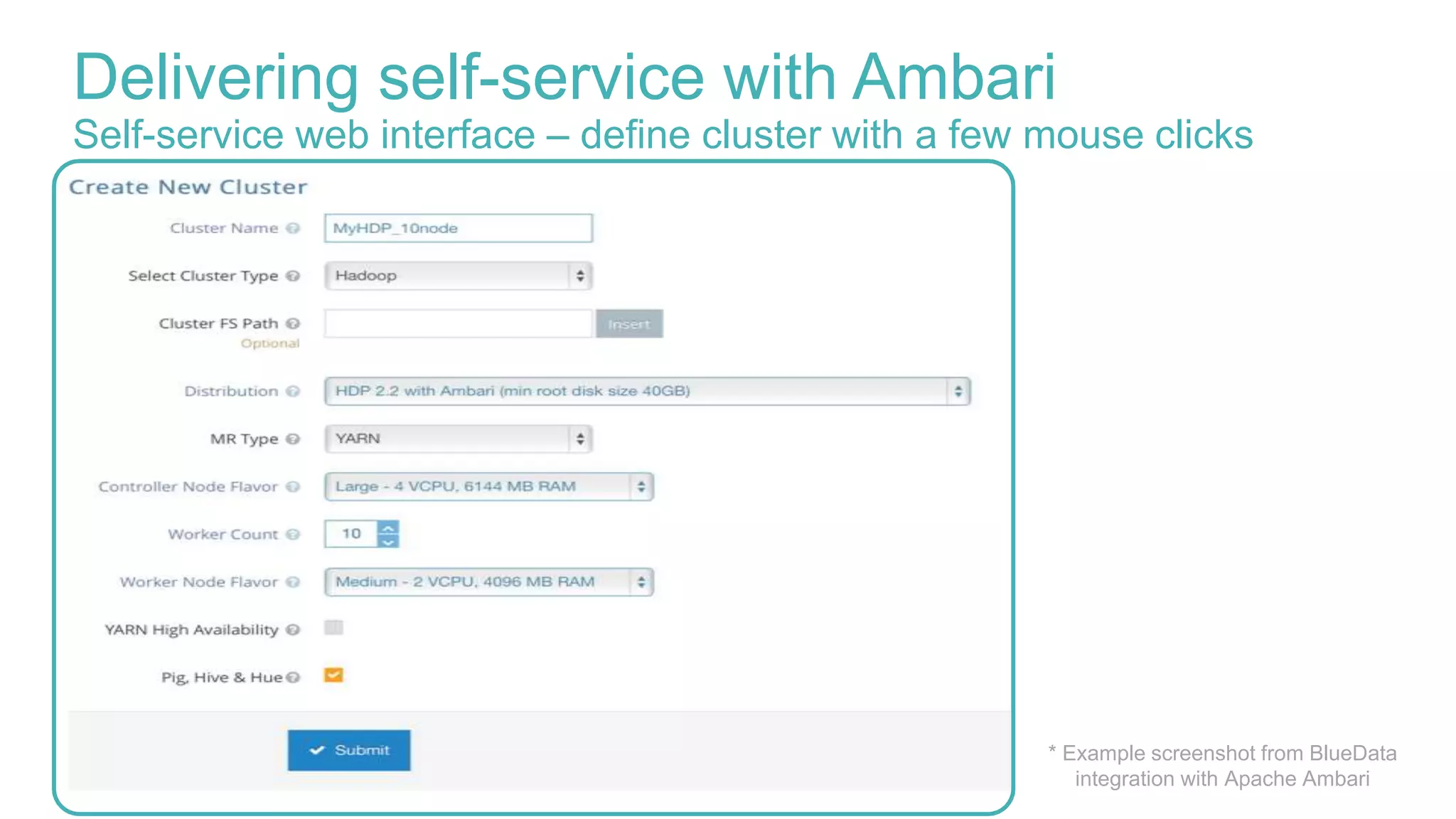
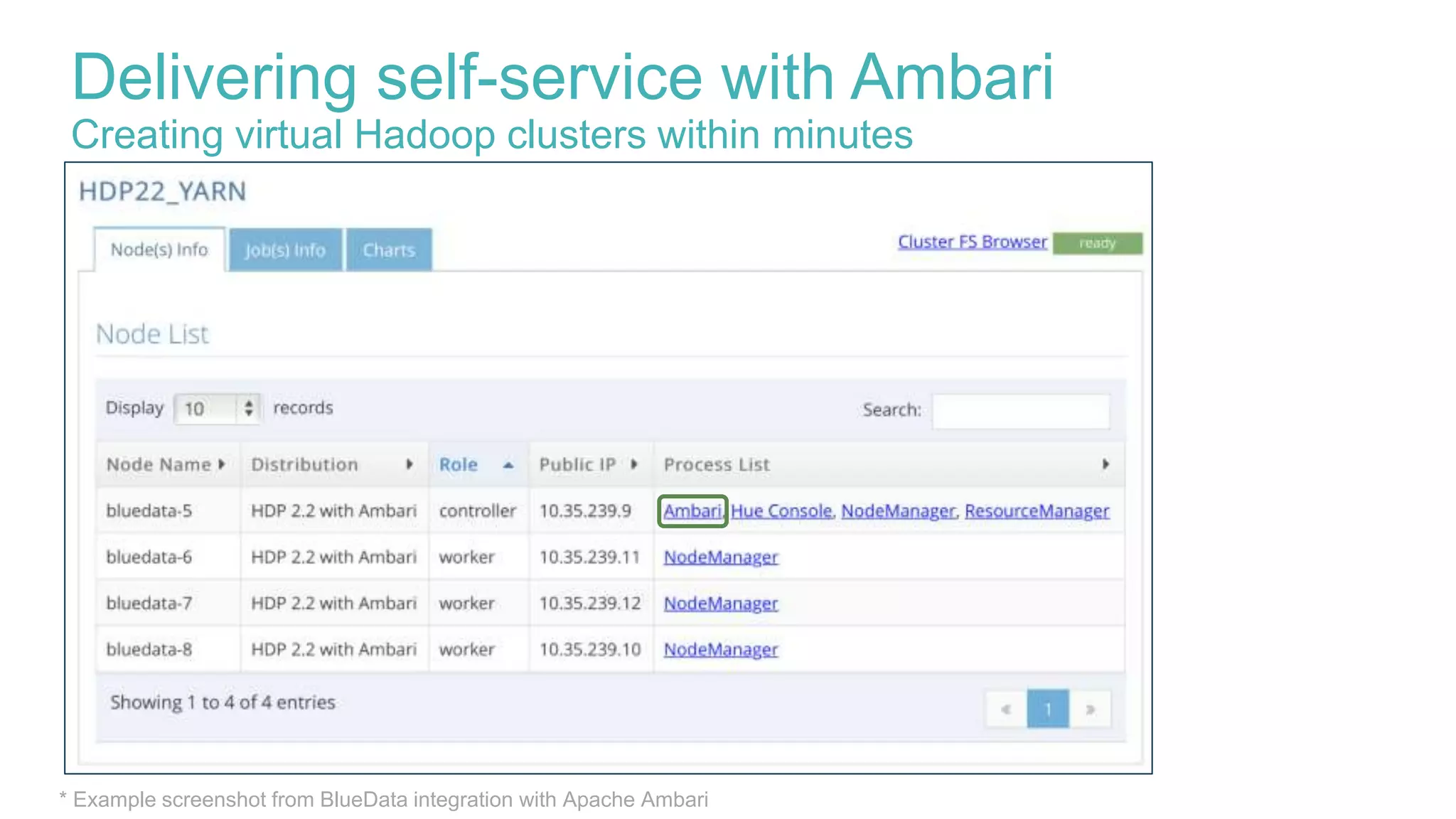
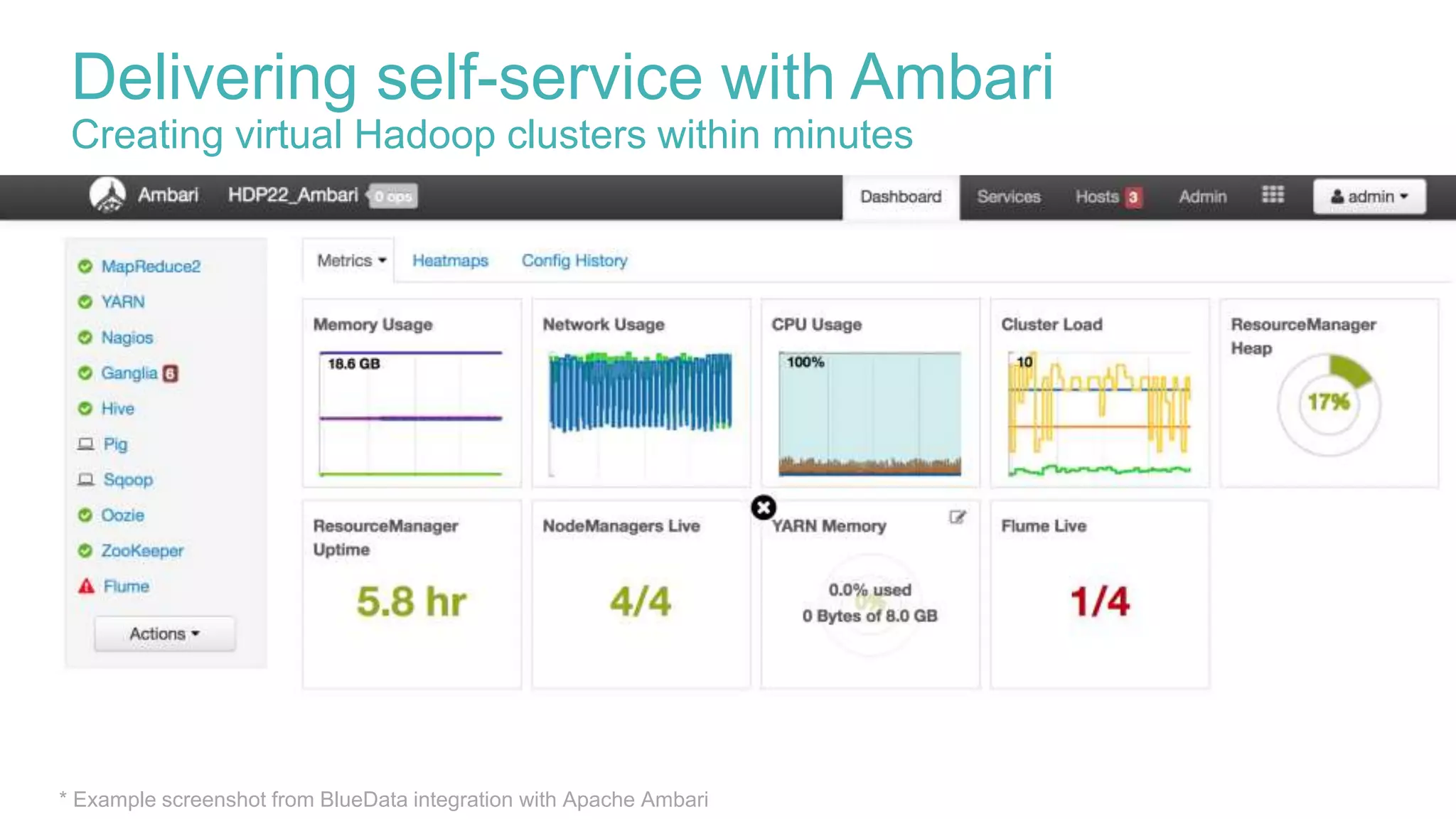
Delivering self-service with Ambari
REST API example to deploy specific service (Pig)
Service
Configs
Install](https://image.slidesharecdn.com/june9145pmbluedatachintamaneniv2-150616214956-lva1-app6891/75/Self-Service-Provisioning-and-Hadoop-Management-with-Apache-Ambari-17-2048.jpg)





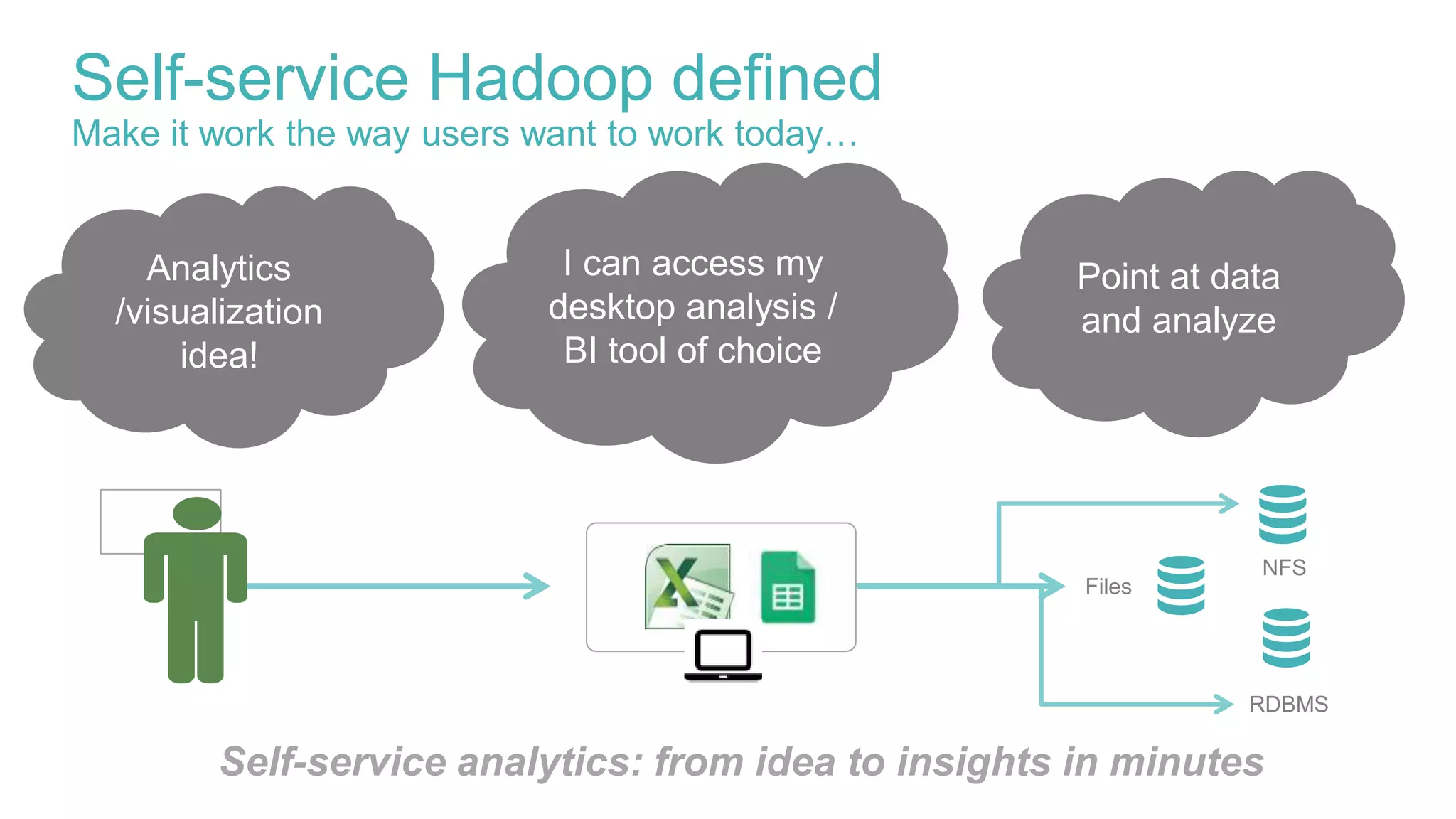
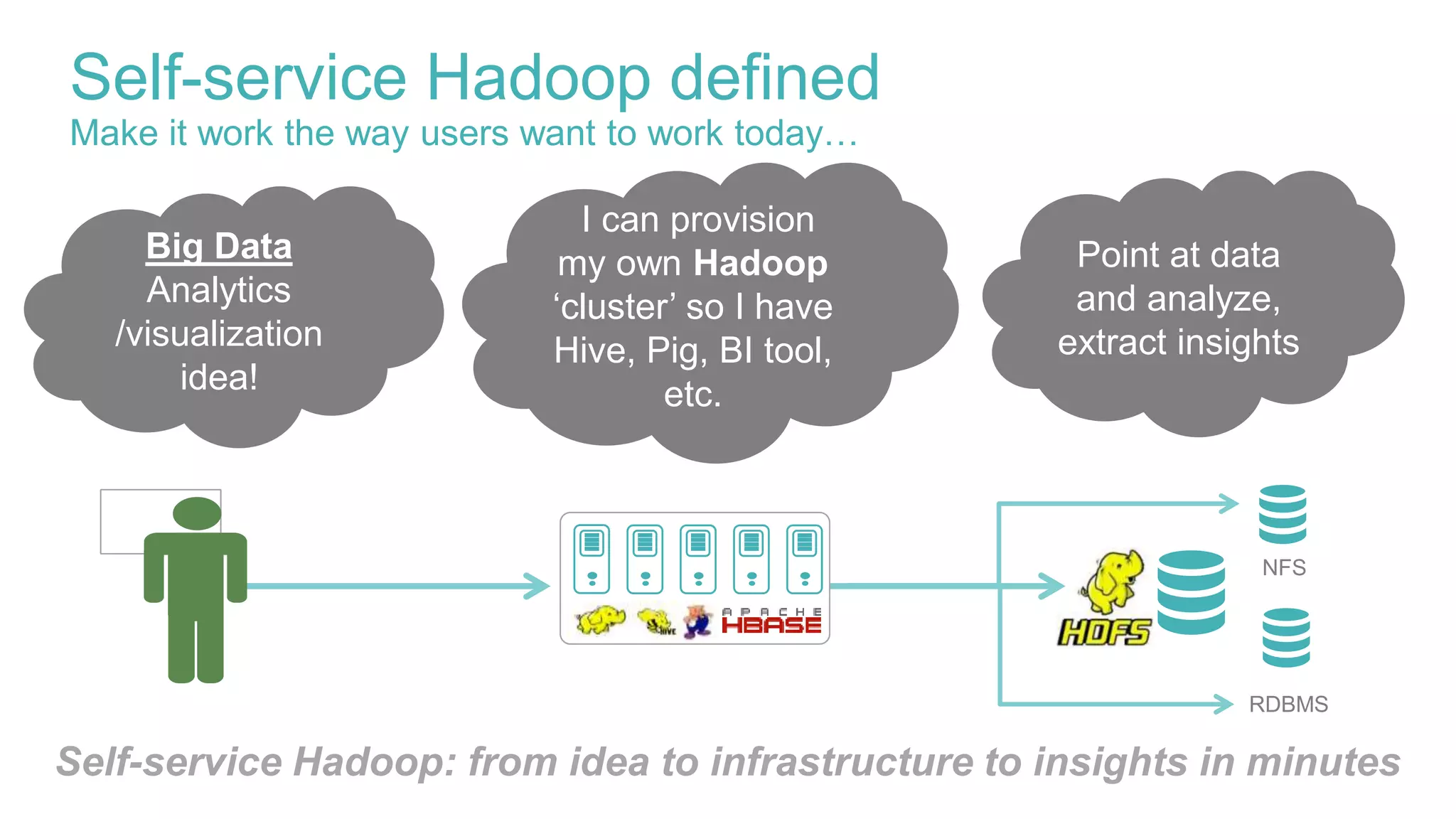
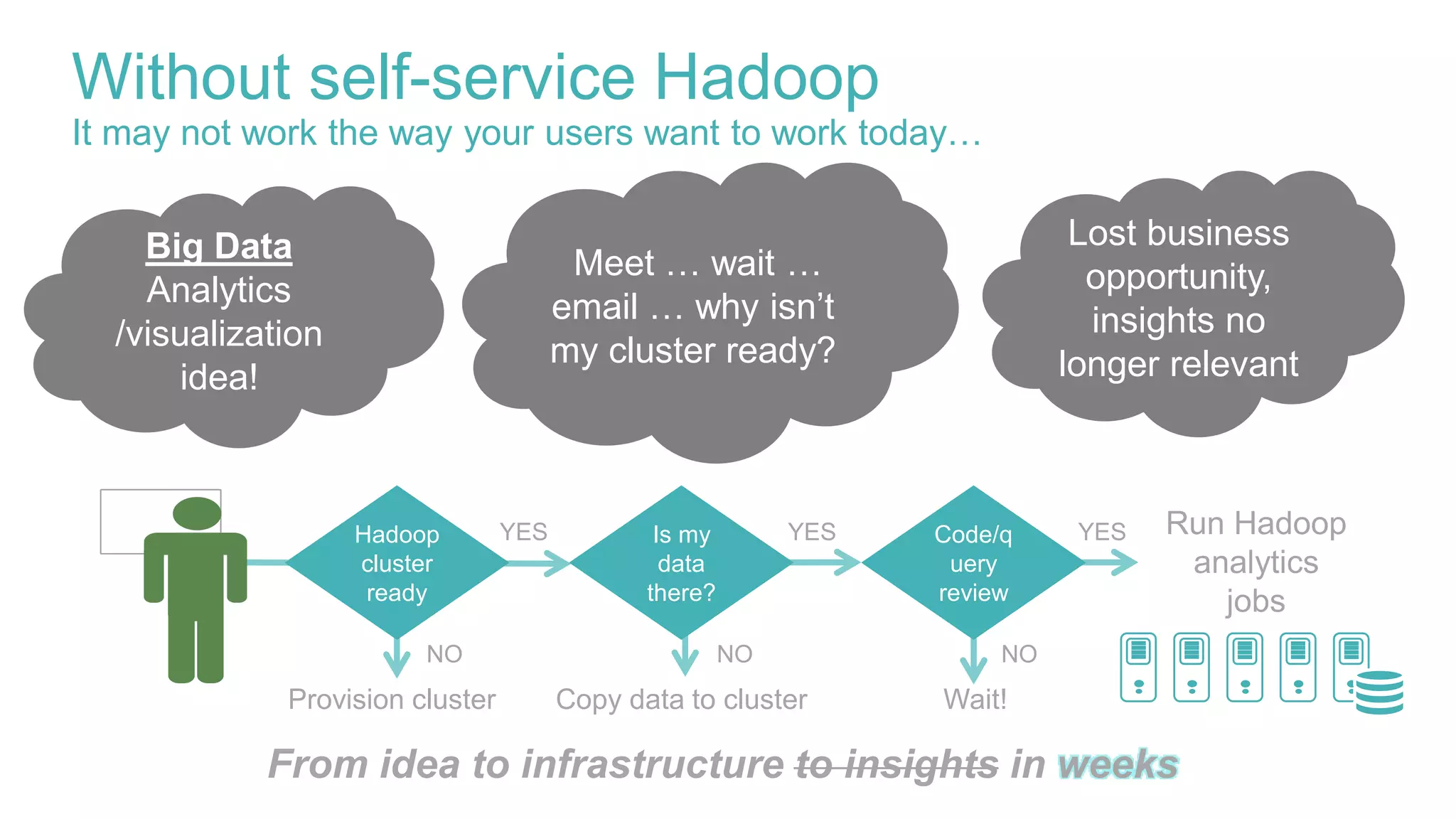
This document discusses delivering self-service Hadoop using Apache Ambari. It defines self-service Hadoop as enabling users to provision their own Hadoop clusters and analyze data within minutes. Key building blocks for self-service Hadoop include a self-service user interface, agility/elasticity, and IT support. Apache Ambari is highlighted as it allows automated provisioning of Hadoop clusters via REST APIs and provides enterprise-grade management. The presentation demonstrates how Ambari APIs can be used to quickly provision virtual Hadoop clusters on demand and deploy specific analytics services.














































![Discover.hdp2.2.ambari.final[1]](https://cdn.slidesharecdn.com/ss_thumbnails/discover-150114162536-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





