Downloaded 48 times





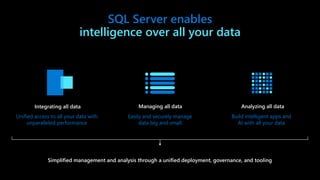



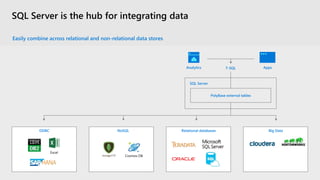








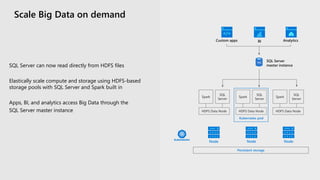



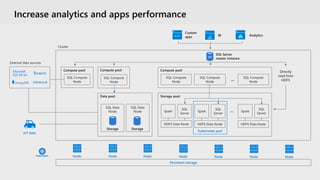
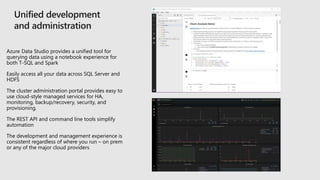




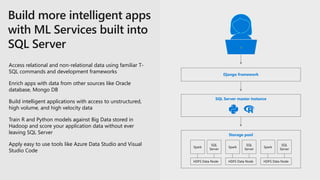
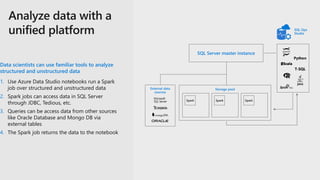


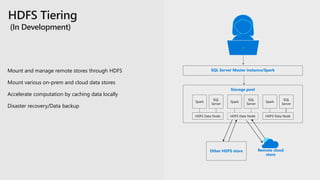







The document discusses the advancements and features of SQL Server 2019 in relation to big data management and analytics, emphasizing the integration of structured and unstructured data through data virtualization and unified tooling. It outlines the benefits of using containers and Kubernetes for easy deployment and management of big data clusters, highlighting improvements in accessibility, performance, and security. Organizations leveraging SQL Server 2019 can enhance their data insights to drive innovation and competitiveness in the evolving data landscape.