































![0mq PUSH-PULL (workload distribution)
Consumer 1
Consumer 2
Consumer 3
[Round-Robin-ish]
25](https://image.slidesharecdn.com/london-scalability-meetup-120415104204-phpapp01/75/Scaling-Teams-Processes-and-Architectures-59-2048.jpg)
![0mq PUB-SUB (High Availability)
Listener 1
Publisher 1
Listener 2
Publisher 2
Listener 3
[Broadcast] [Dynamic Subscriptions]
26](https://image.slidesharecdn.com/london-scalability-meetup-120415104204-phpapp01/75/Scaling-Teams-Processes-and-Architectures-60-2048.jpg)





The document by Lorenzo Alberton outlines key principles for scaling teams, processes, and technology within an organization. It emphasizes the importance of hiring the right talent, establishing effective team structures, and implementing critical processes for improved management and scalability. Additionally, it covers architectural principles, the significance of monitoring systems, and strategies for managing big data and ensuring performance through caching and load testing.
Introduction to scaling teams, processes, and architectures for managing growth.
Scalability encompasses three main elements: People, Processes, and Technology.
Discussion on staffing, roles, management, and team dynamics.
Key staffing principles: hire smarter people, cultural fit, and avoid toxic individuals.
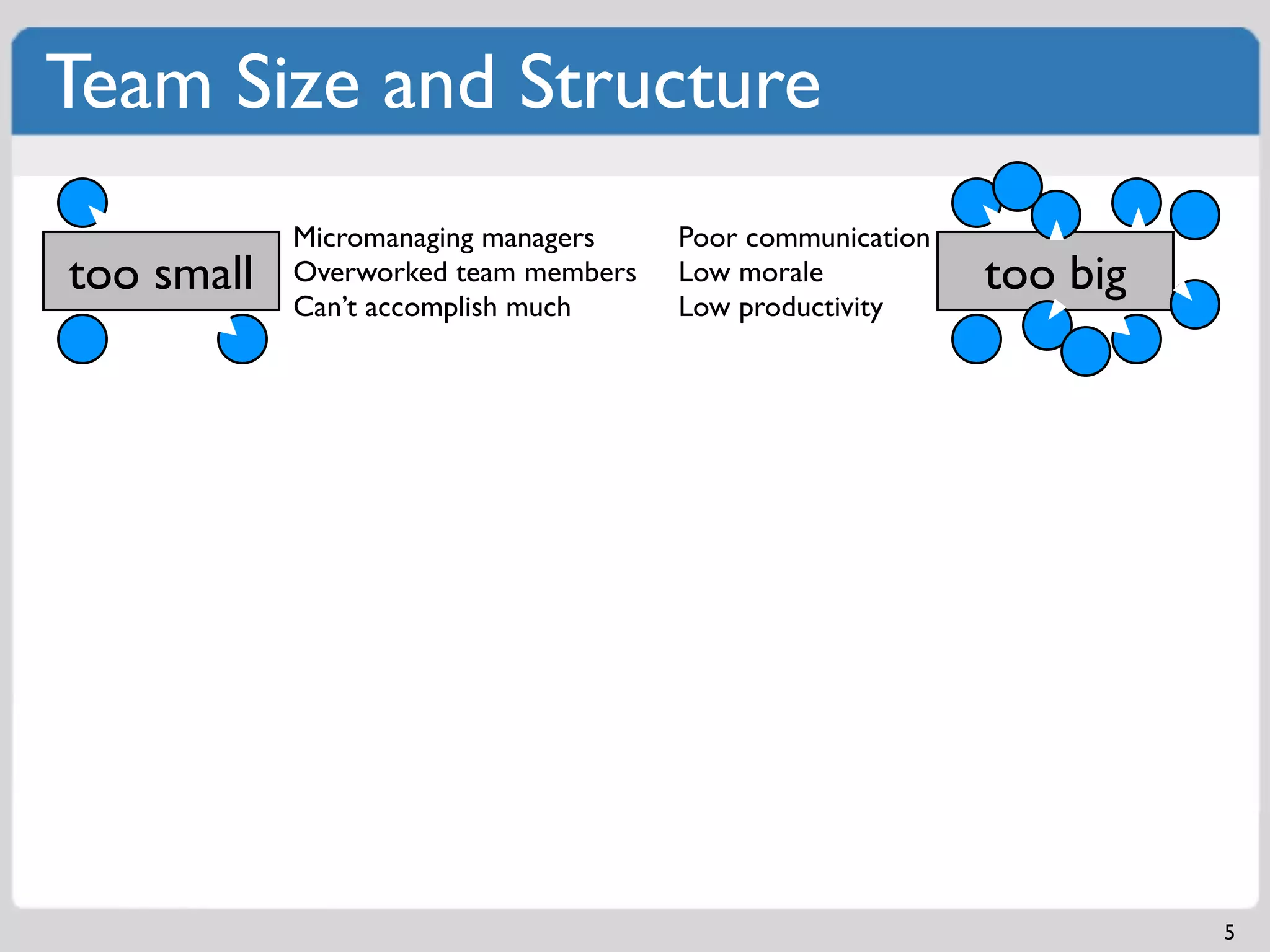
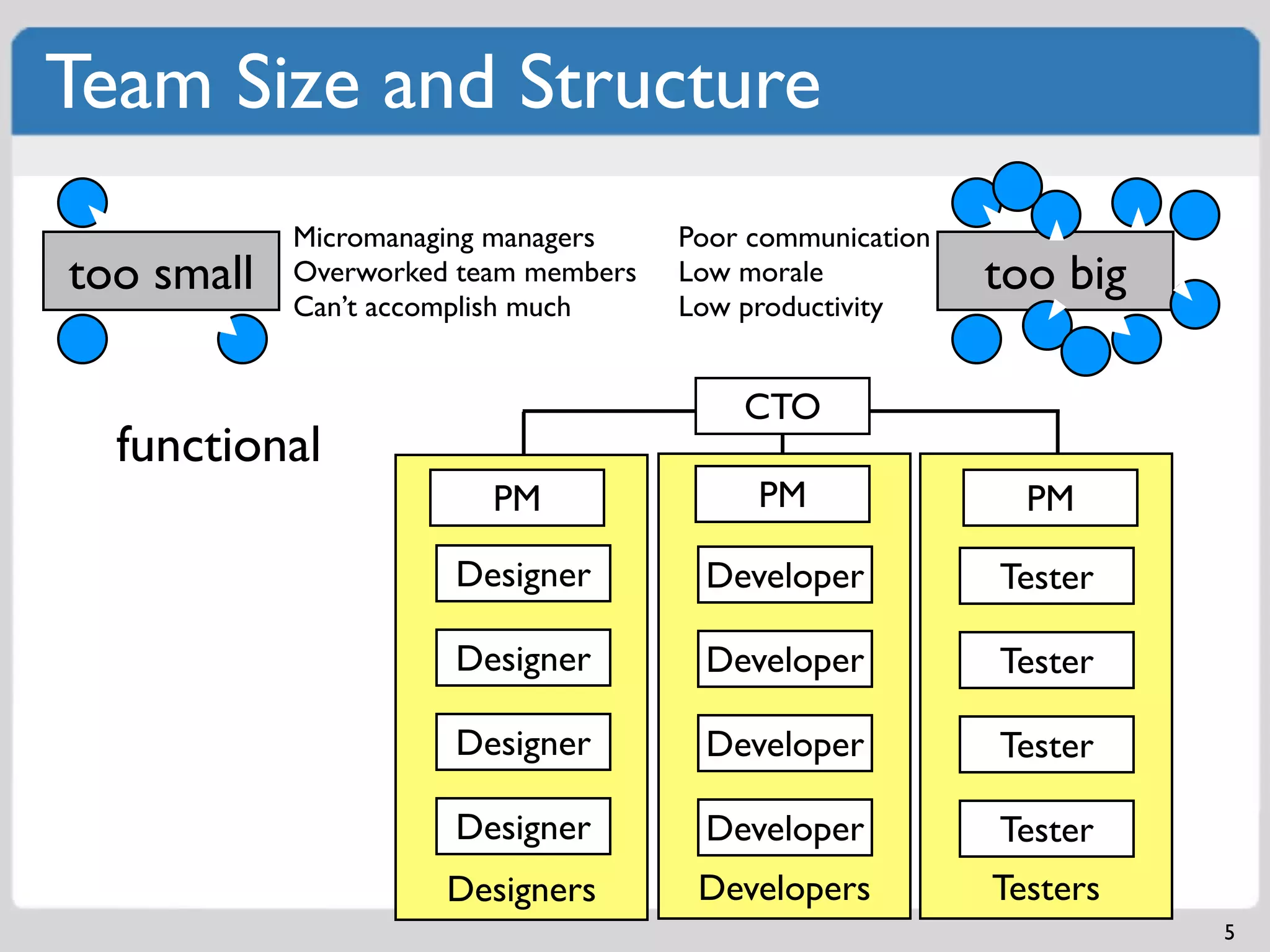
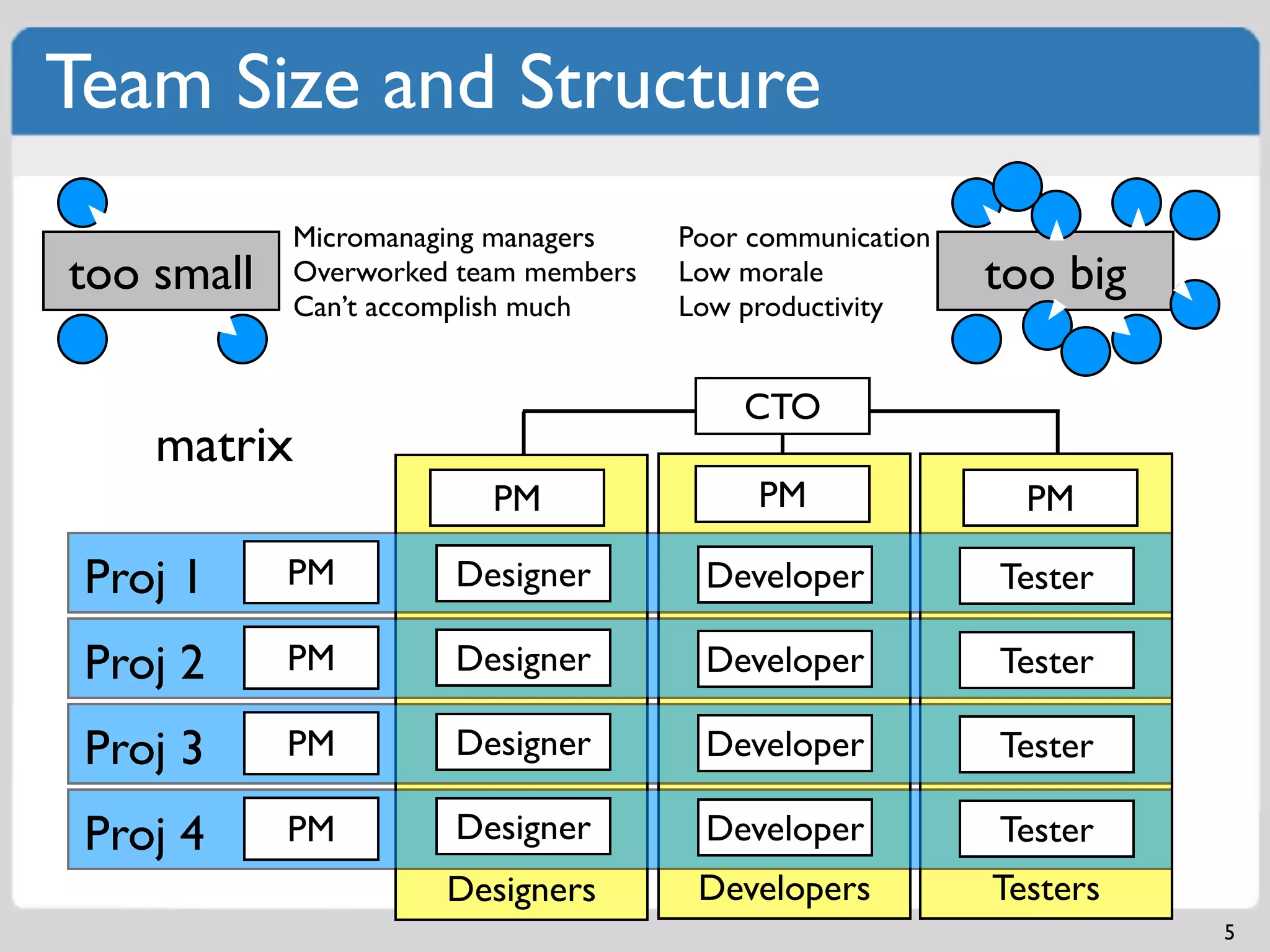
Challenges of team size including micromanagement and communication issues; examples of structures.
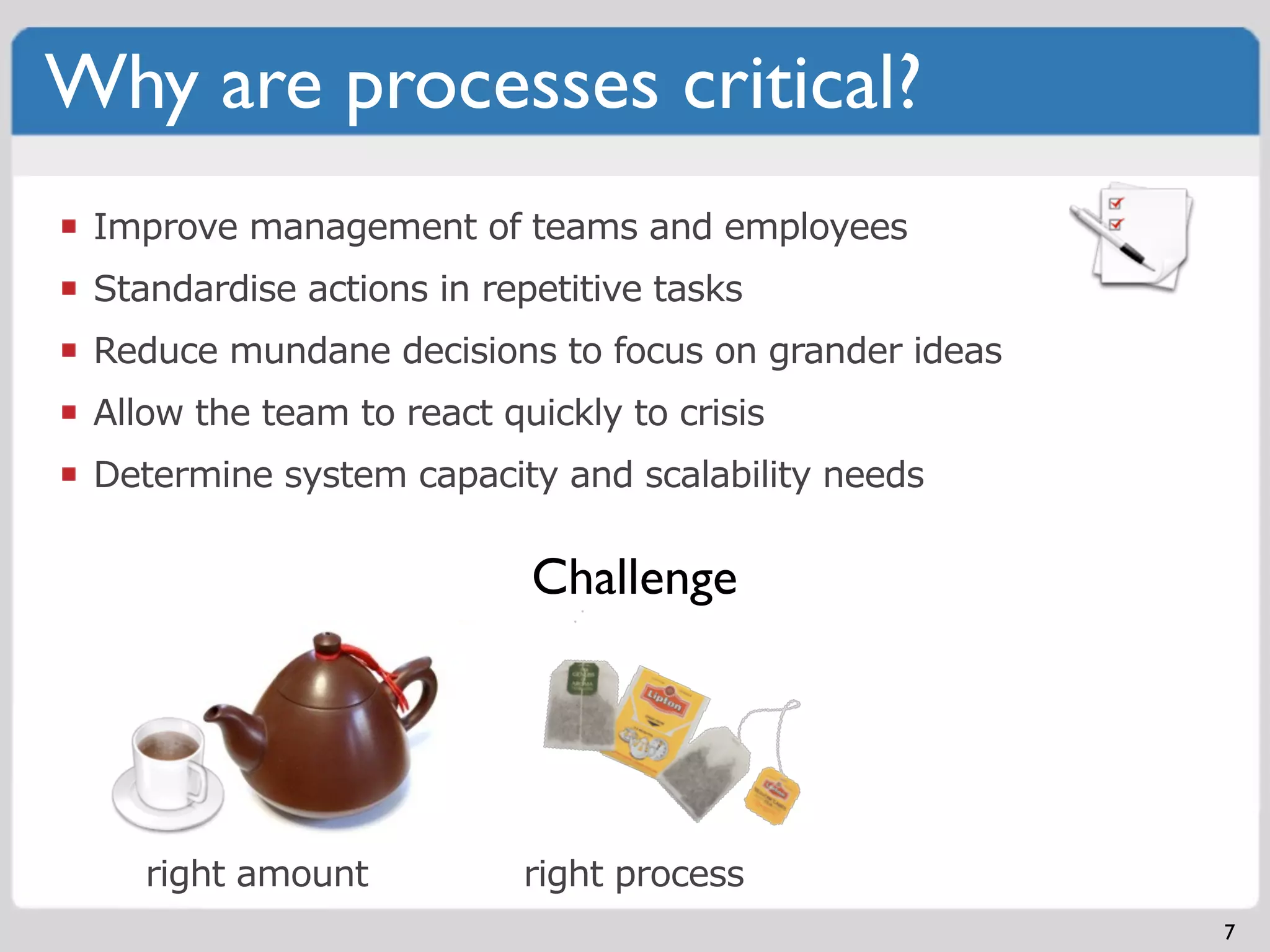
Processes are critical for effective team management, standardizing actions, and enabling agility.
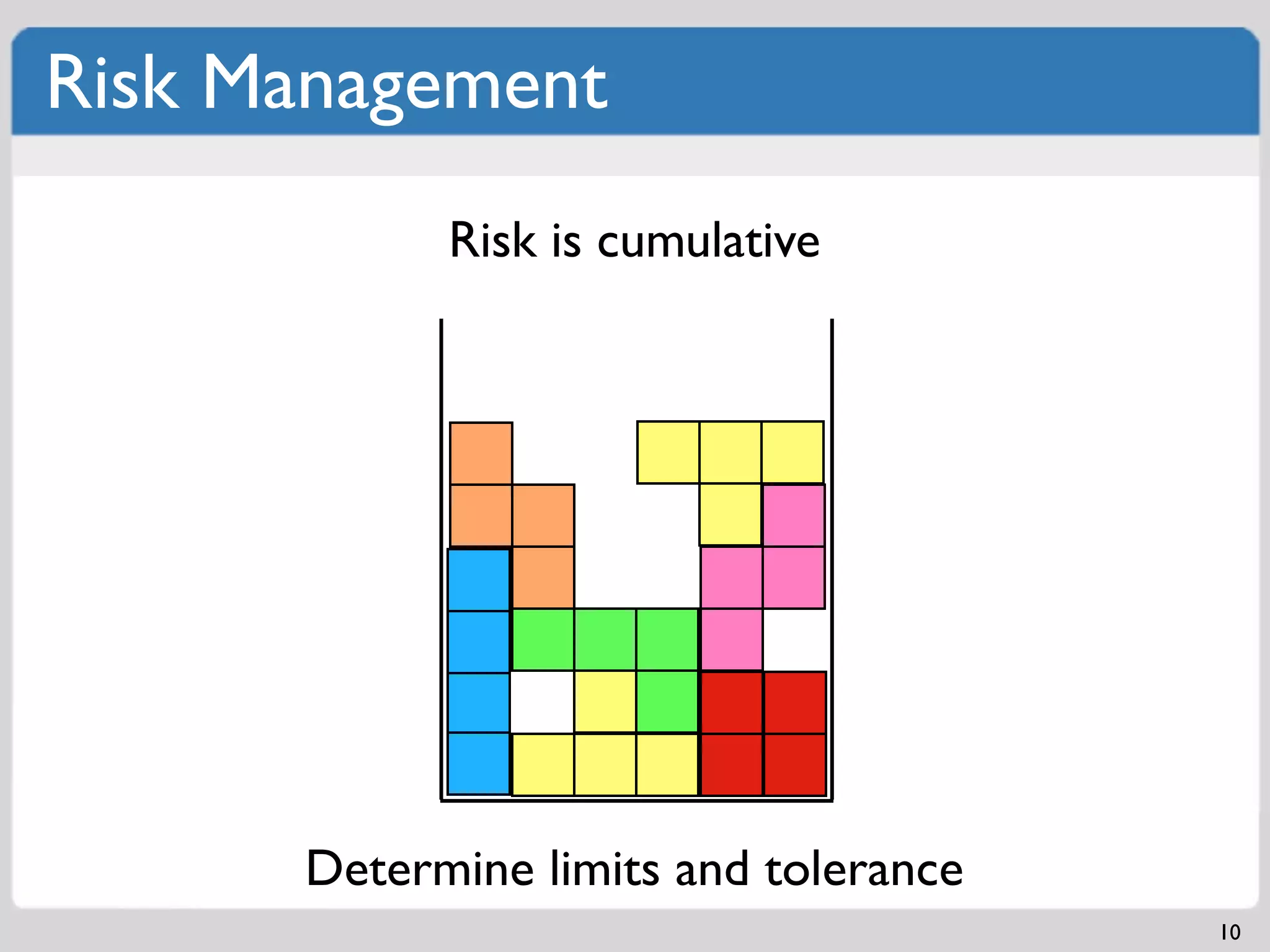
Understanding capacity, current load assessment, and implications for planning.Control change by determining risk levels and cumulative effects.
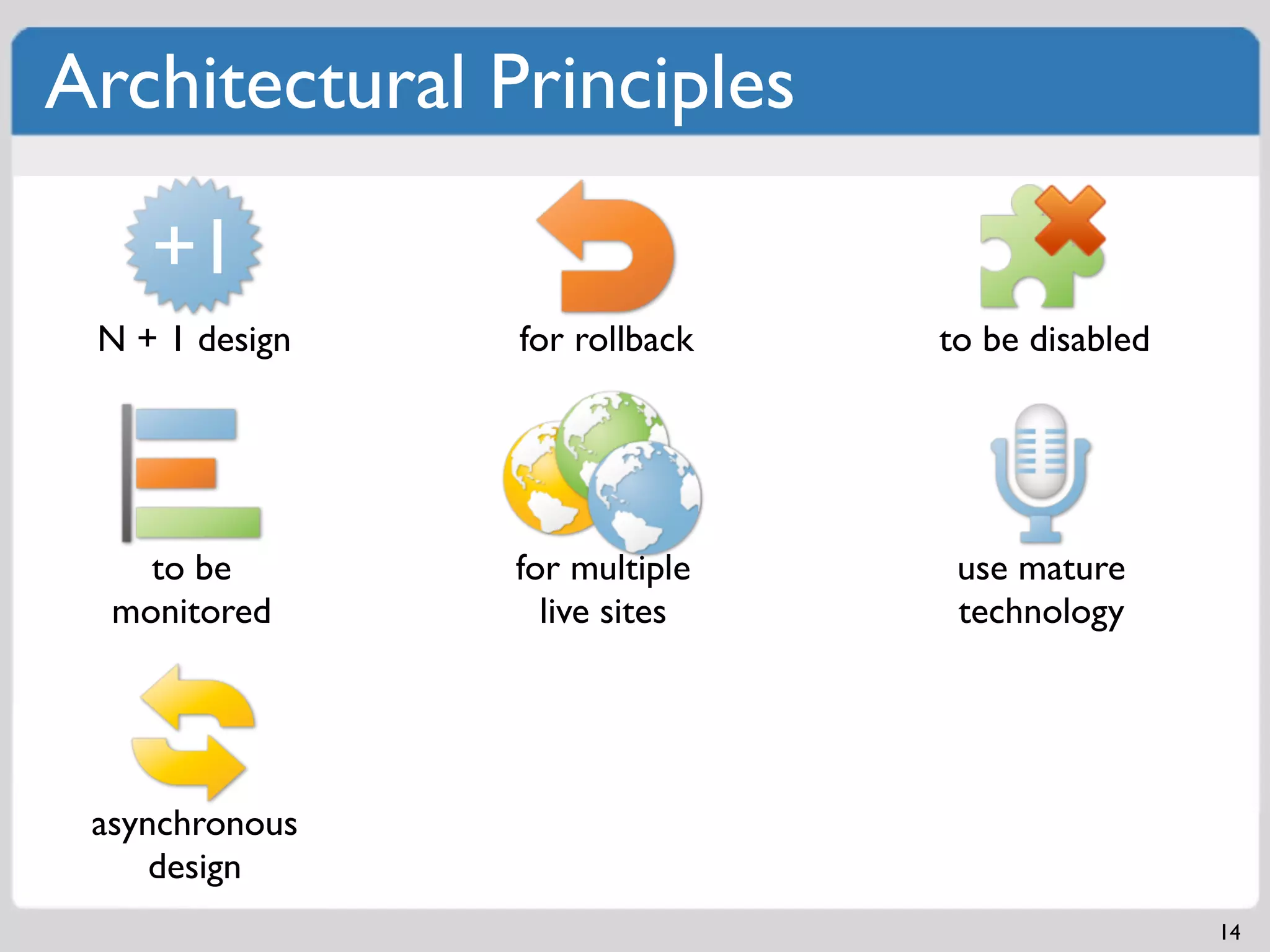
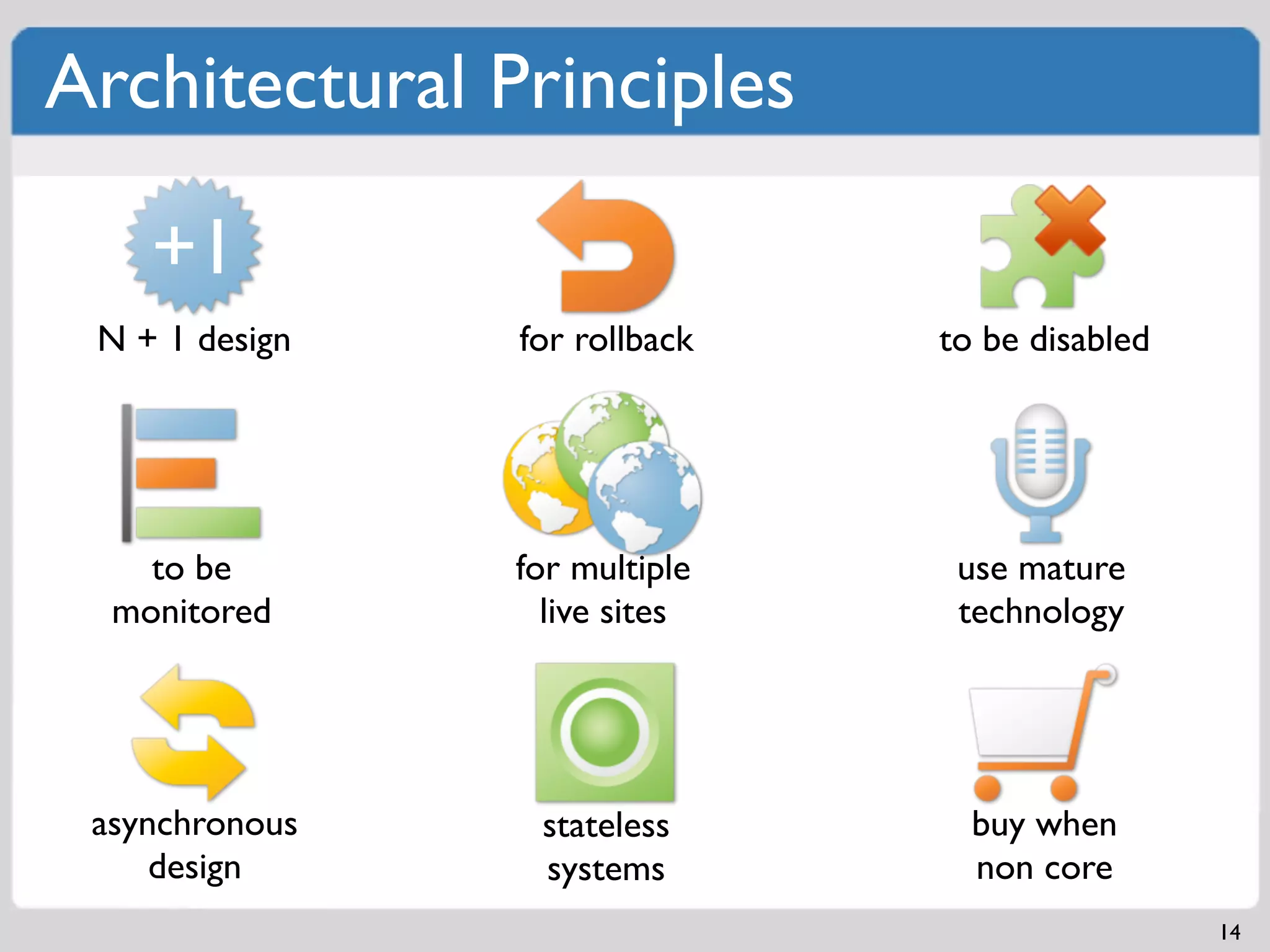
Load and stress testing to identify bottlenecks and ensure app stability.Fundamentals of architecting scalable solutions, including N + 1 design principles.
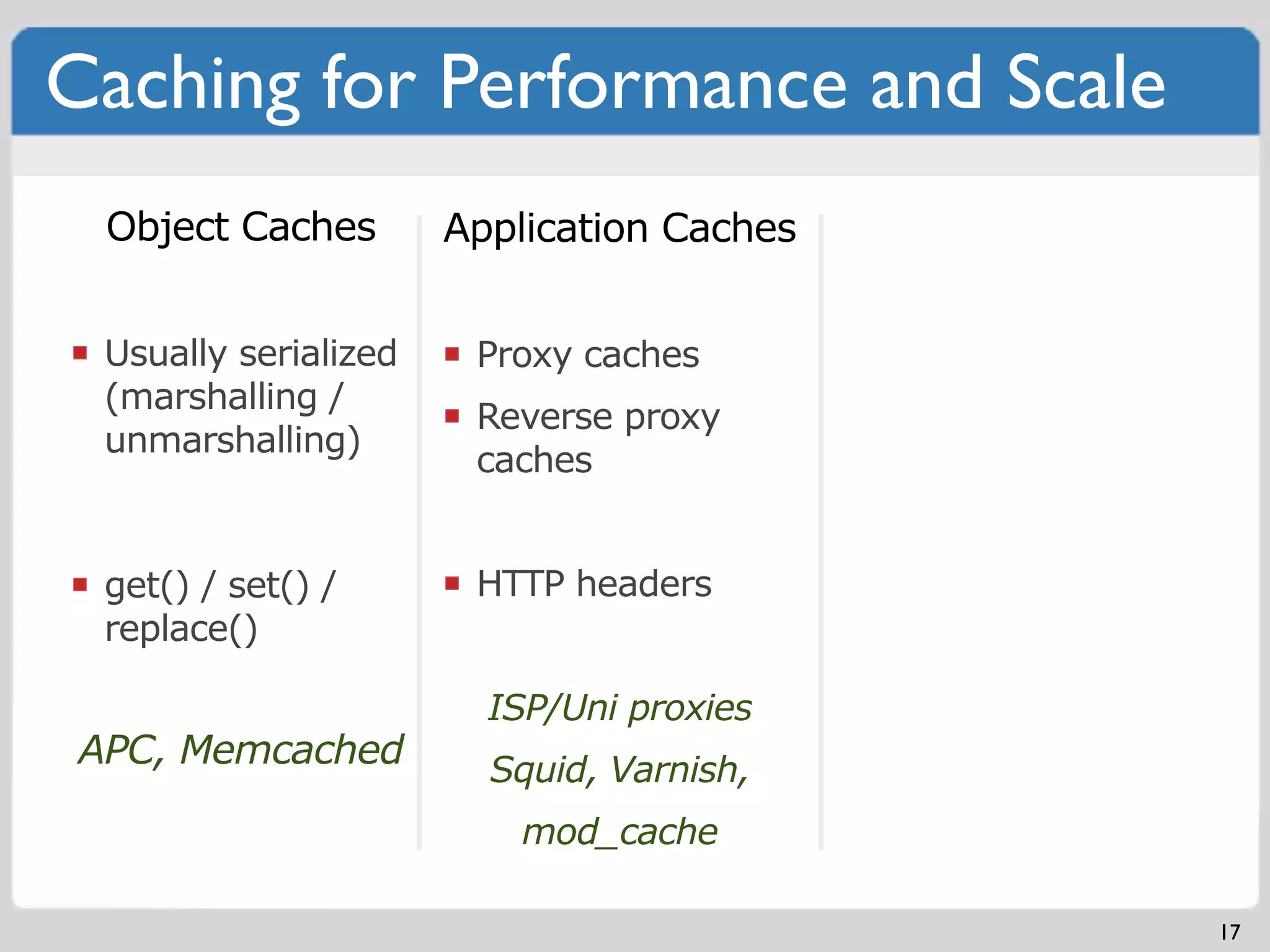
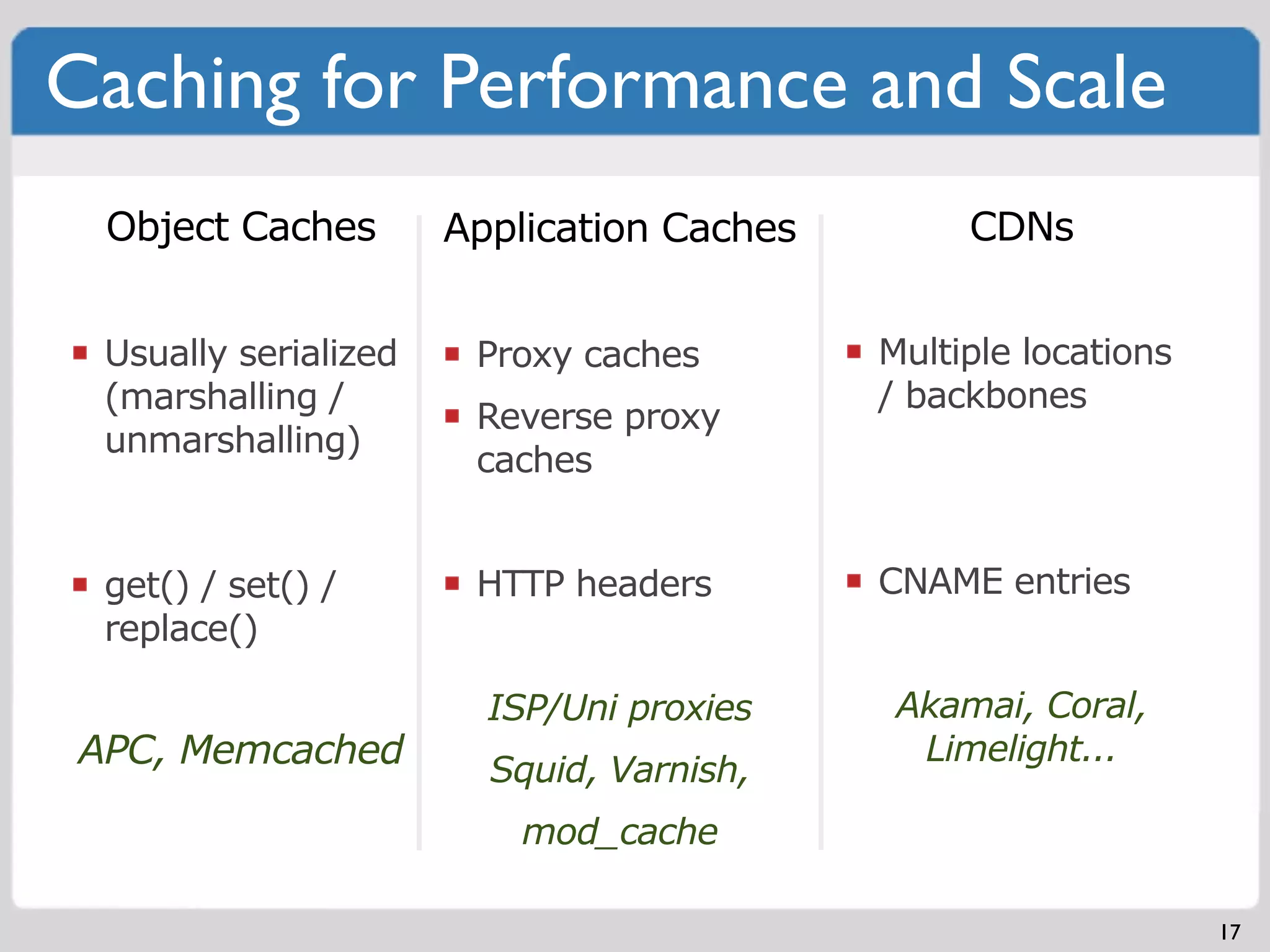
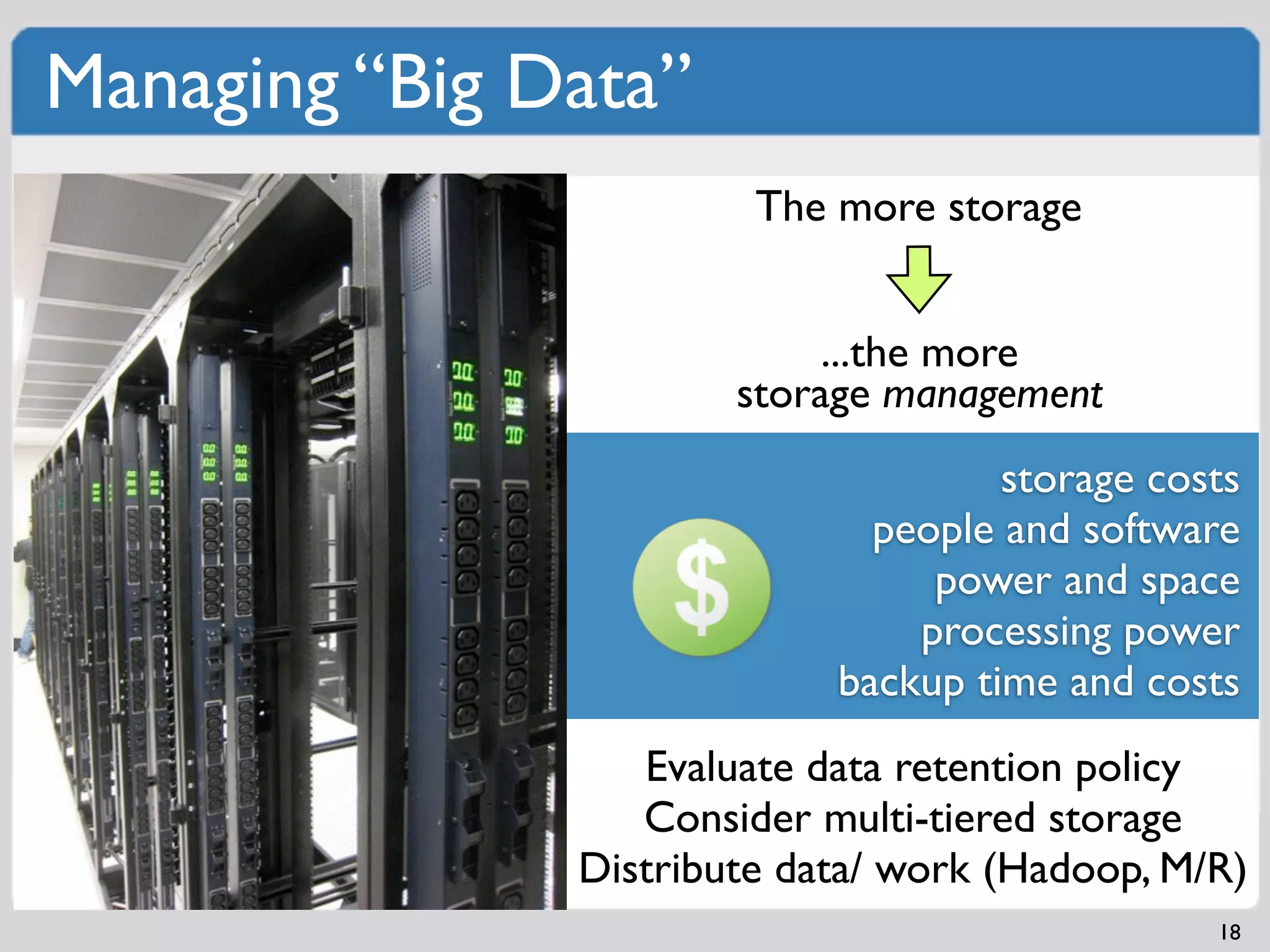
Implementing fault isolative structures to enhance system availability and debugging ease.Various caching methods (Object, Application, CDN) to improve performance and scale.Myriad factors in managing big data including costs, management, and storage policies.
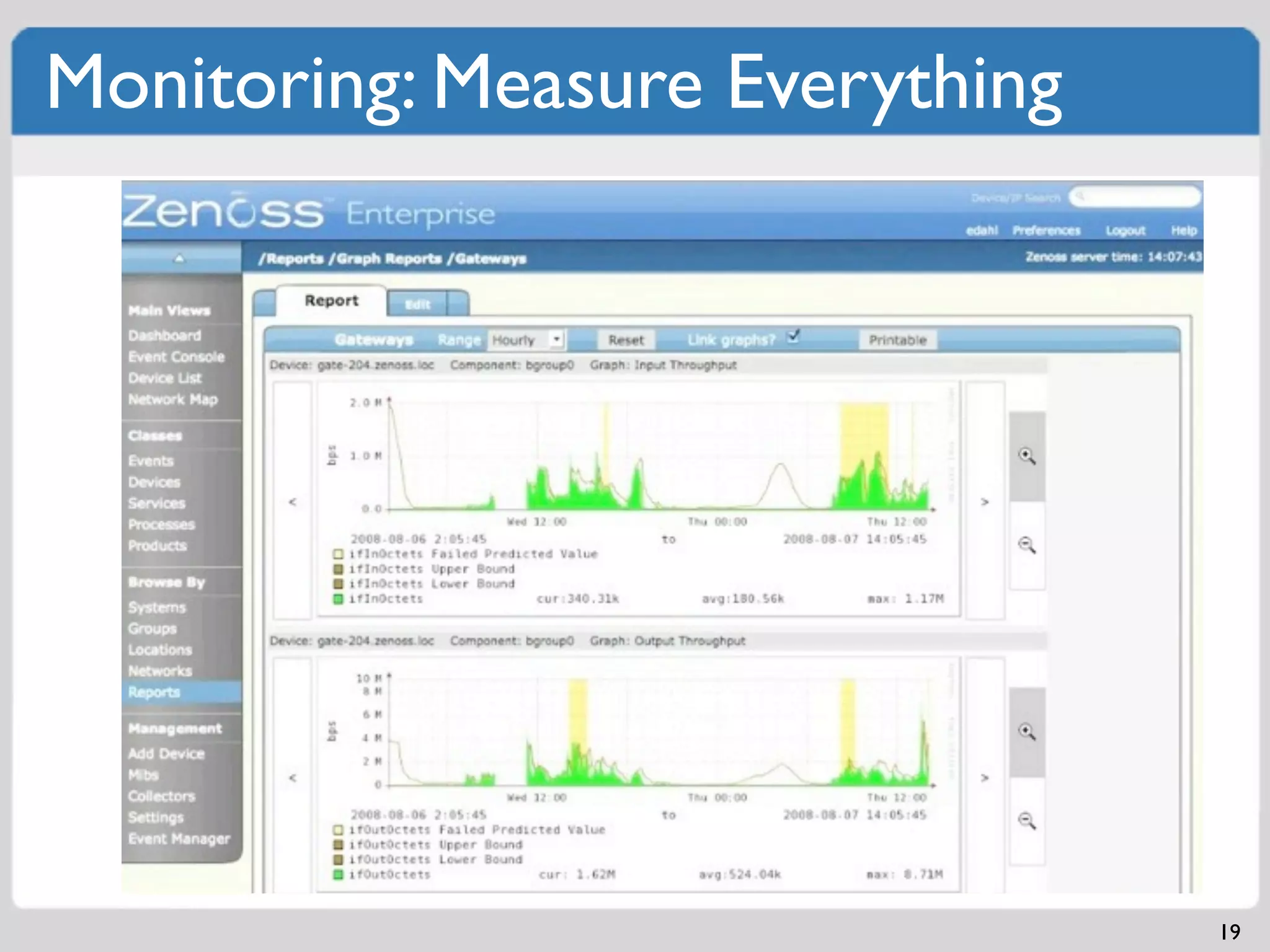
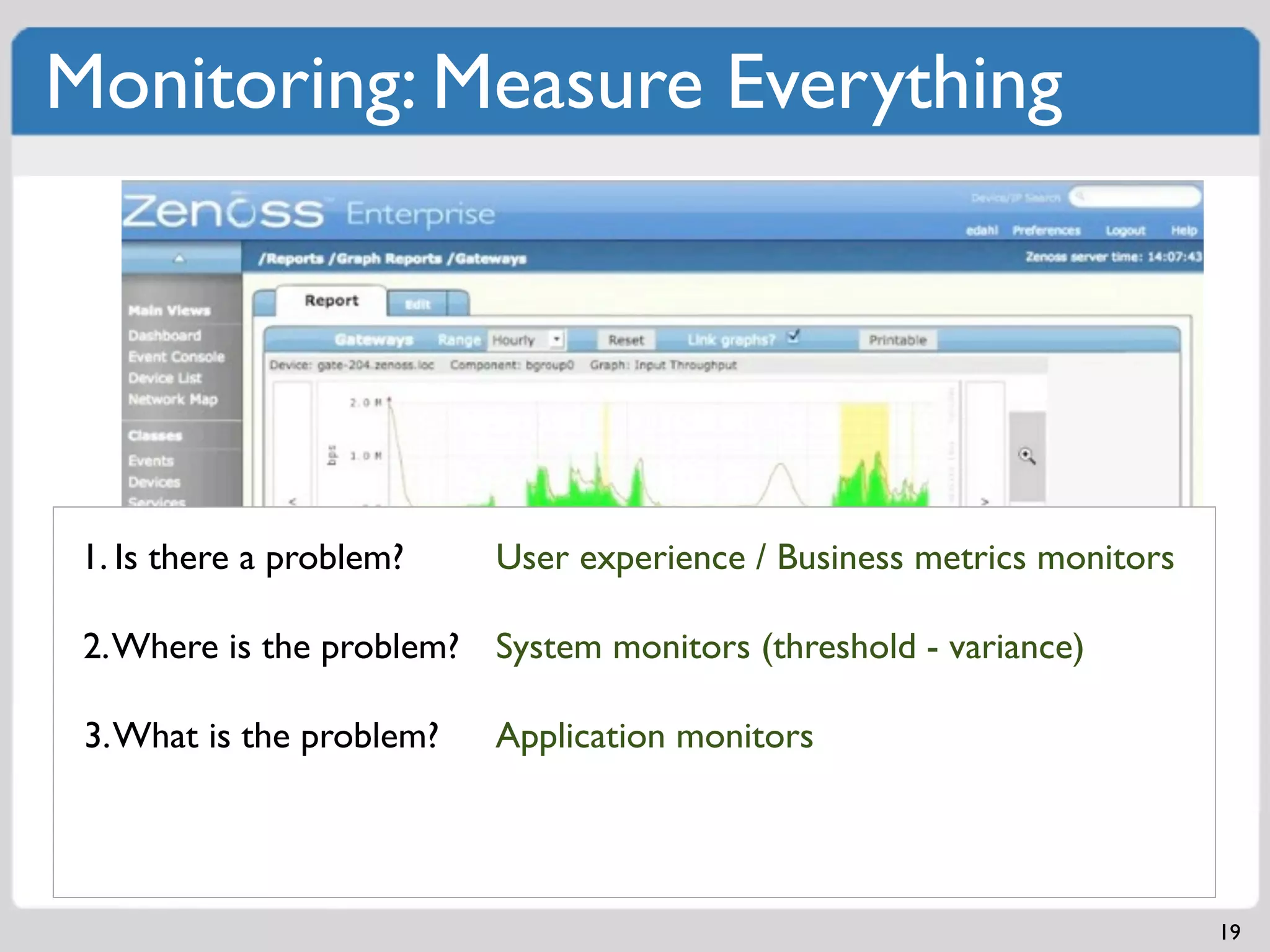
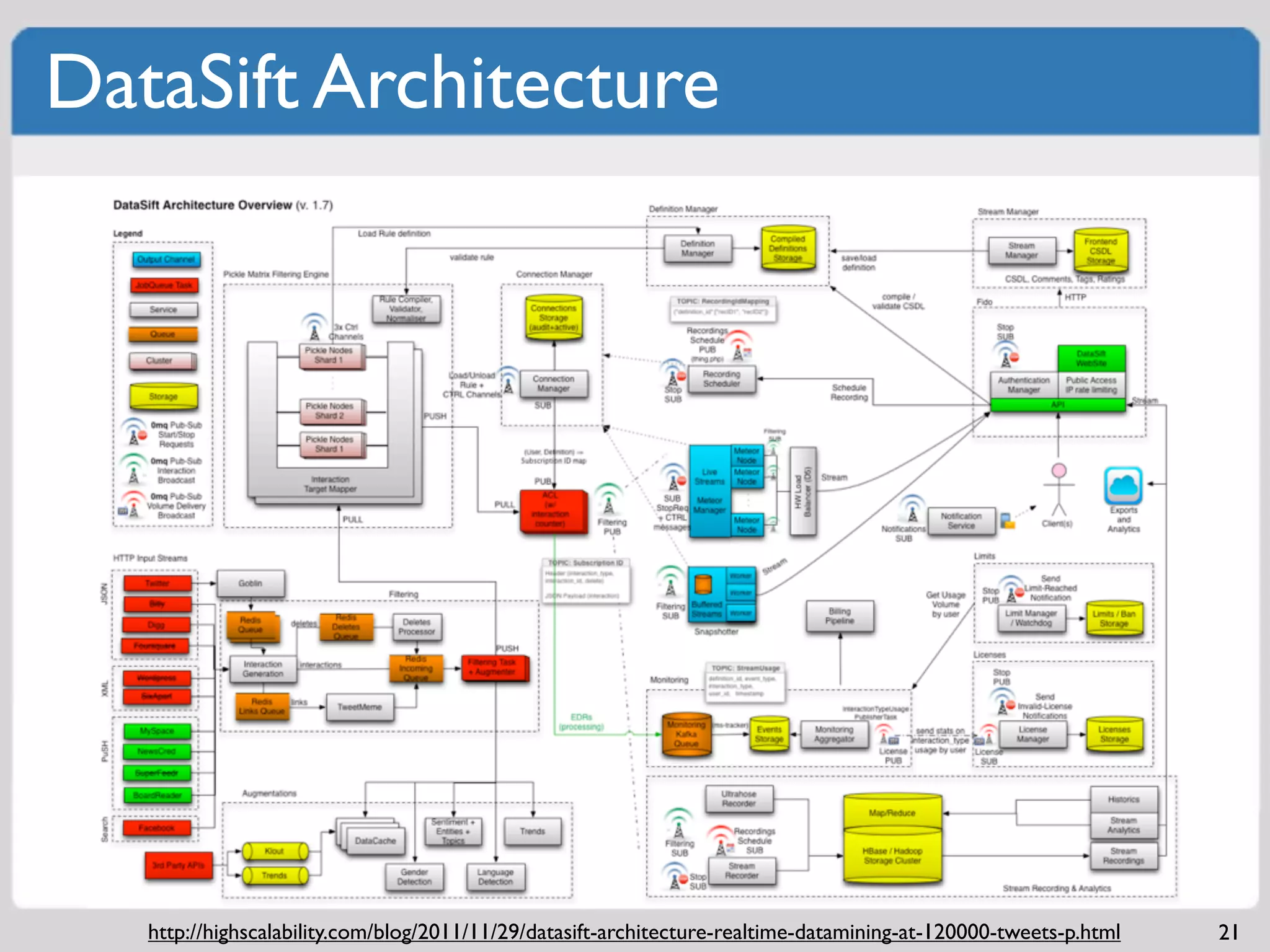
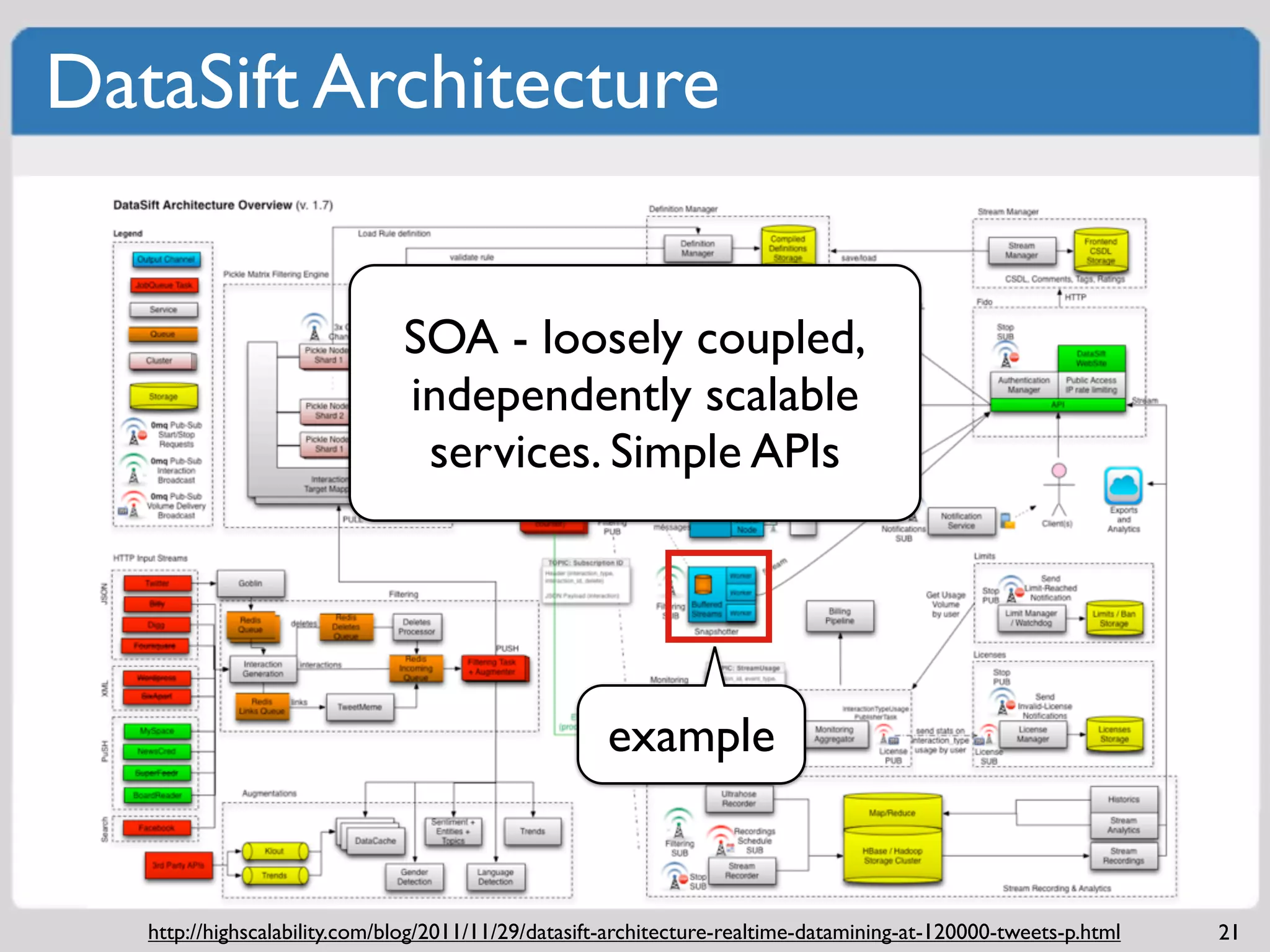
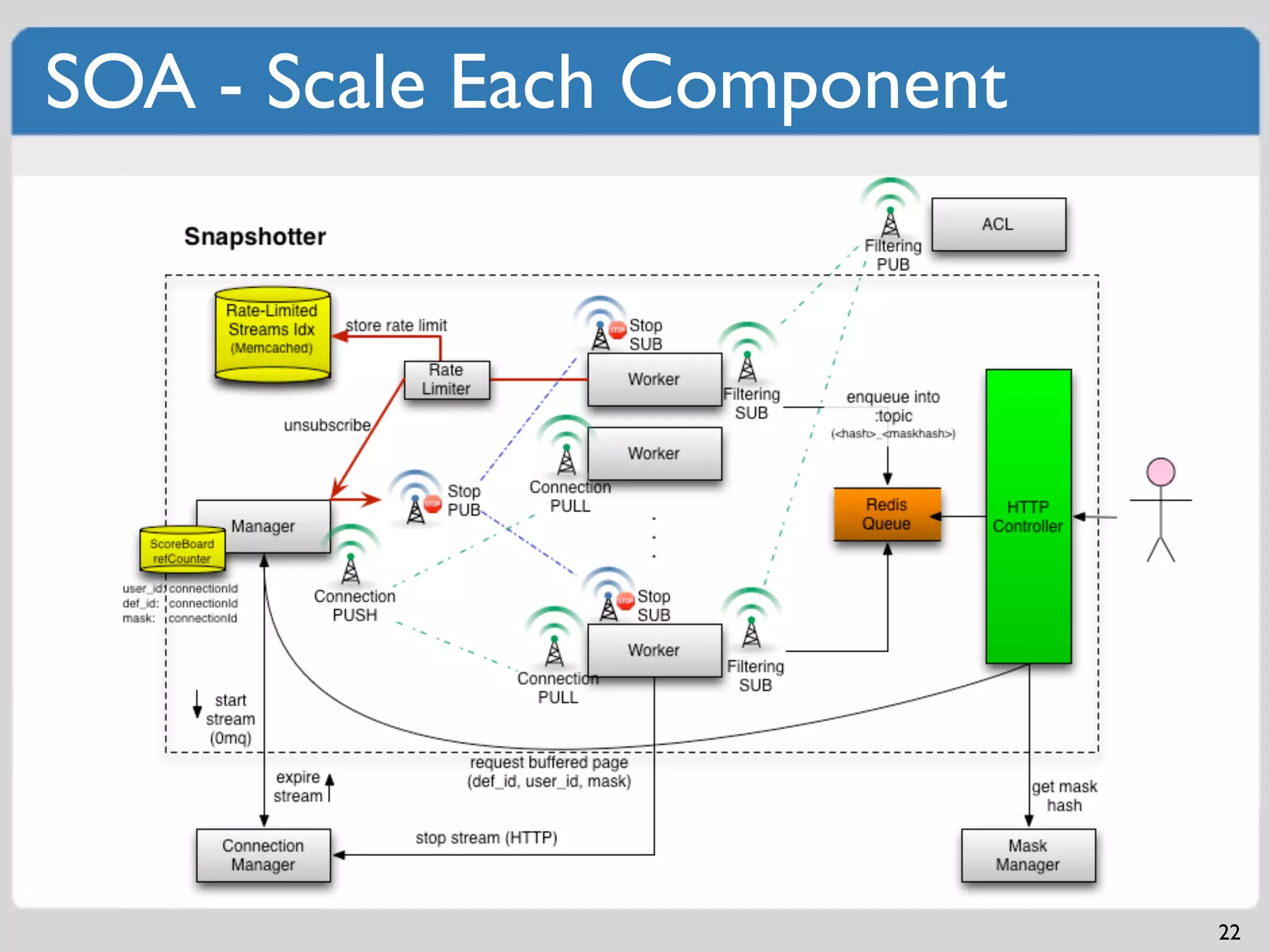
Comprehensive strategies to monitor systems and applications for identifying issues.Examples of software architecture demonstrating independent scalability and SOA principles.
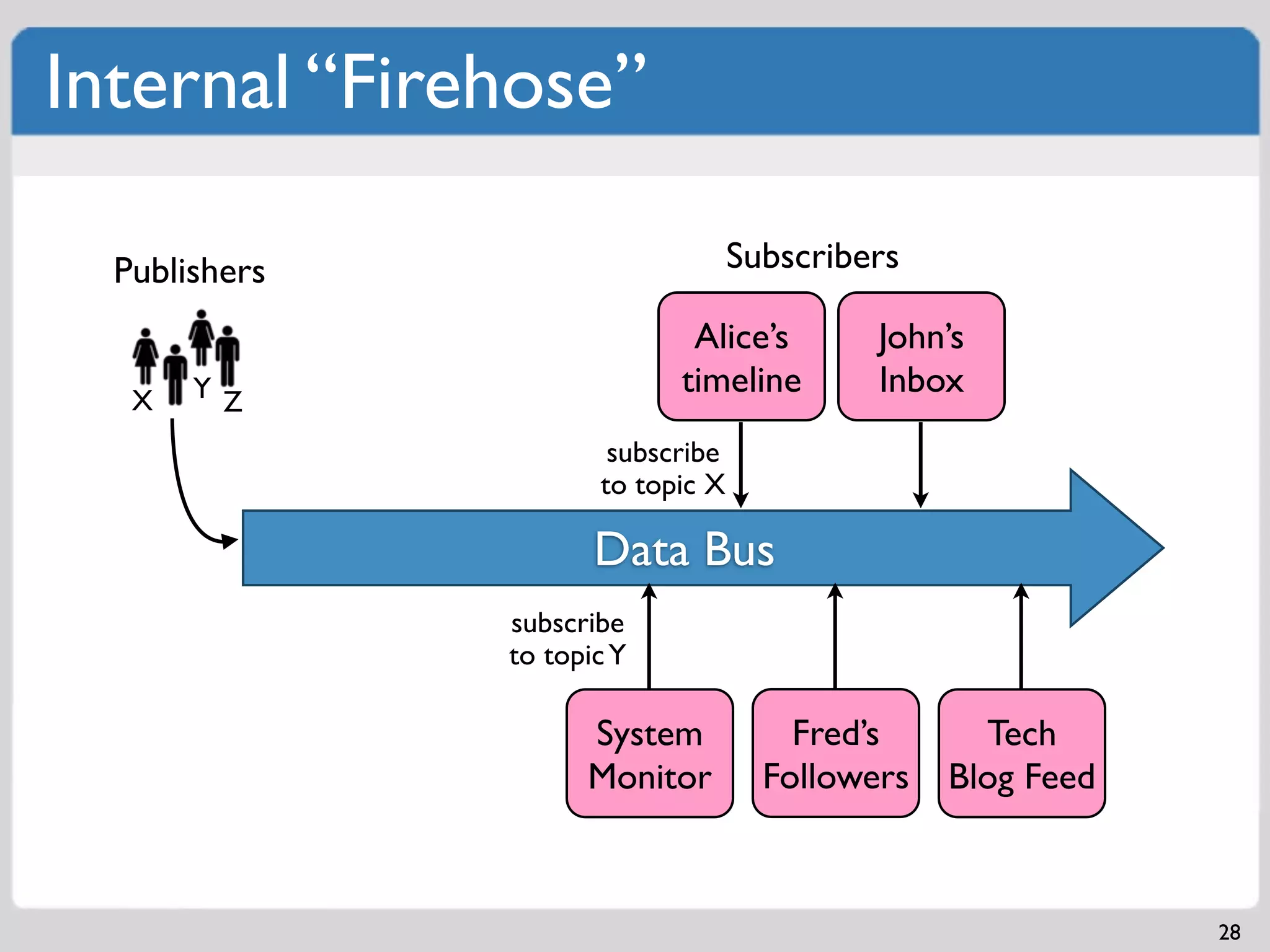
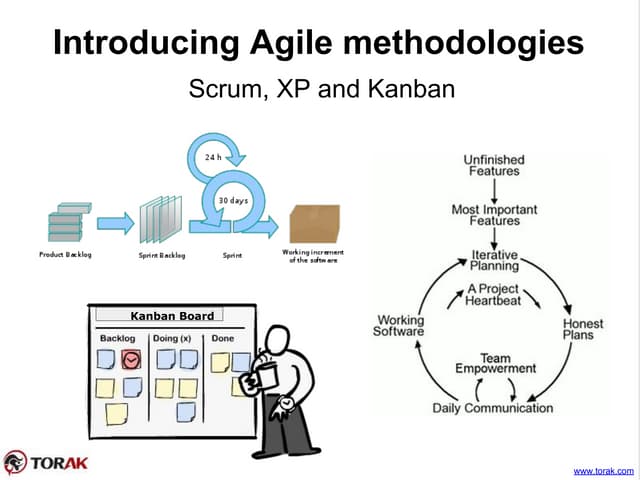
Messaging frameworks such as ZeroMQ and Kafka for workload processing and distribution.
Call for job applications, references, and contact details for further inquiries.




















































![Agile Developers Create Their Own Identity[1]](https://cdn.slidesharecdn.com/ss_thumbnails/agiledeveloperscreatetheirownidentity1-12795469184258-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















