


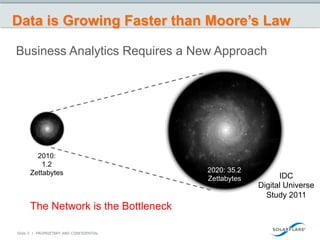
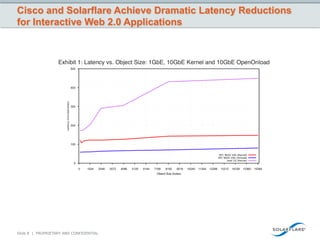
![But Computing is More than Just Moore’s Law
• SandyBridge-Based
Servers/ Aka Romley
Motherboards
• Intel Integrated I/0
Up to 4 channels
DDR3 1600 Mhz
• Reduced bottlenecks
memory
• Increase performance
Up to 8 cores
Up to 20 MB cache
up to 80%
Integrated
PCI Express*
3.0
Up to 40 lanes
per socket
Can more than Double
I/O Performance1
Xeon
Direct Data I/O (DDIO) 2600
Family
Xeon
5600
Series
[ Transactions per second ]
Slide 4 | PROPRIETARY AND CONFIDENTIAL](https://image.slidesharecdn.com/bigdatasmarternetworks-120620161442-phpapp02/85/Big-Data-Smarter-Networks-4-320.jpg)
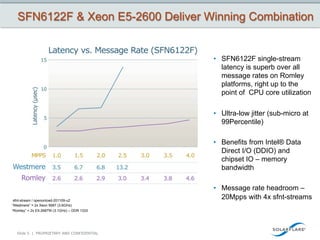
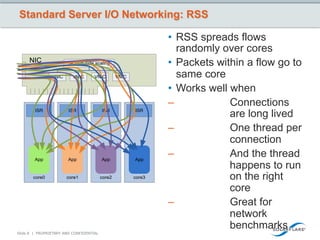
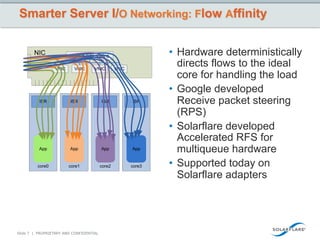
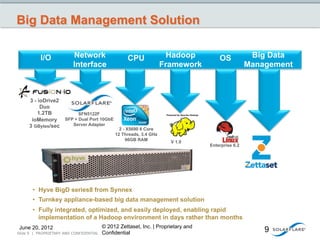


This document discusses how big data is growing faster than Moore's law and how the network is becoming a bottleneck. It introduces Solarflare as a company providing high-performance networking solutions for applications handling big data workloads. Solarflare's products are optimized for financial services, HPC, storage and cloud/web applications. The document highlights how Solarflare's hardware and software can optimize network performance and reduce latency compared to standard server networking approaches. It also provides an example of a turnkey big data management solution leveraging Solarflare's networking products.


















































































