




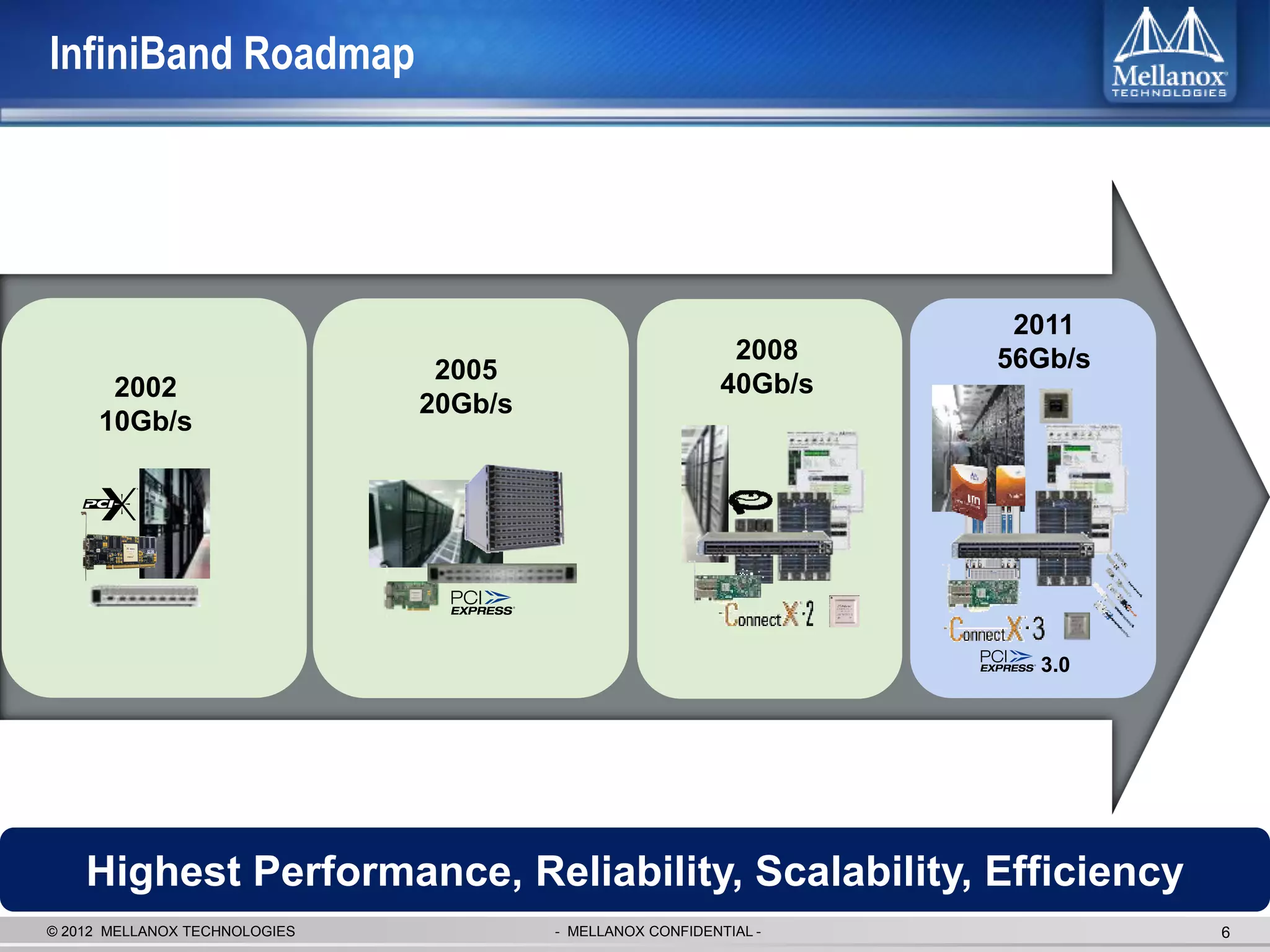

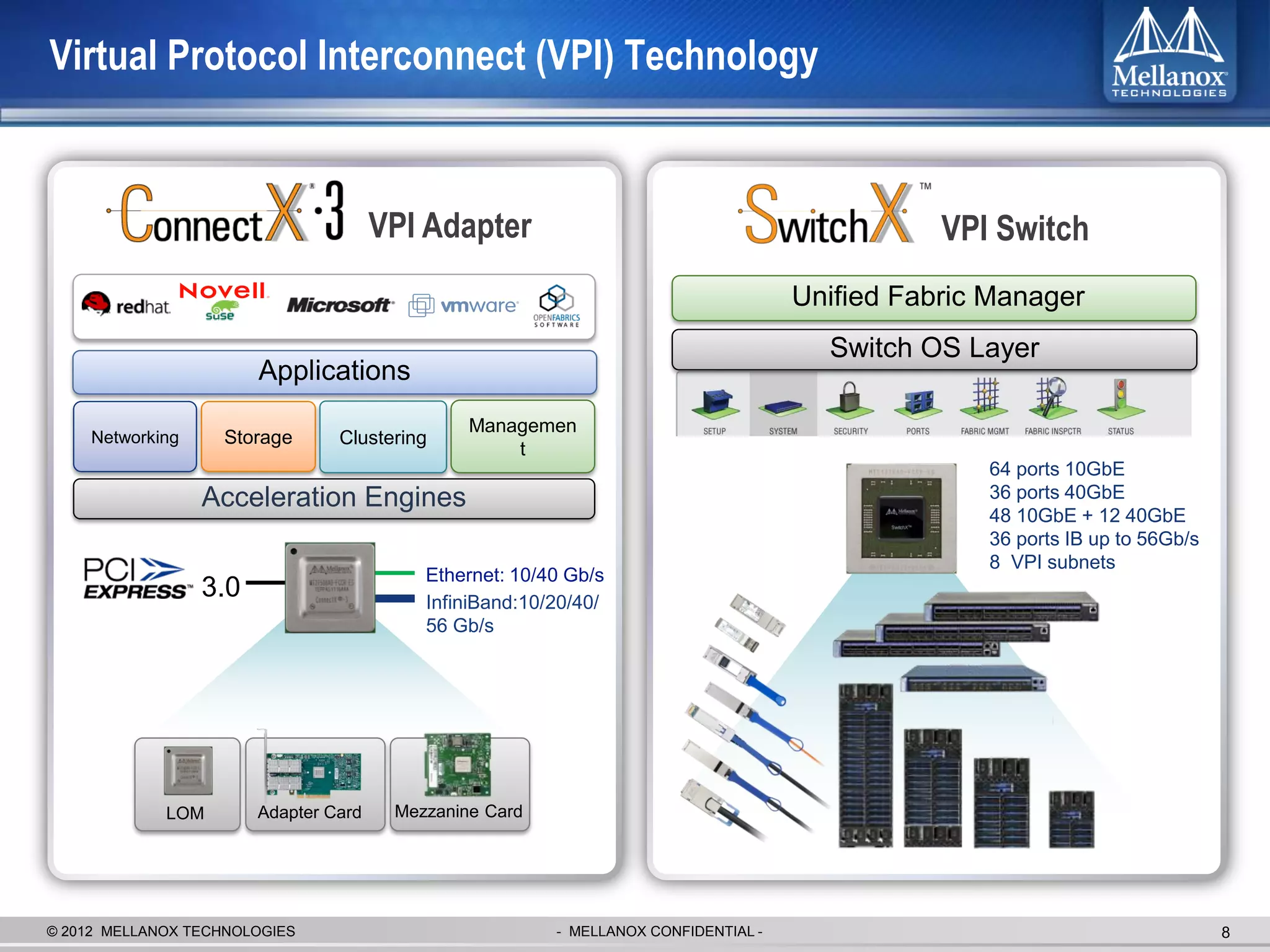
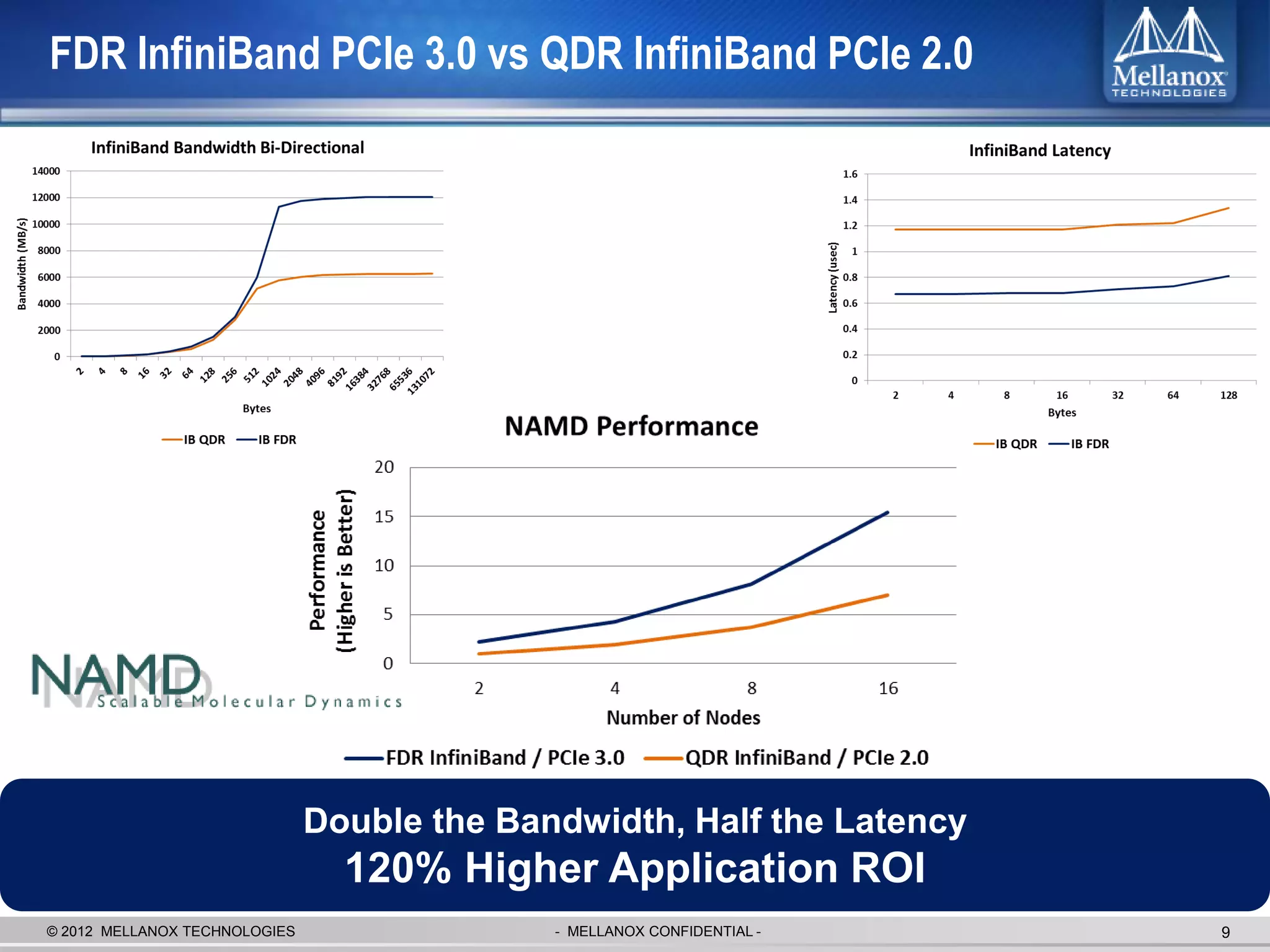
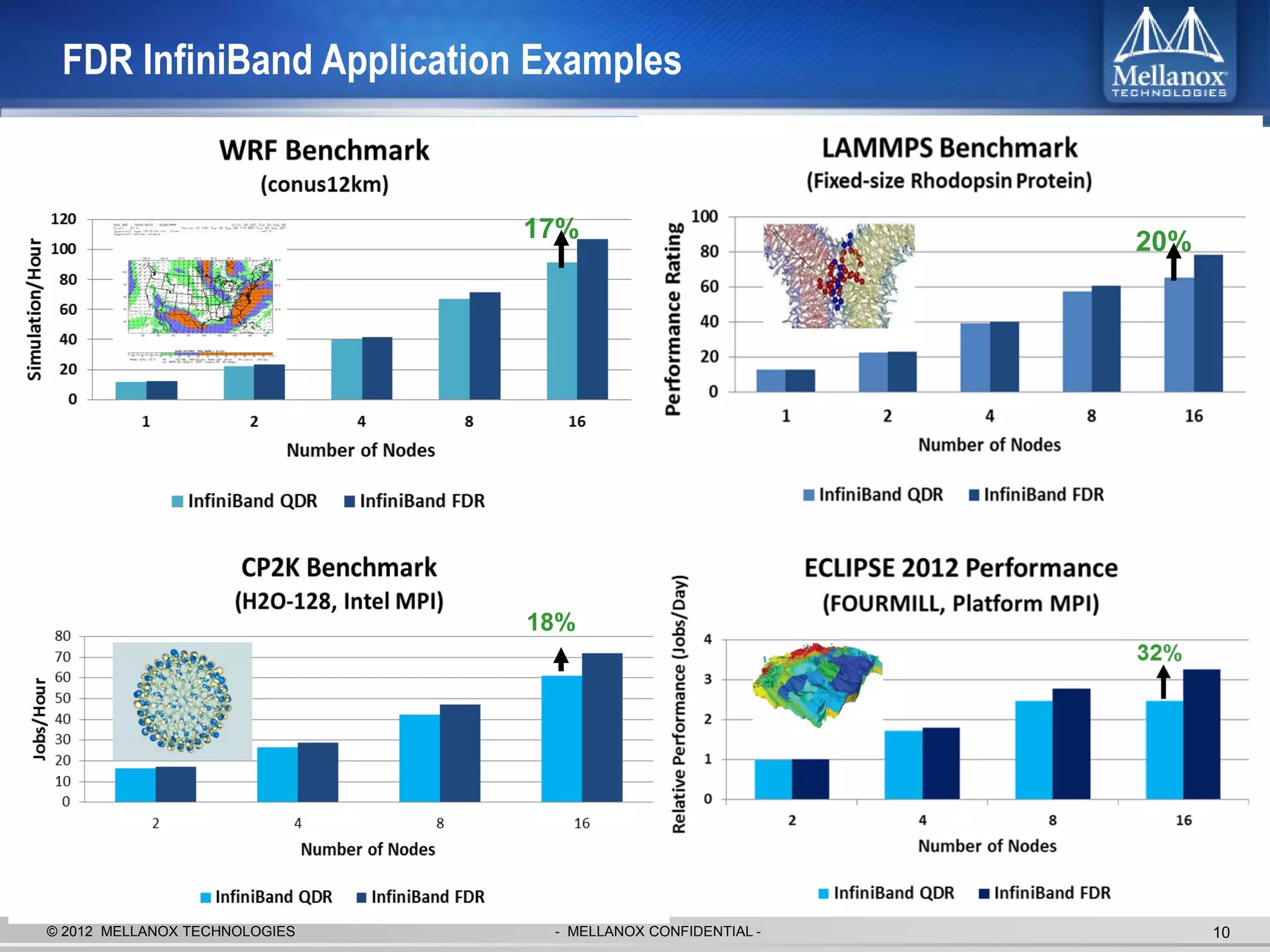
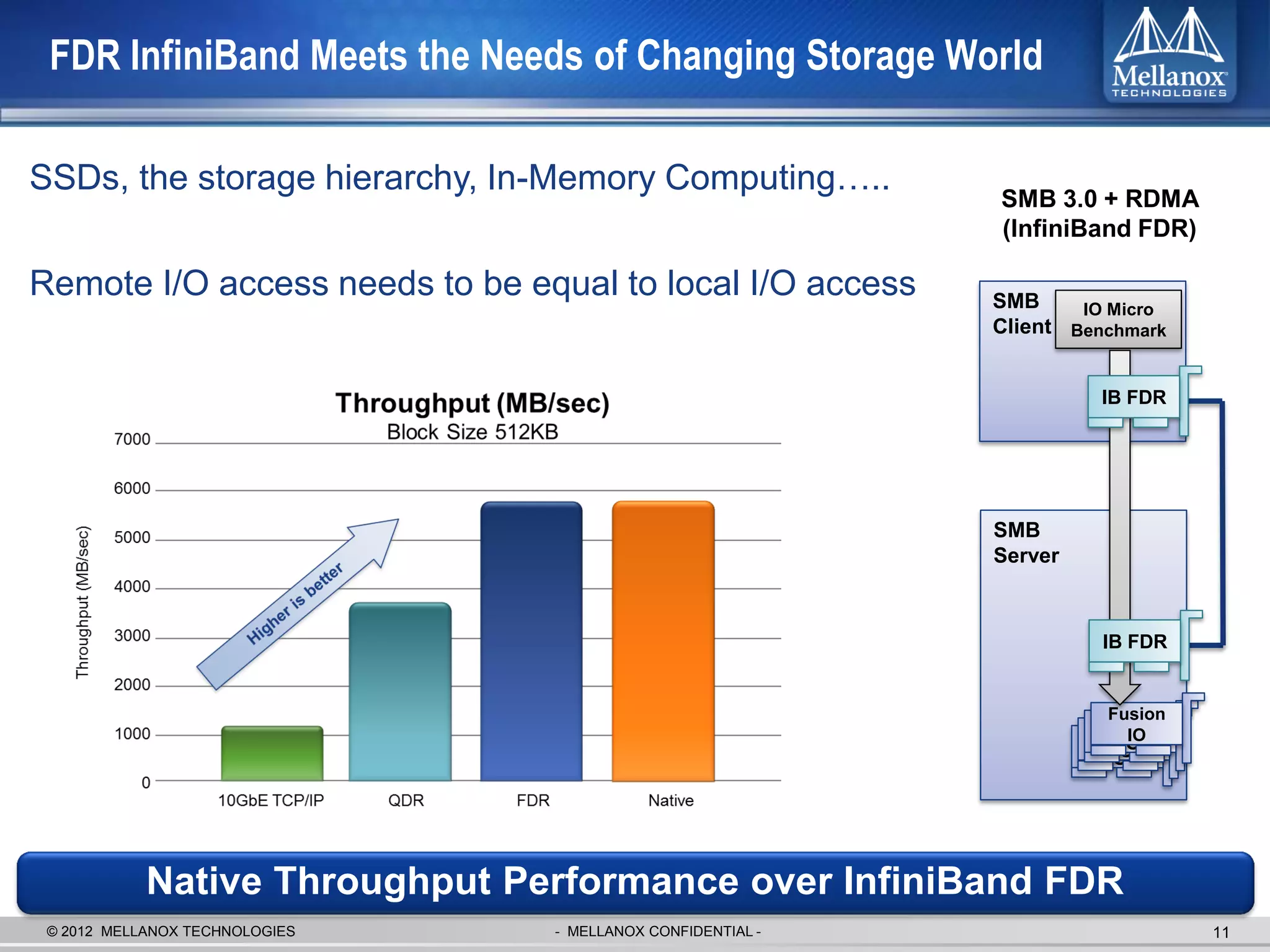
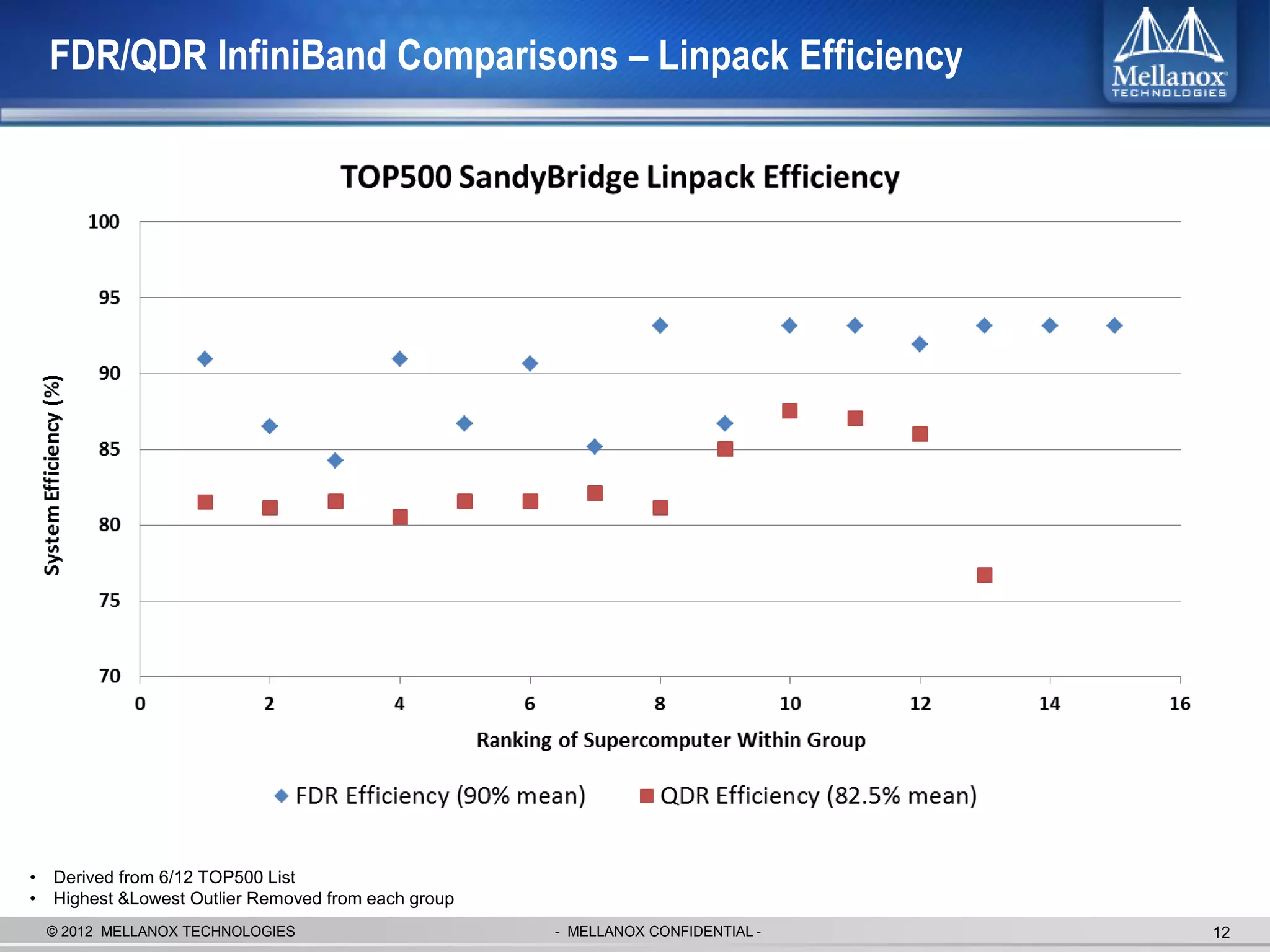

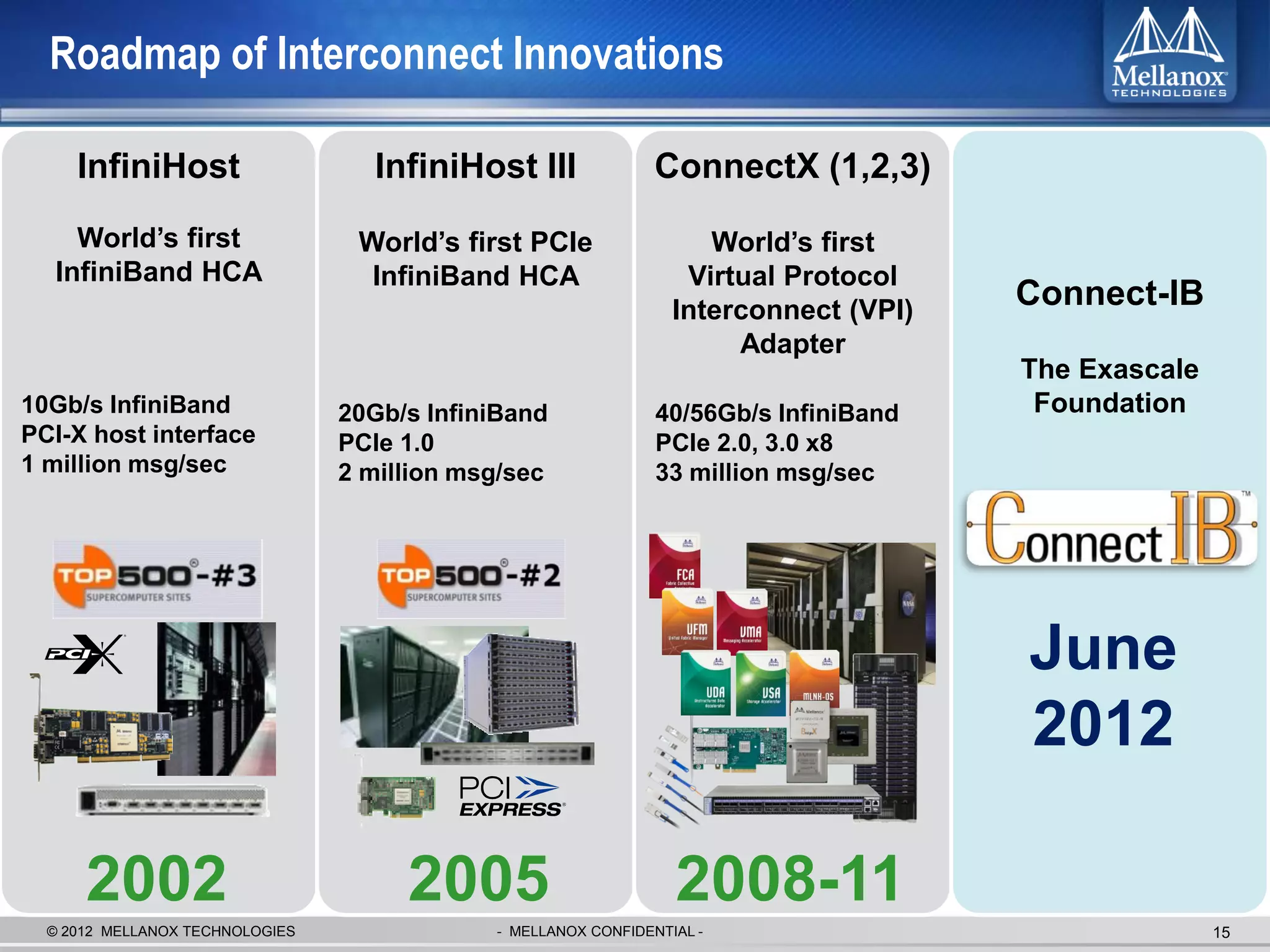


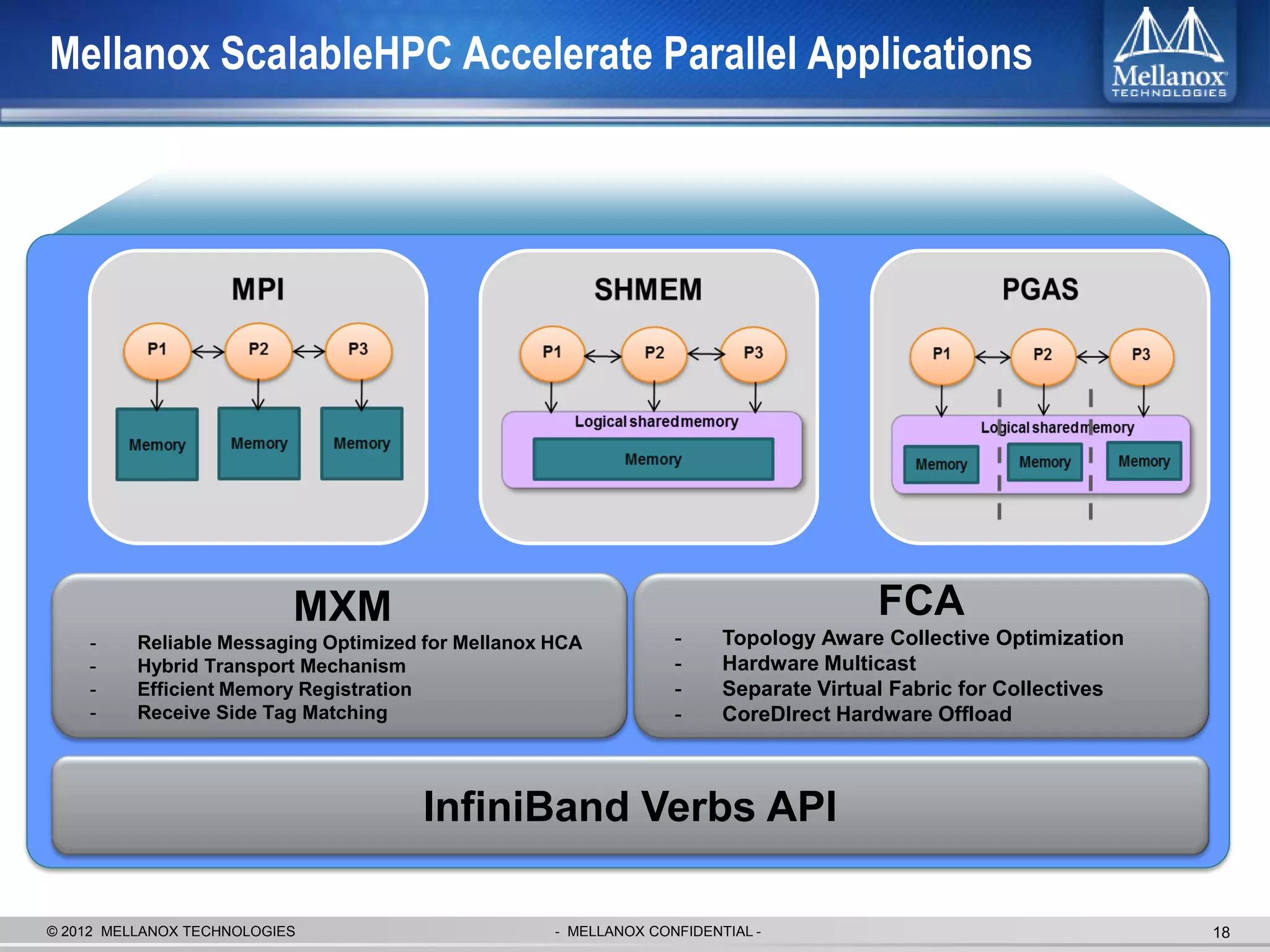
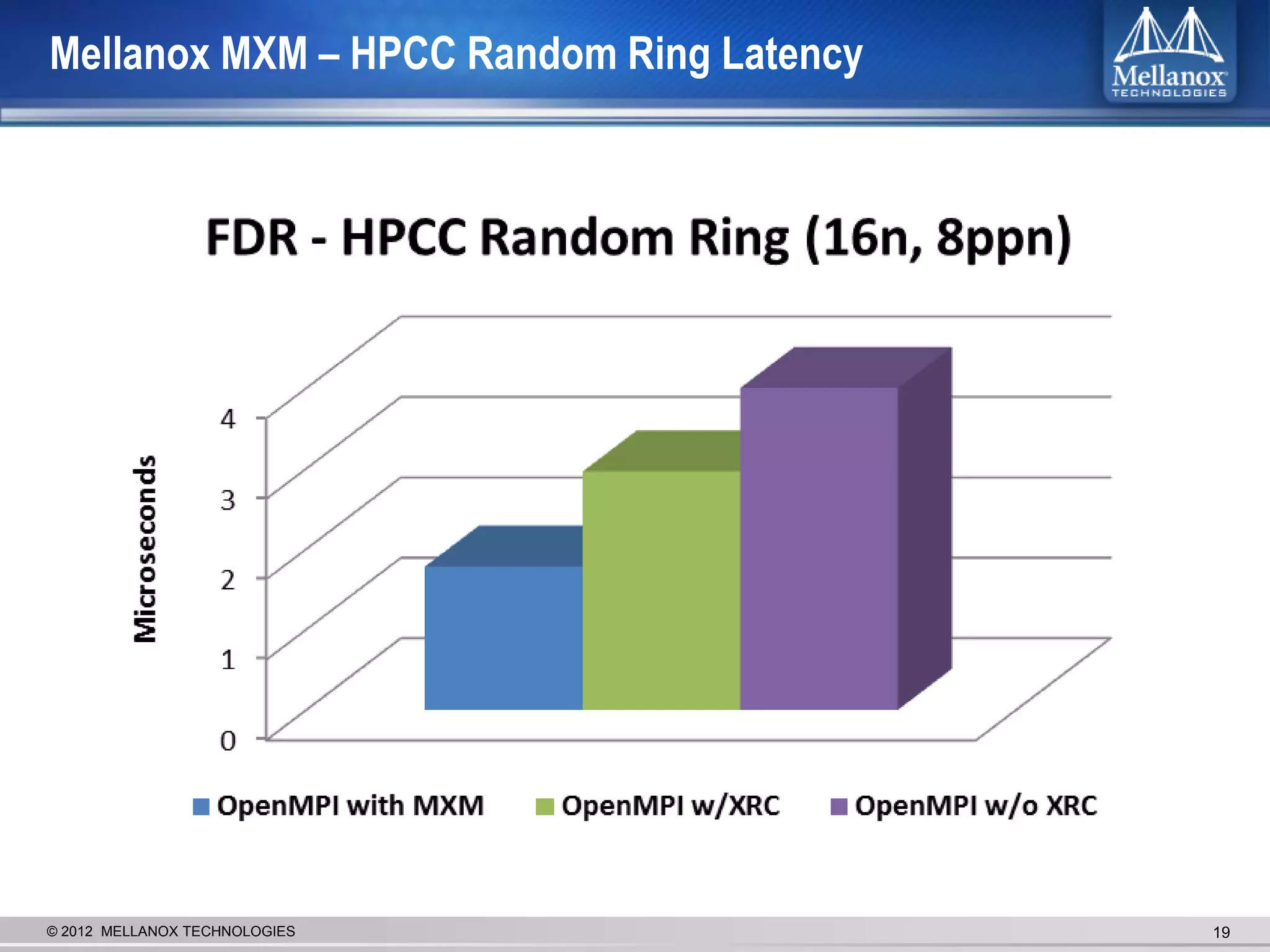
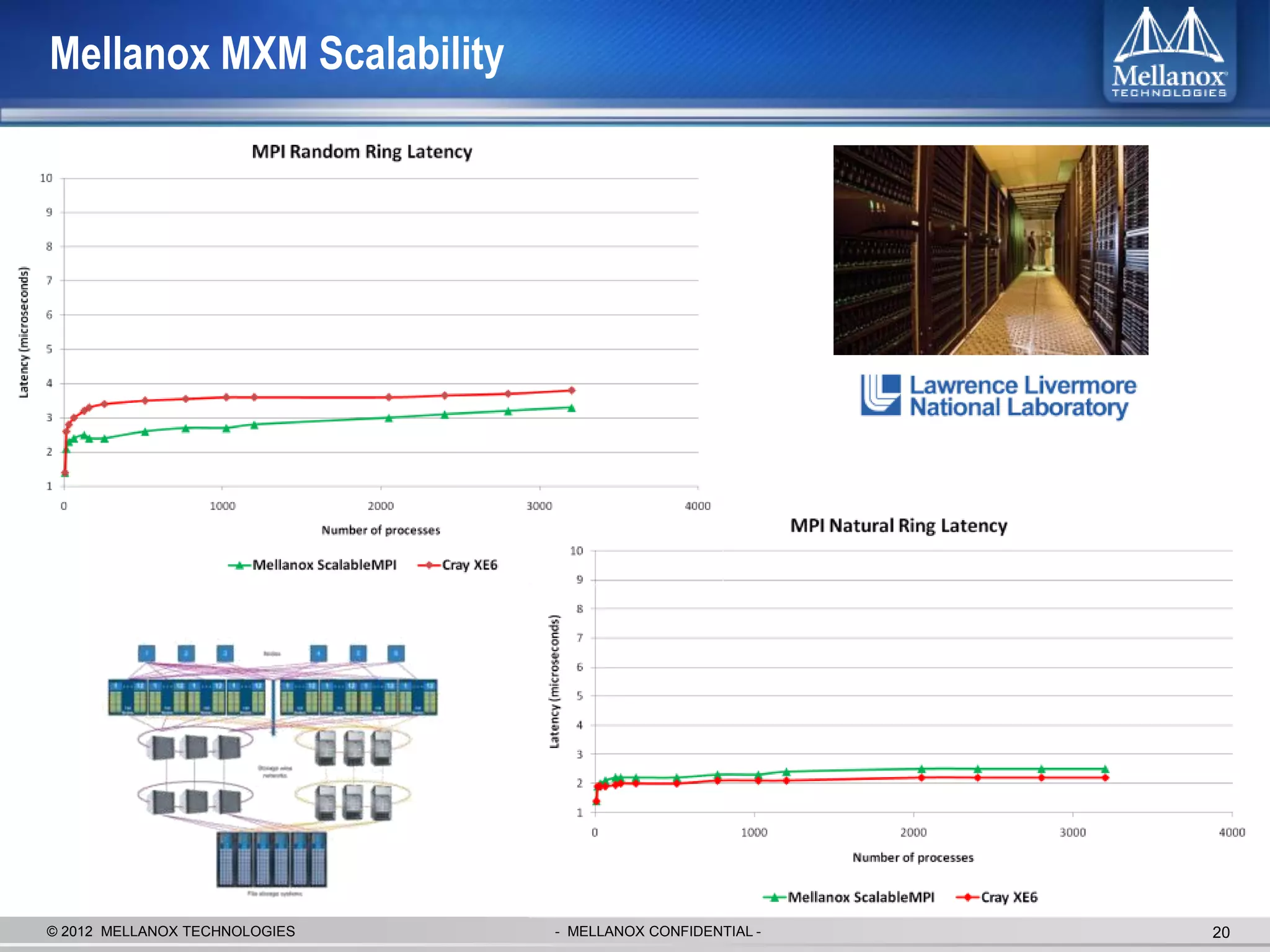
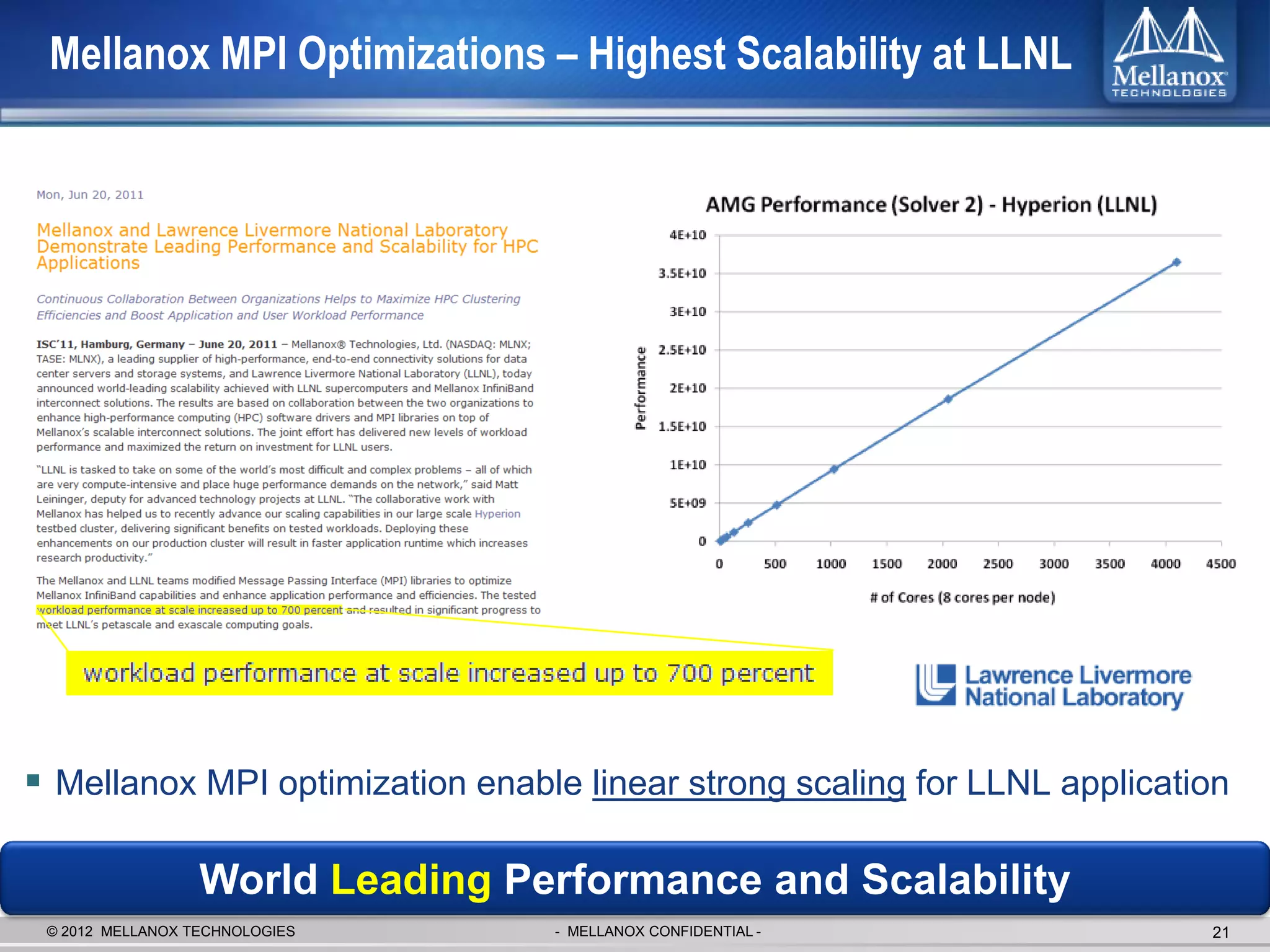

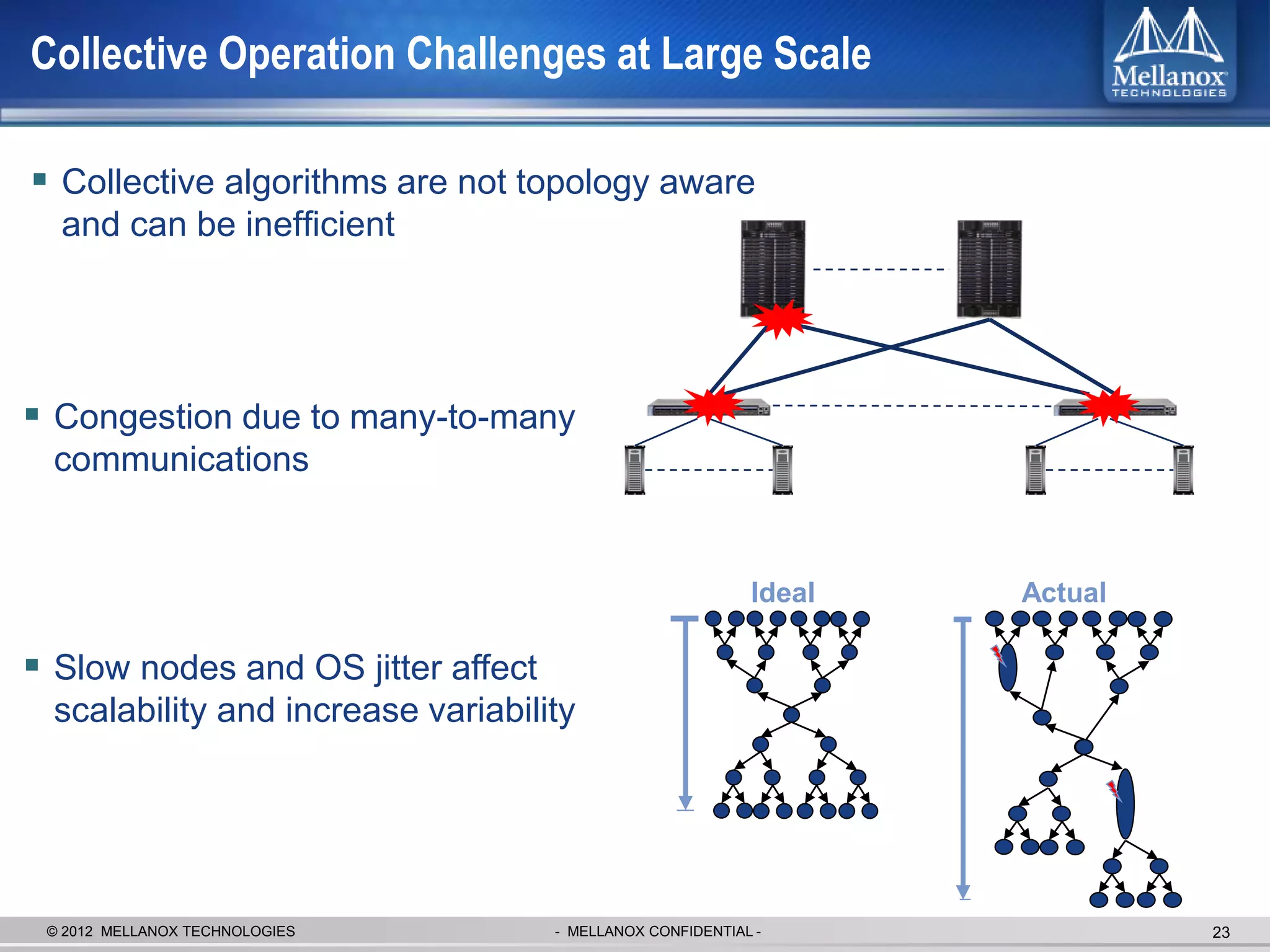

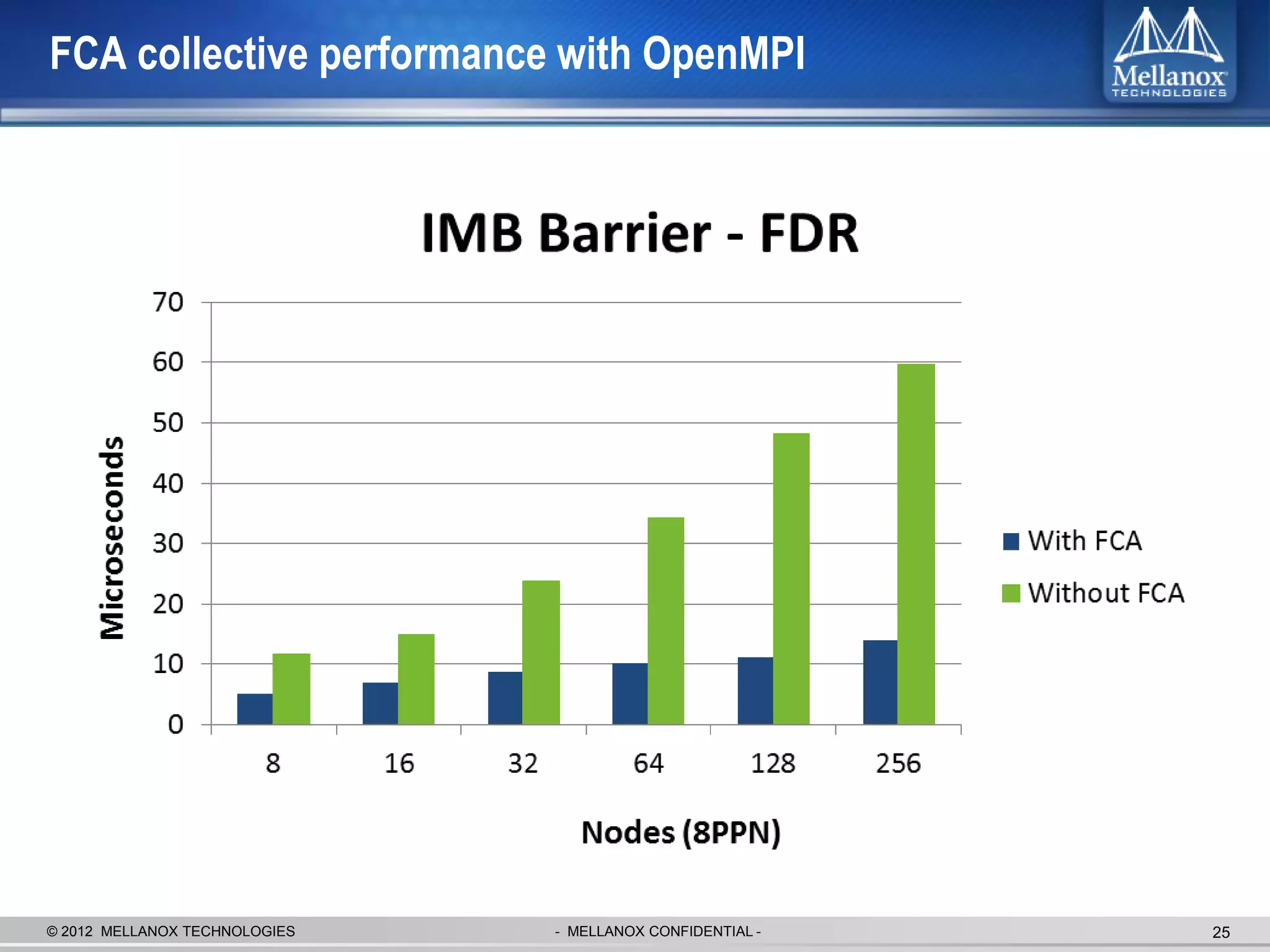
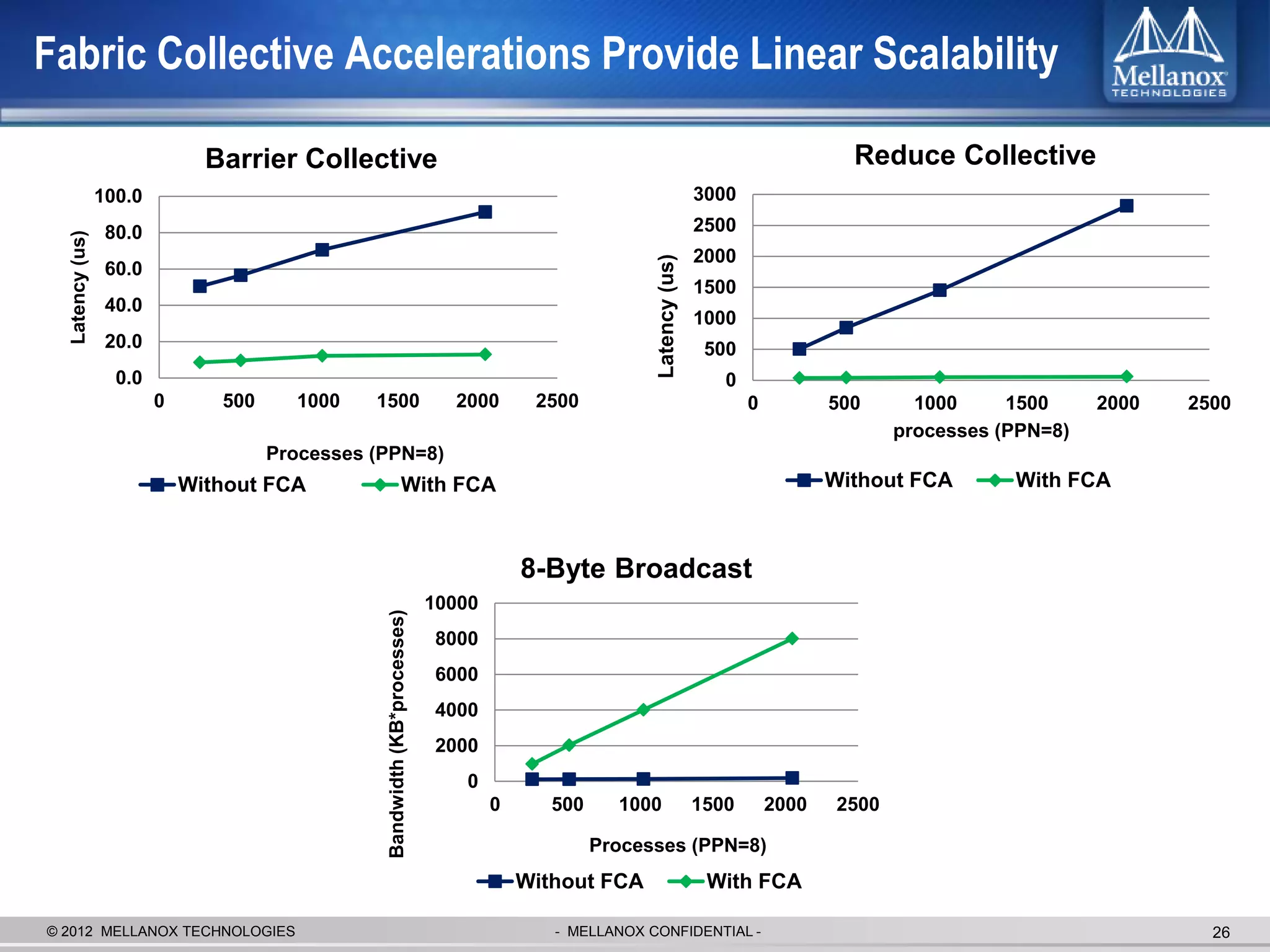
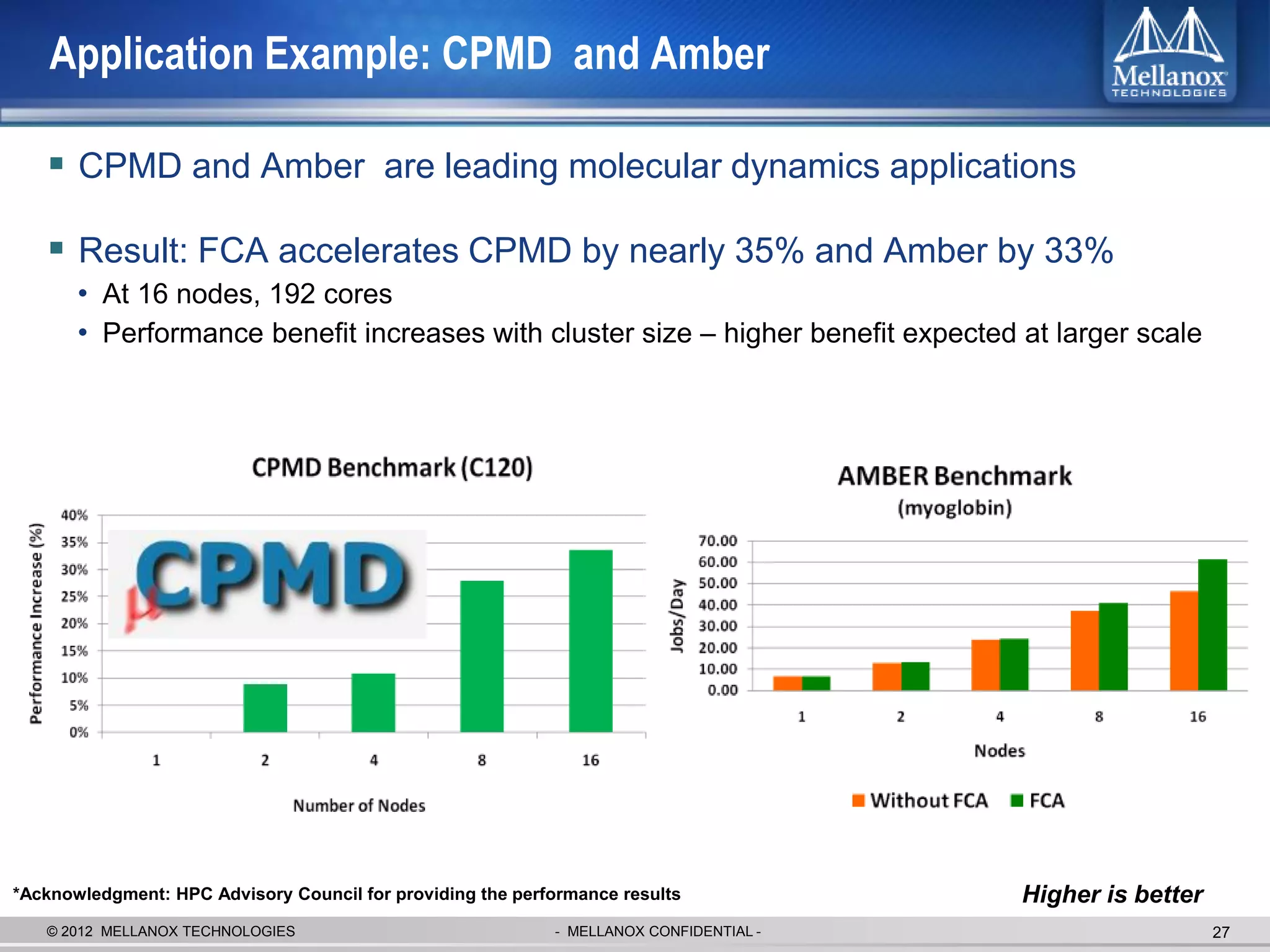

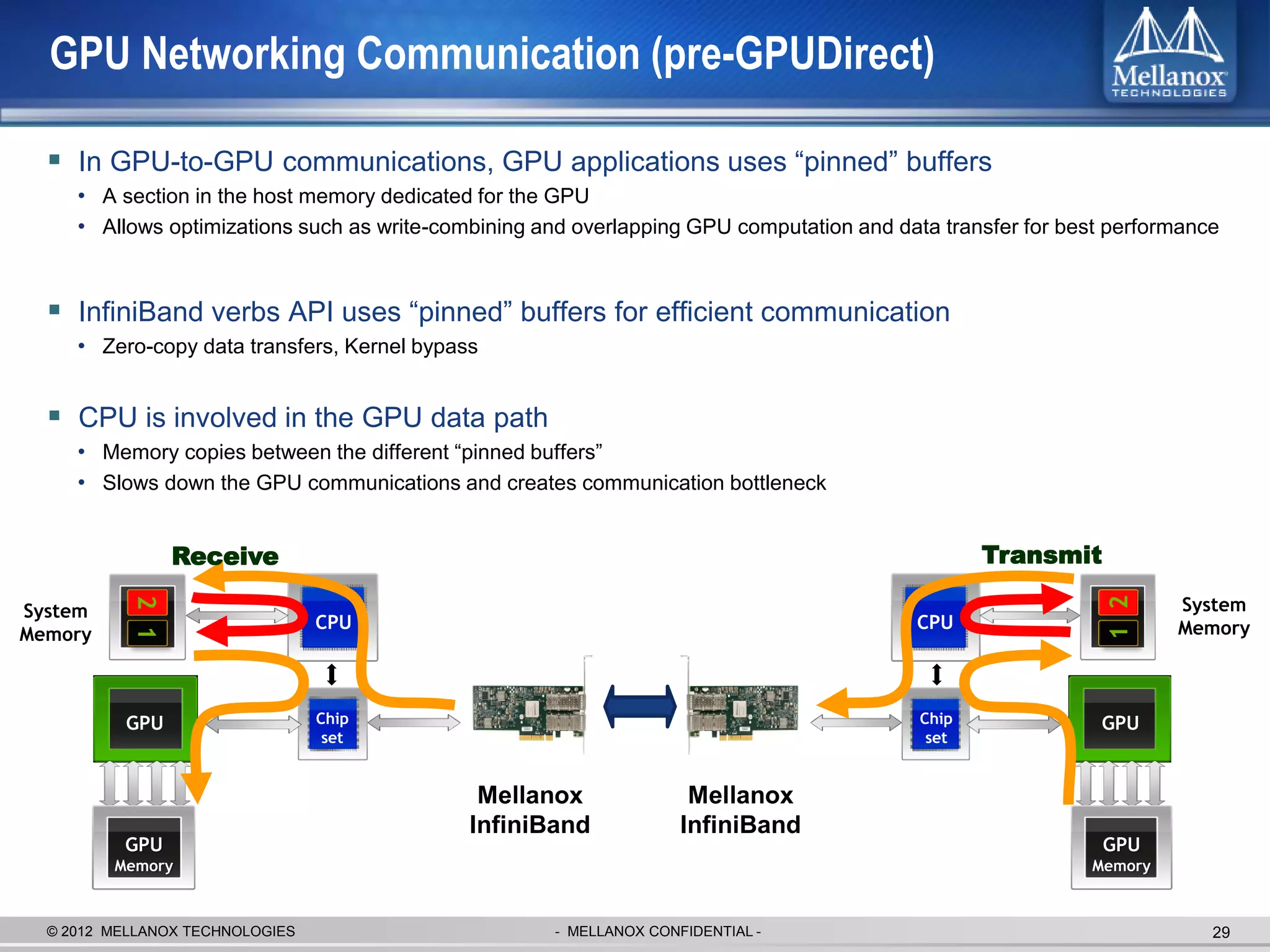
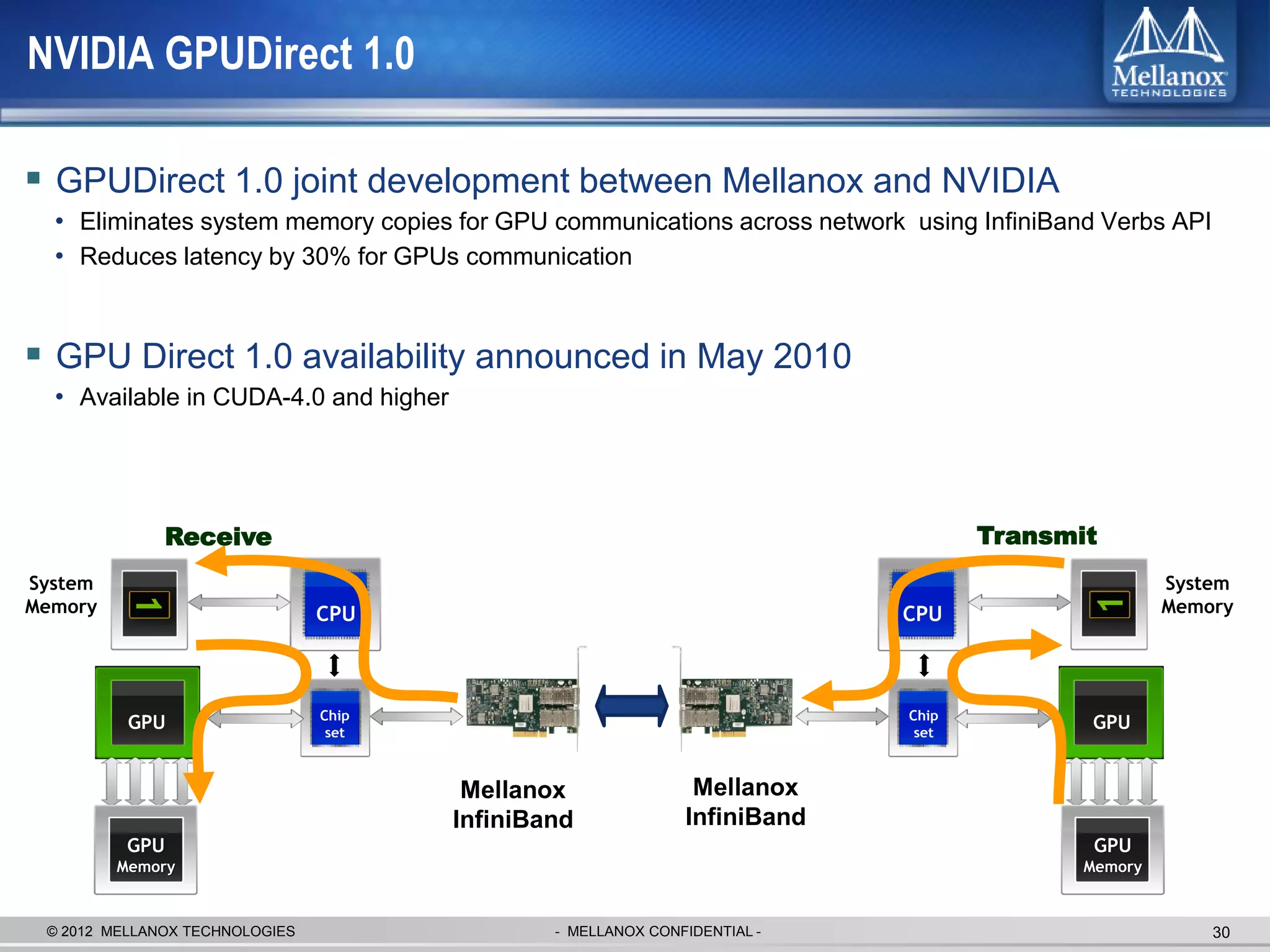
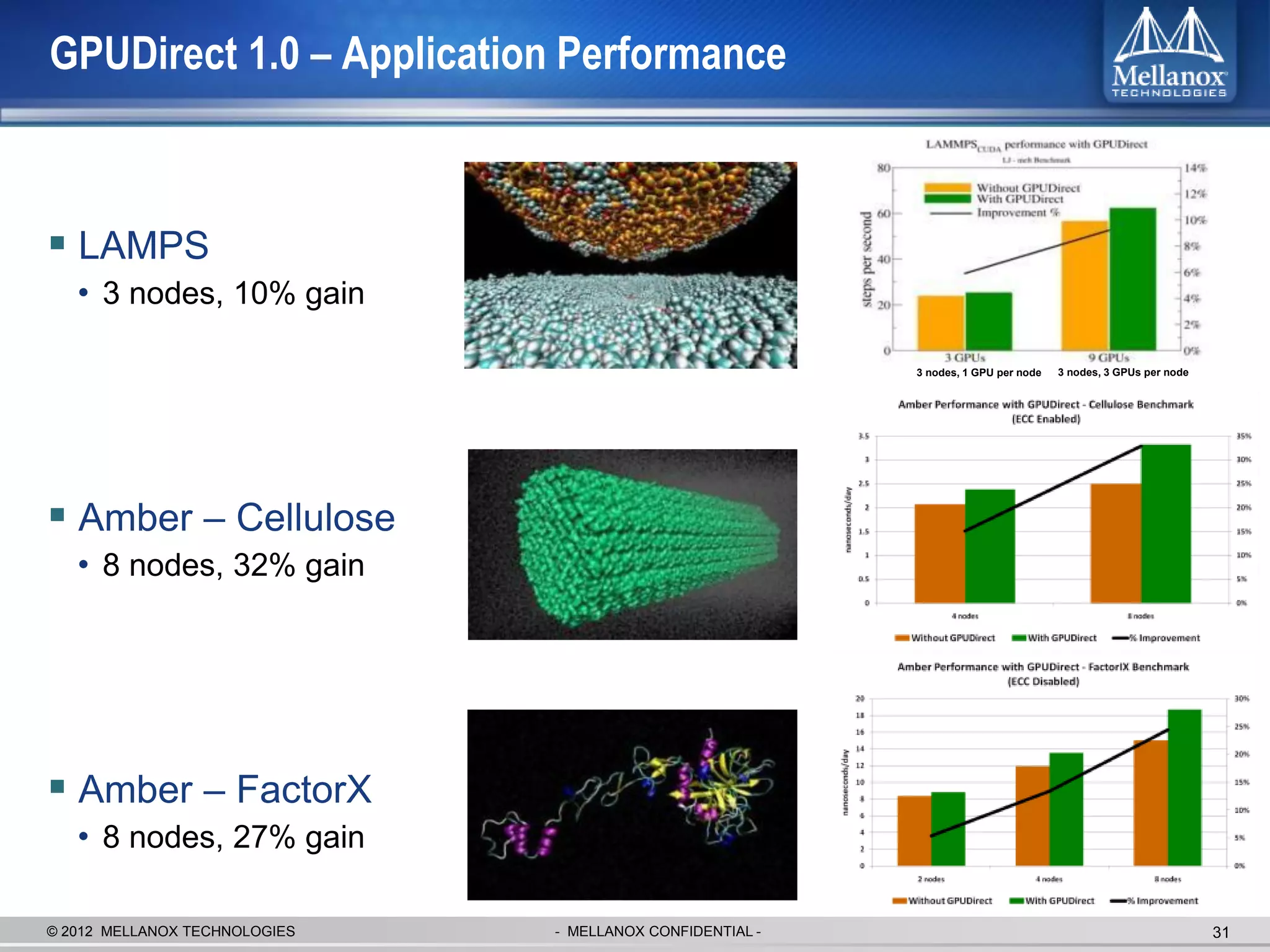
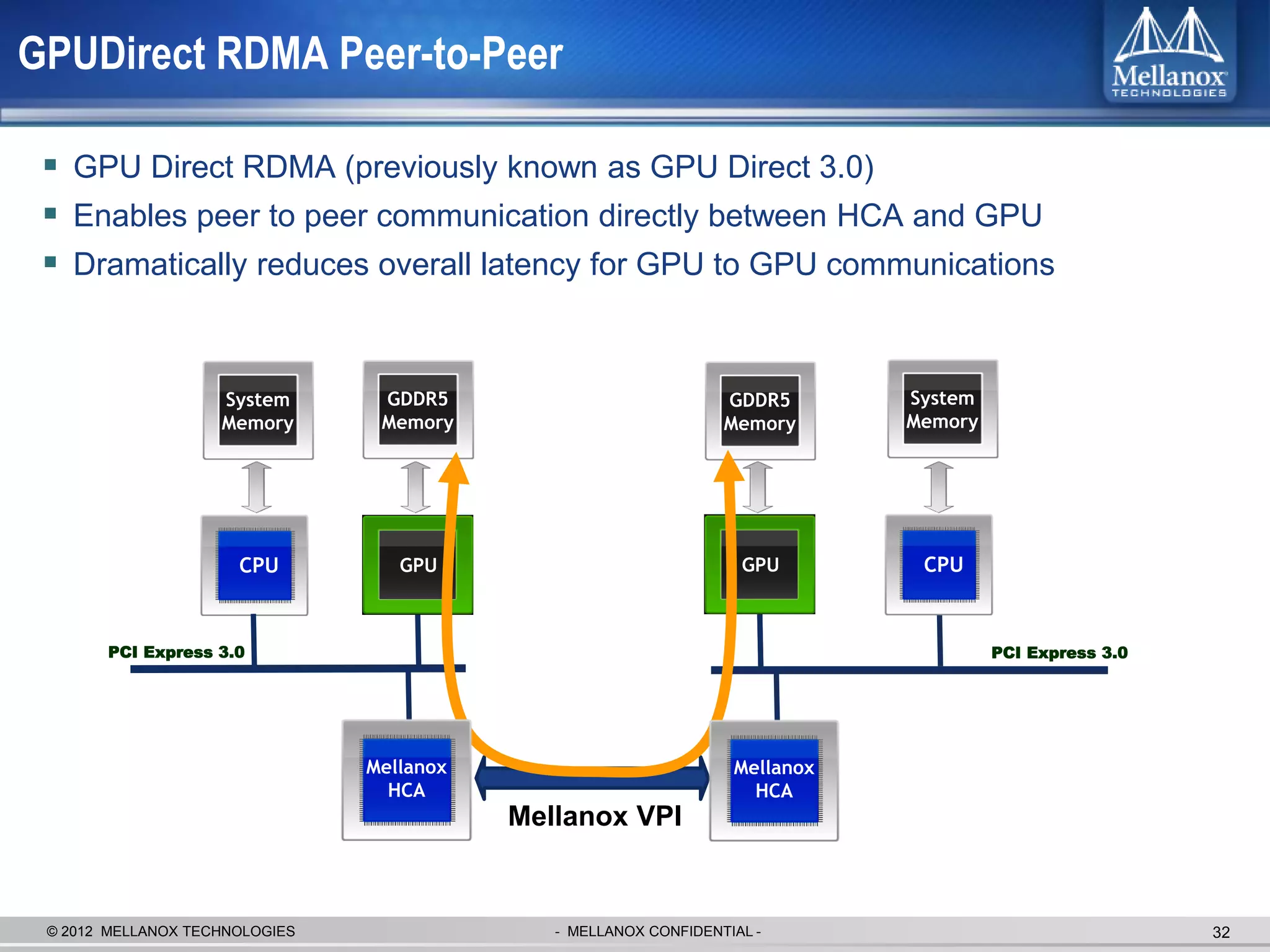

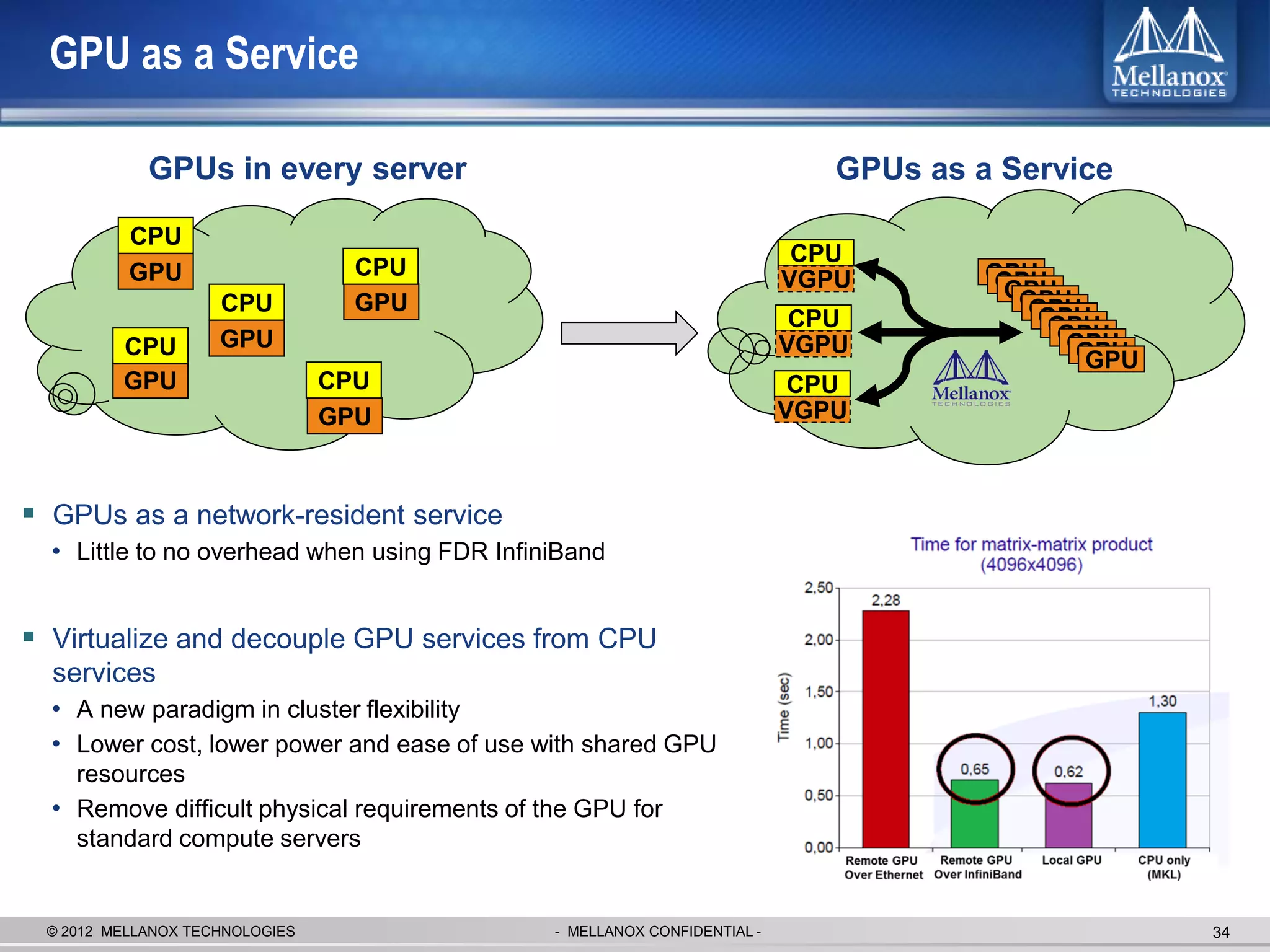

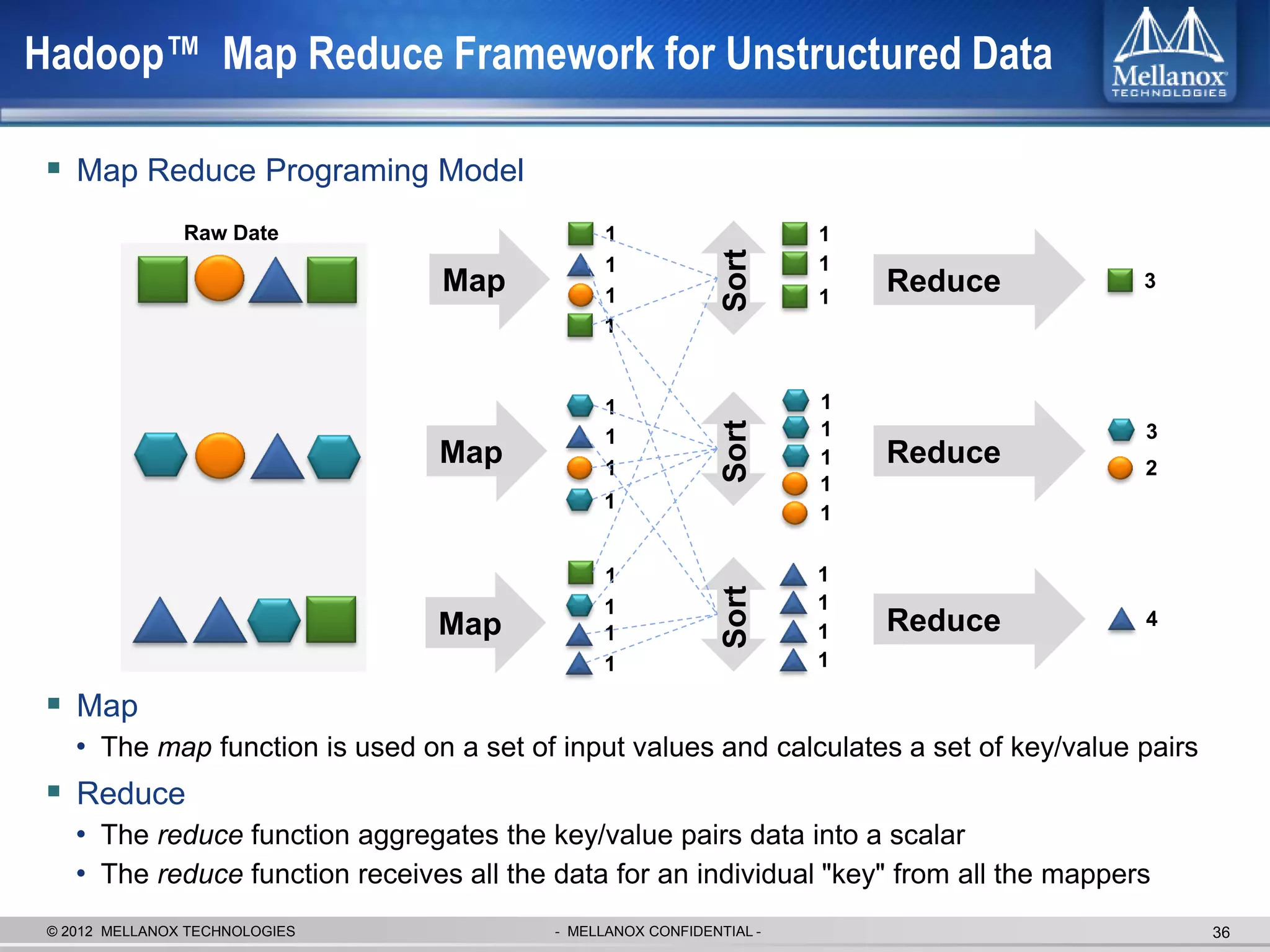
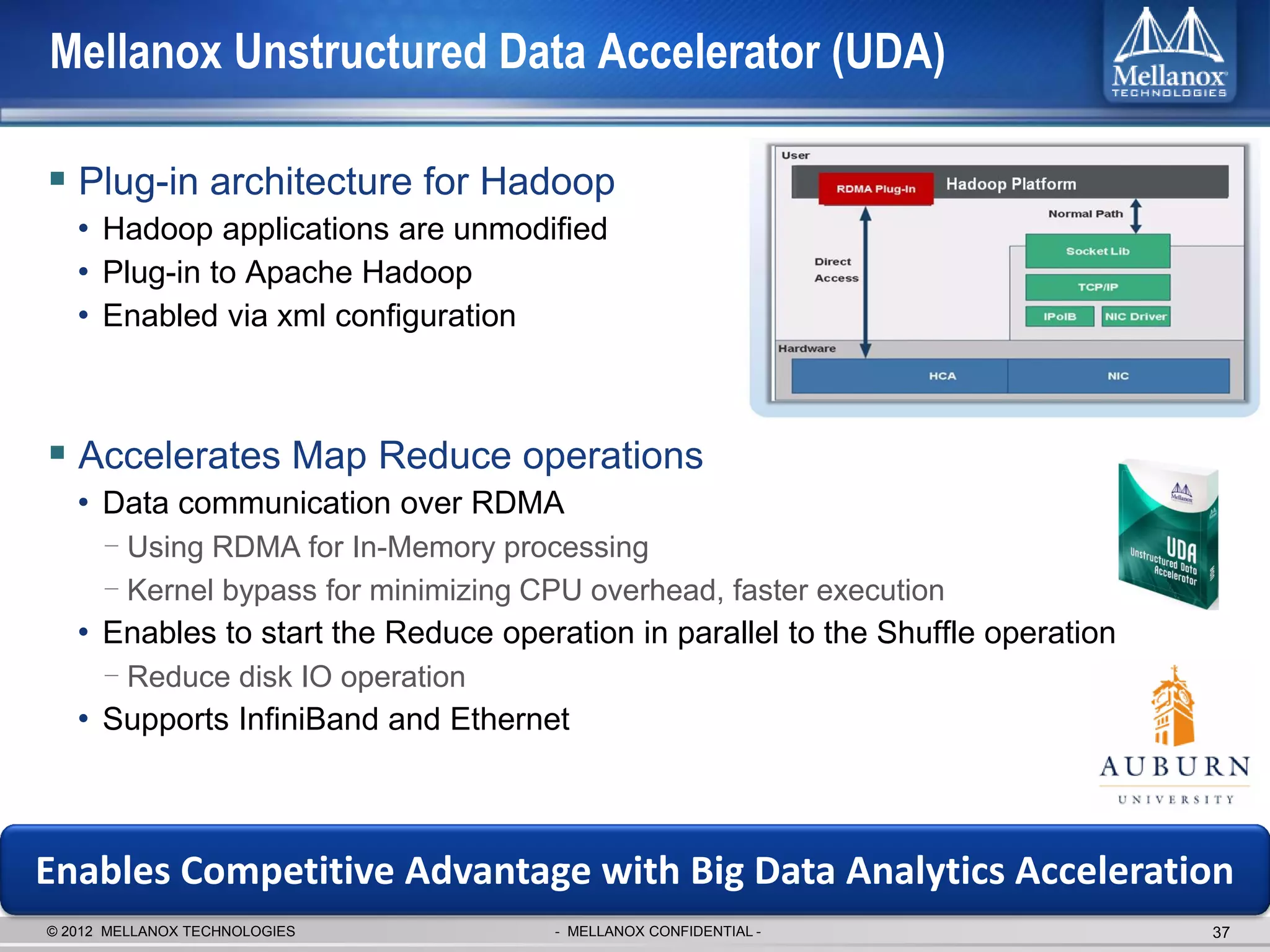
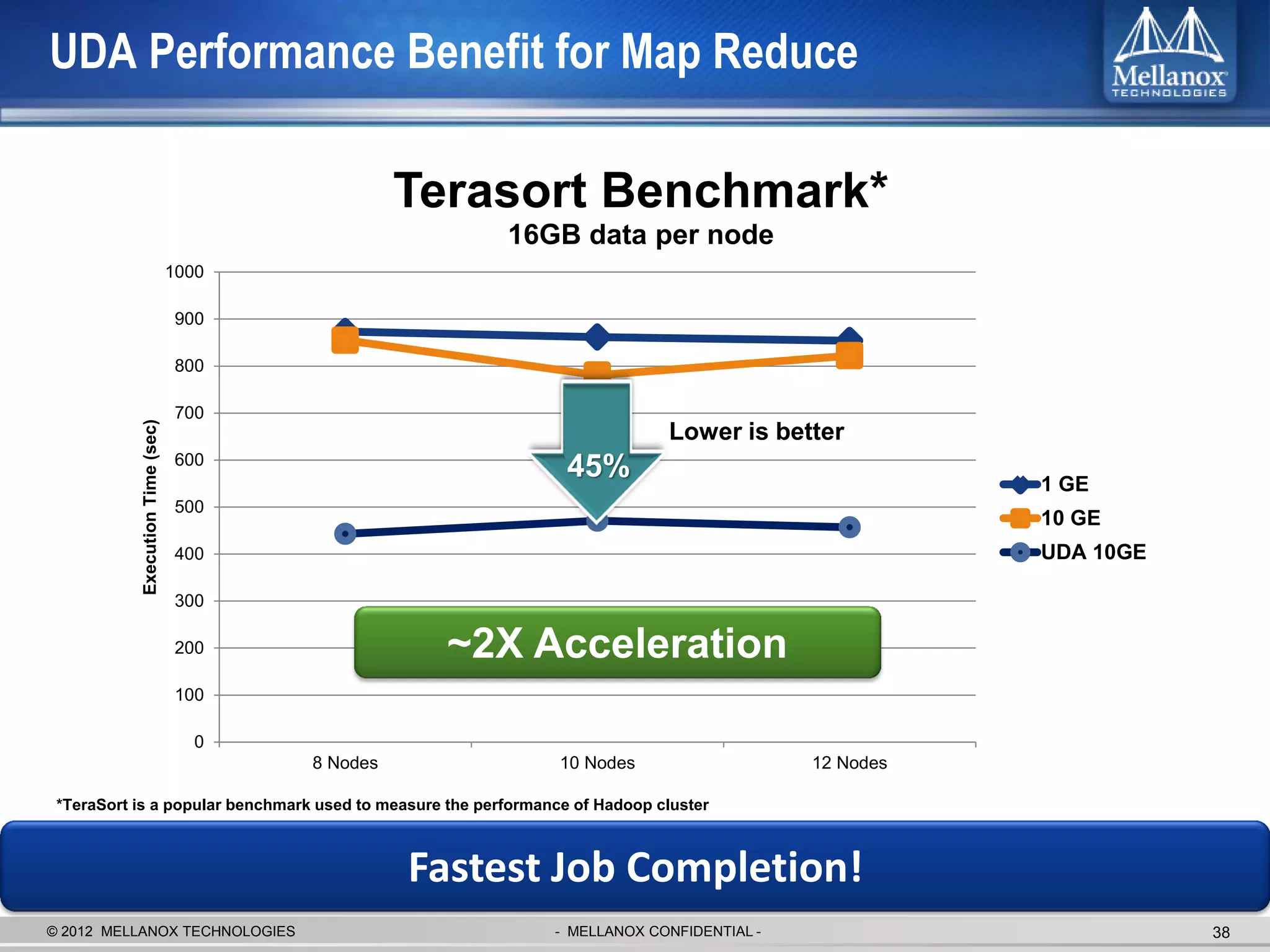



The document discusses new advancements in high-performance computing (HPC) interconnect technology from Mellanox Technologies. It outlines how Mellanox's FDR InfiniBand has become the most commonly used interconnect solution for HPC, connecting more of the world's fastest supercomputers. It also presents Mellanox's roadmap and new products that support higher speeds and capabilities to pave the way for exascale computing through solutions like Connect-IB and optimizations for GPUs and accelerators.





































































































