Download as PDF, PPTX











![RDBMS
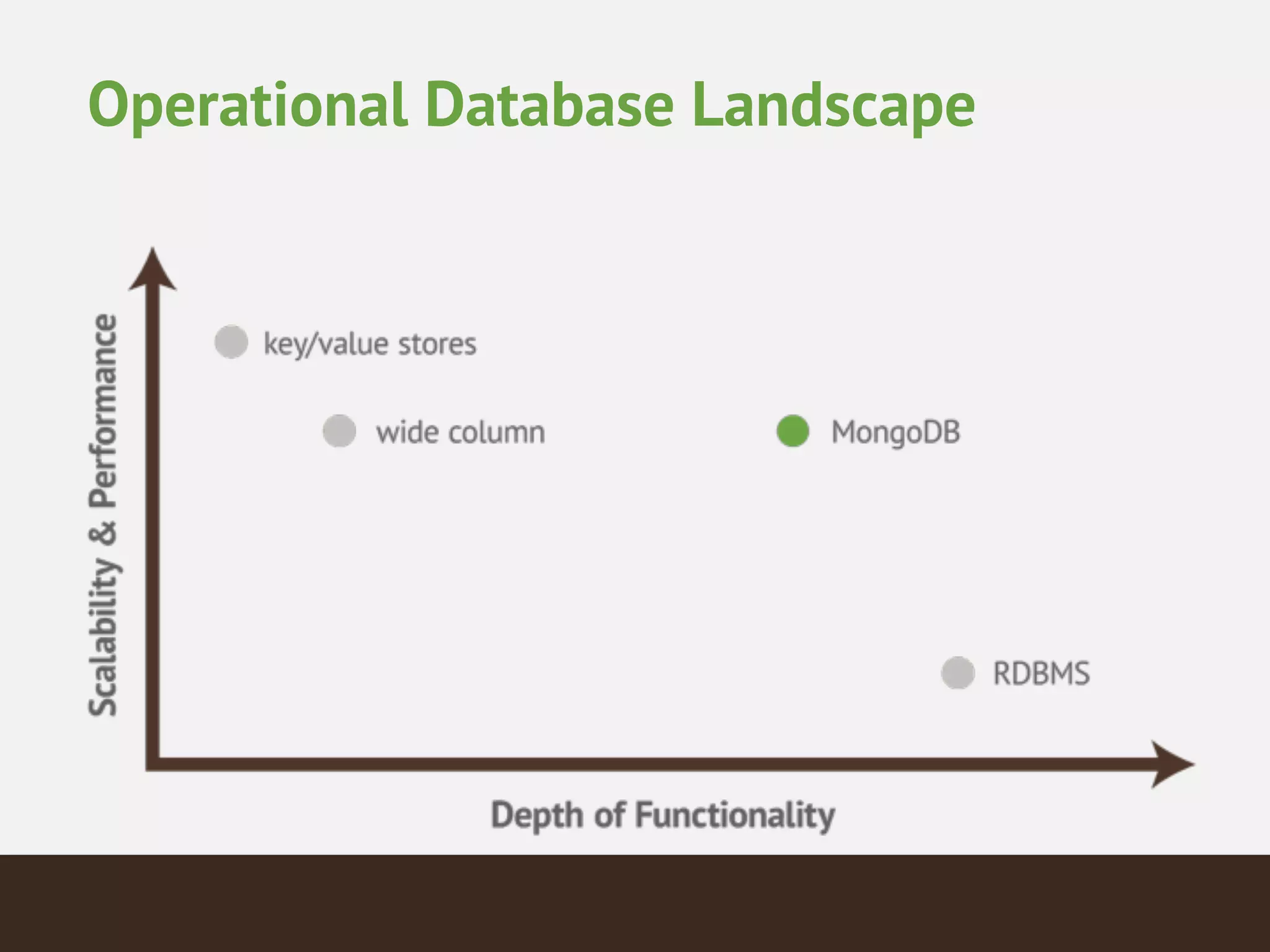
From Complexity to Simplicity
MongoDB
{
_id : ObjectId("4c4ba5e5e8aabf3"),
employee_name: "Dunham, Justin",
department : "Marketing",
title : "Product Manager, Web",
report_up: "Neray, Graham",
pay_band: “C",
benefits : [
{ type : "Health",
plan : "PPO Plus" },
{ type : "Dental",
plan : "Standard" }
]
}](https://image.slidesharecdn.com/mongodb2-140610051950-phpapp01/75/MongoDB-What-why-when-15-2048.jpg)






![Document Data Model
Relational MongoDB
{
first_name: ‘Paul’,
surname: ‘Miller’,
city: ‘London’,
location: [45.123,47.232],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
]
}](https://image.slidesharecdn.com/mongodb2-140610051950-phpapp01/75/MongoDB-What-why-when-25-2048.jpg)





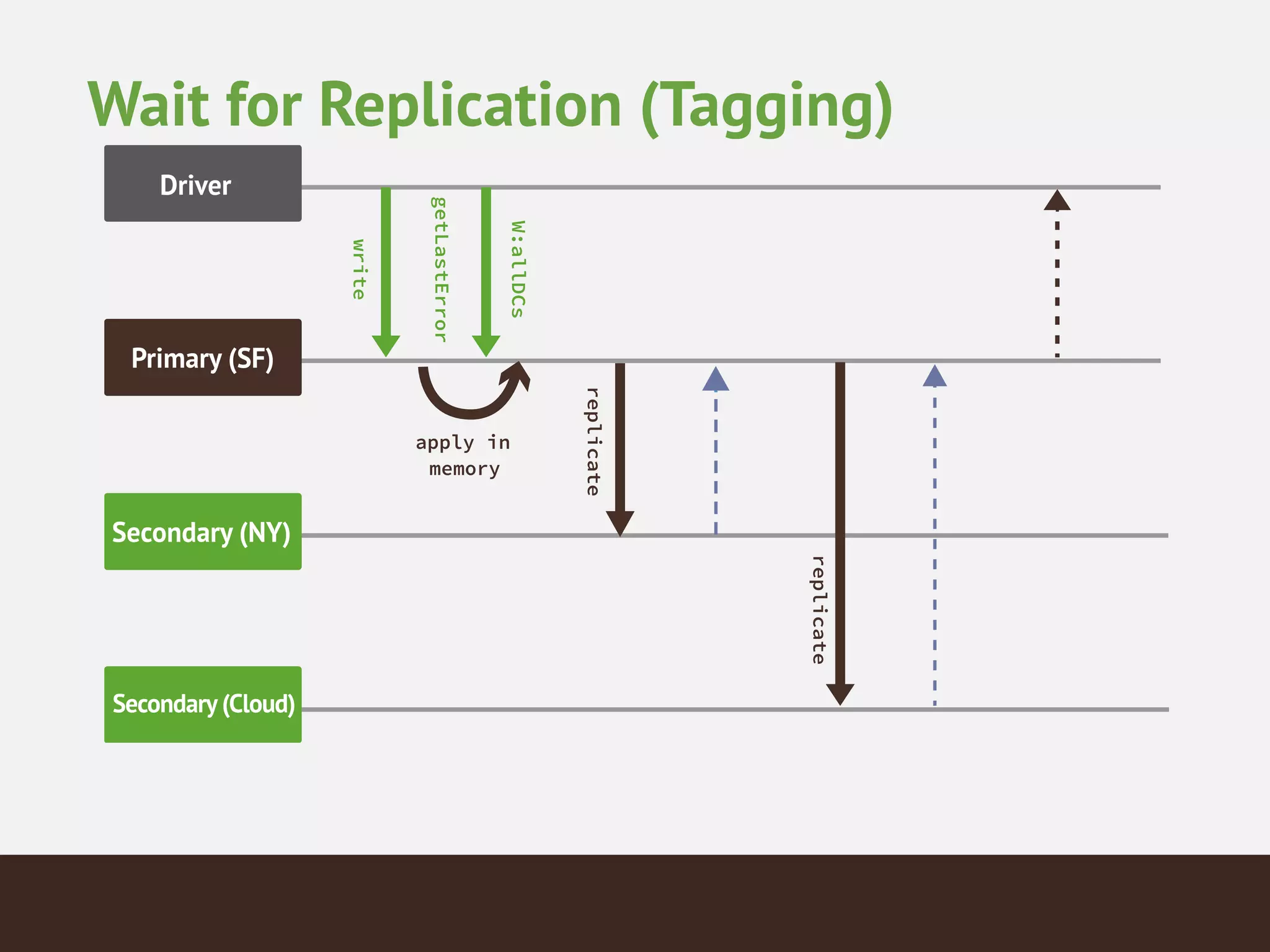
![{!
_id : "mySet",!
members : [!
{_id : 0, host : "A", tags : {"dc": "ny"}},!
{_id : 1, host : "B", tags : {"dc": "ny"}},!
{_id : 2, host : "C", tags : {"dc": "sf"}},!
{_id : 3, host : "D", tags : {"dc": "sf"}},!
{_id : 4, host : "E", tags : {"dc": "cloud"}}],!
settings : {!
getLastErrorModes : {!
allDCs : {"dc" : 3},!
someDCs : {"dc" : 2}} }!
}!
> db.blogs.insert({...})!
> db.runCommand({getLastError : 1, w : "someDCs"})
Tagging Example](https://image.slidesharecdn.com/mongodb2-140610051950-phpapp01/75/MongoDB-What-why-when-41-2048.jpg)


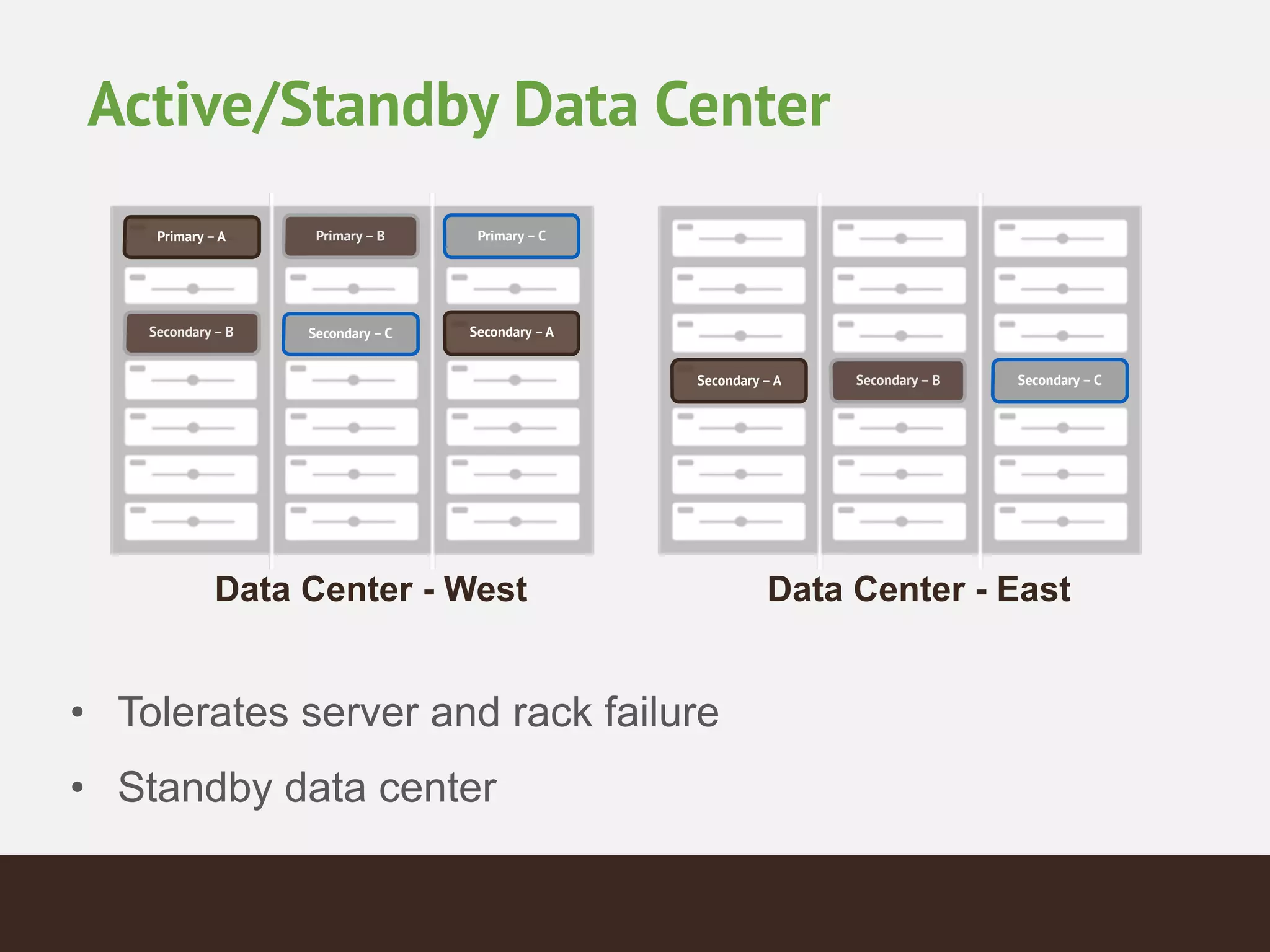
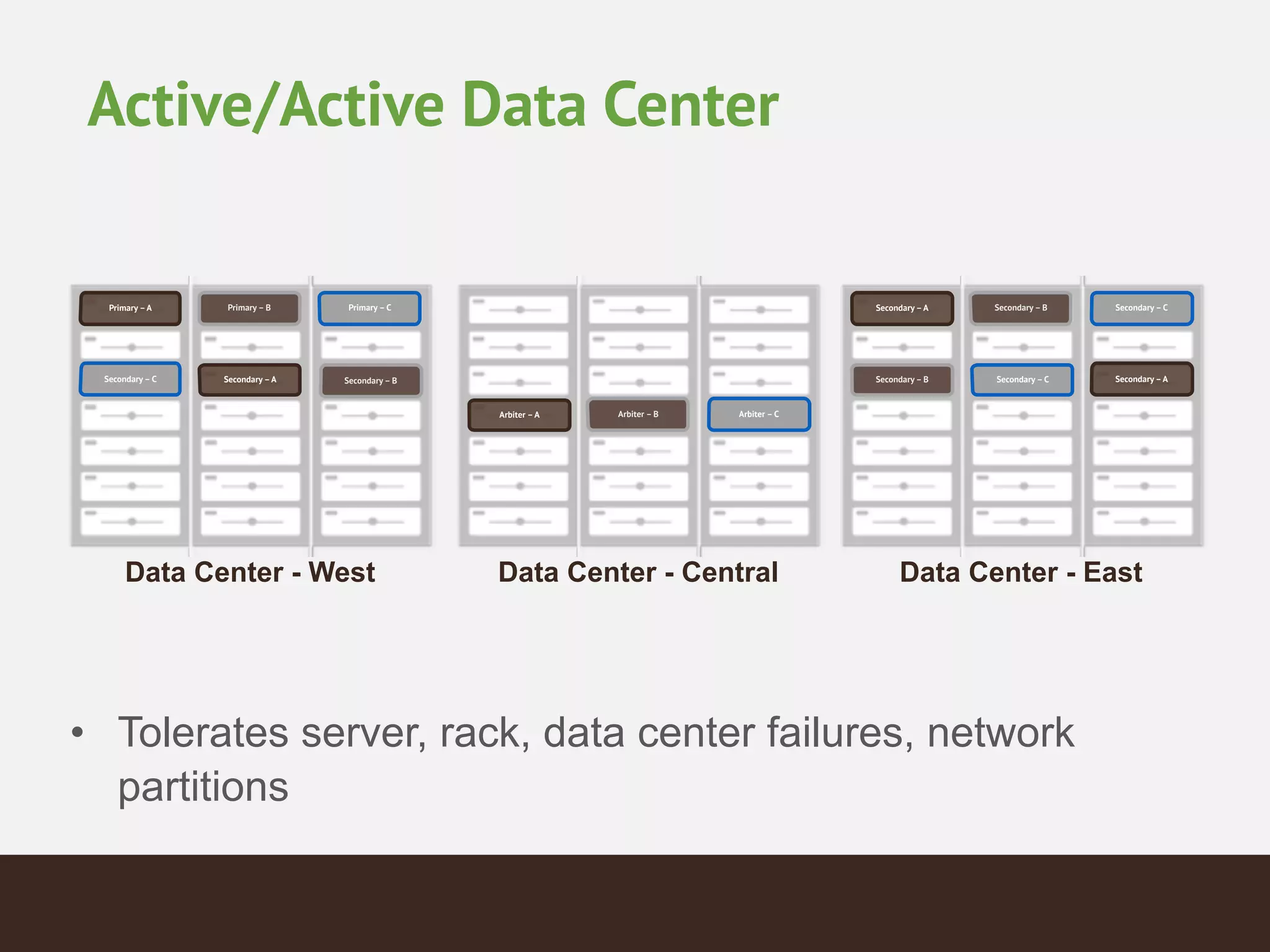
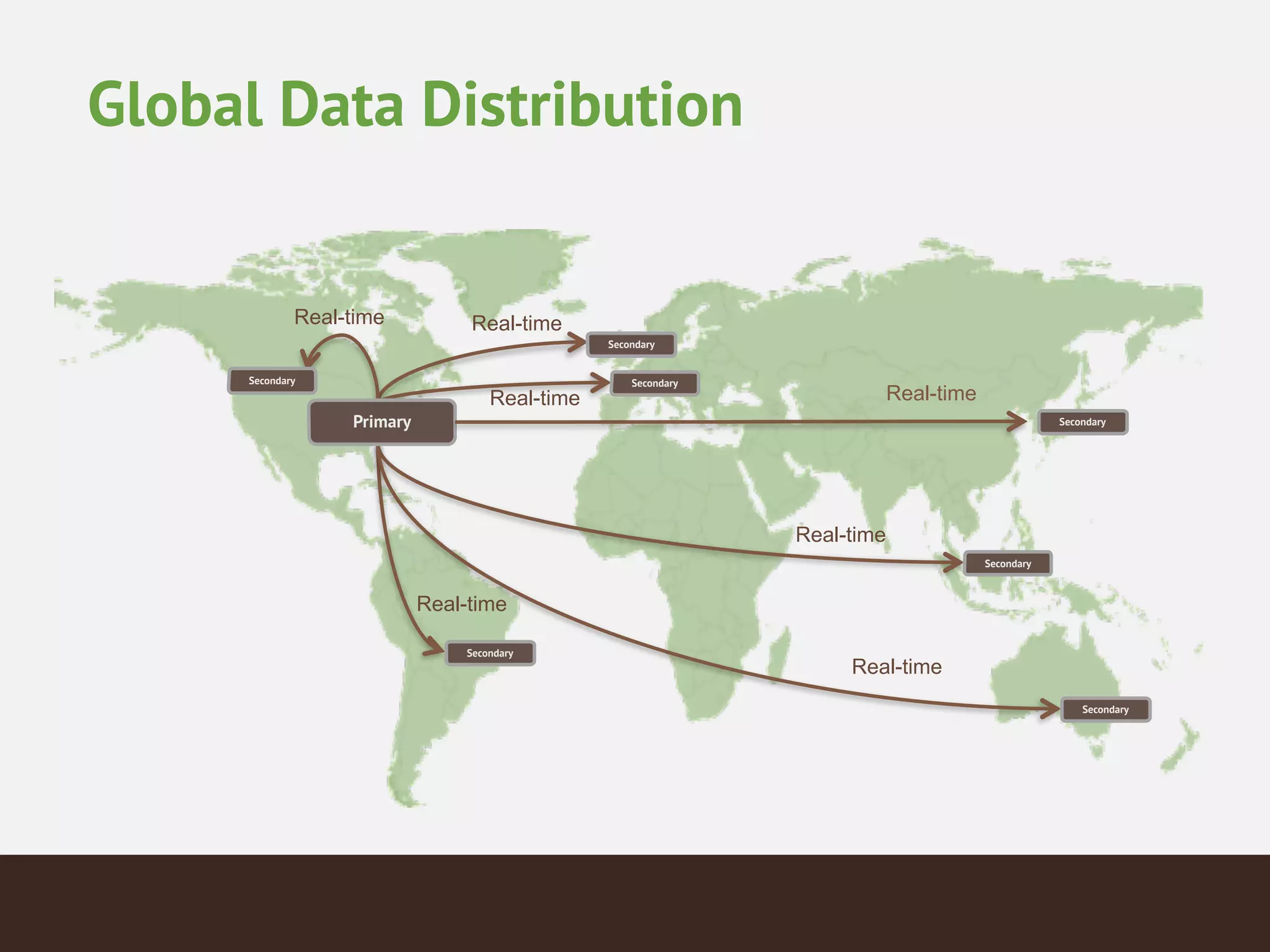
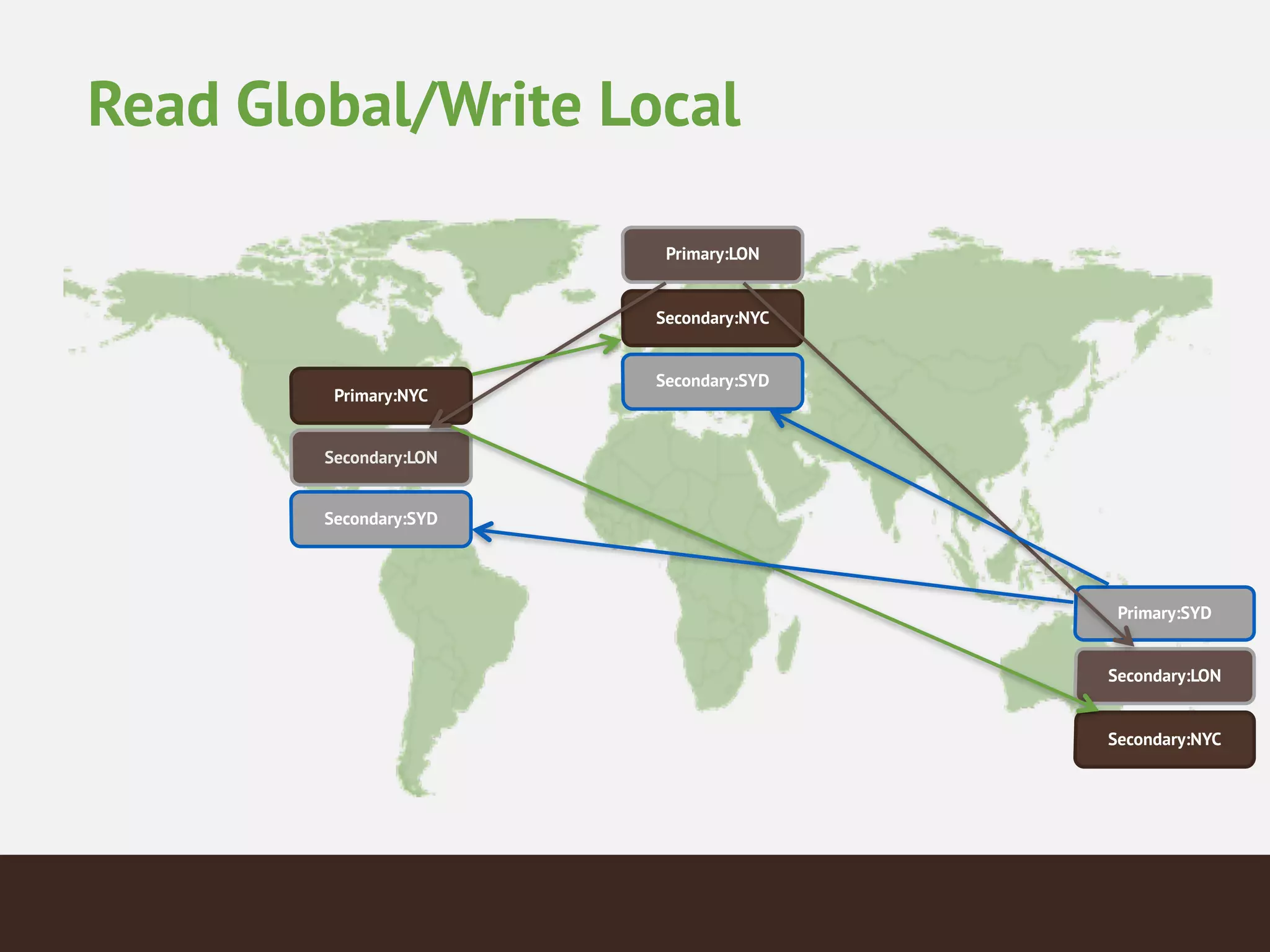







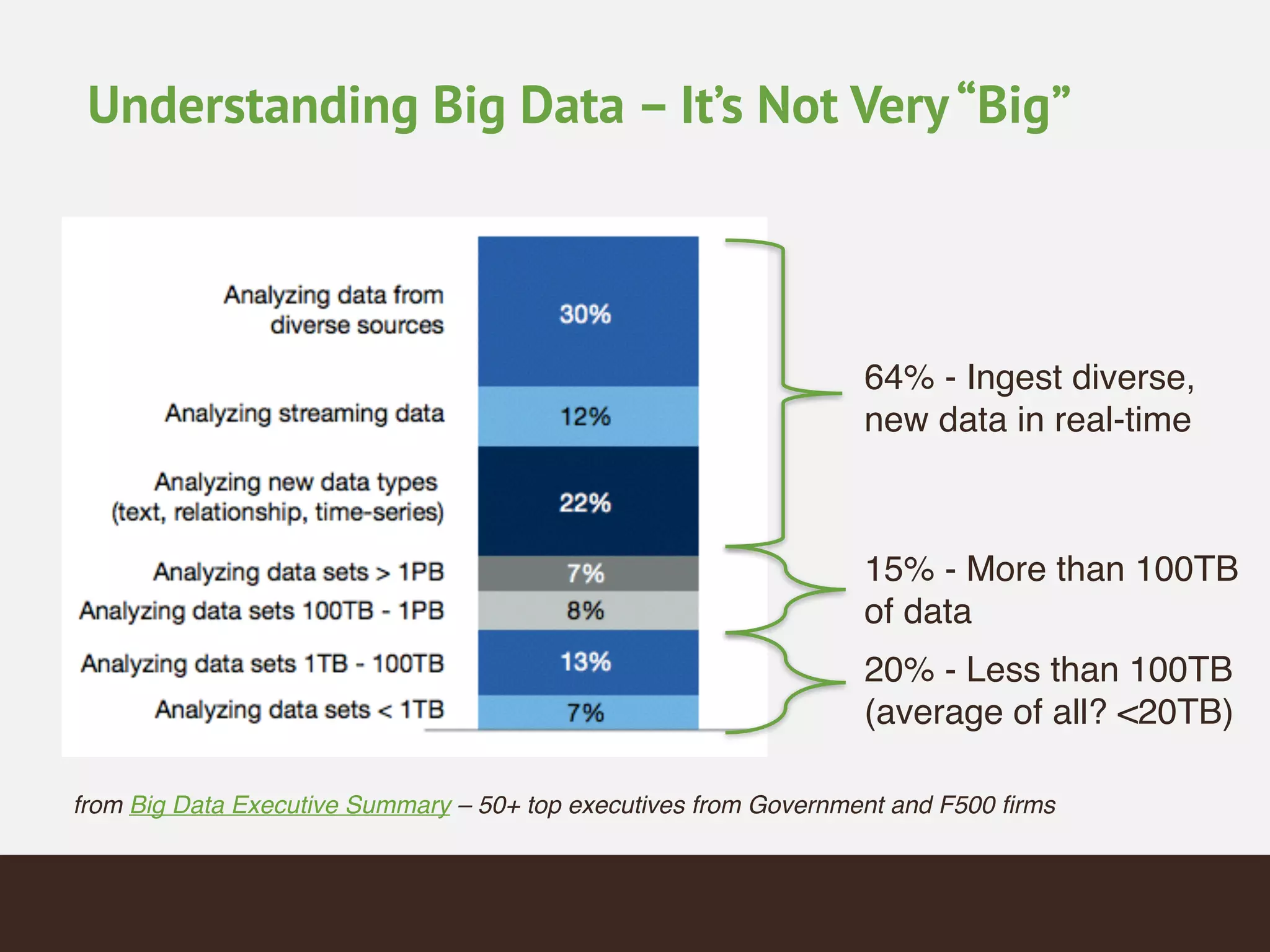
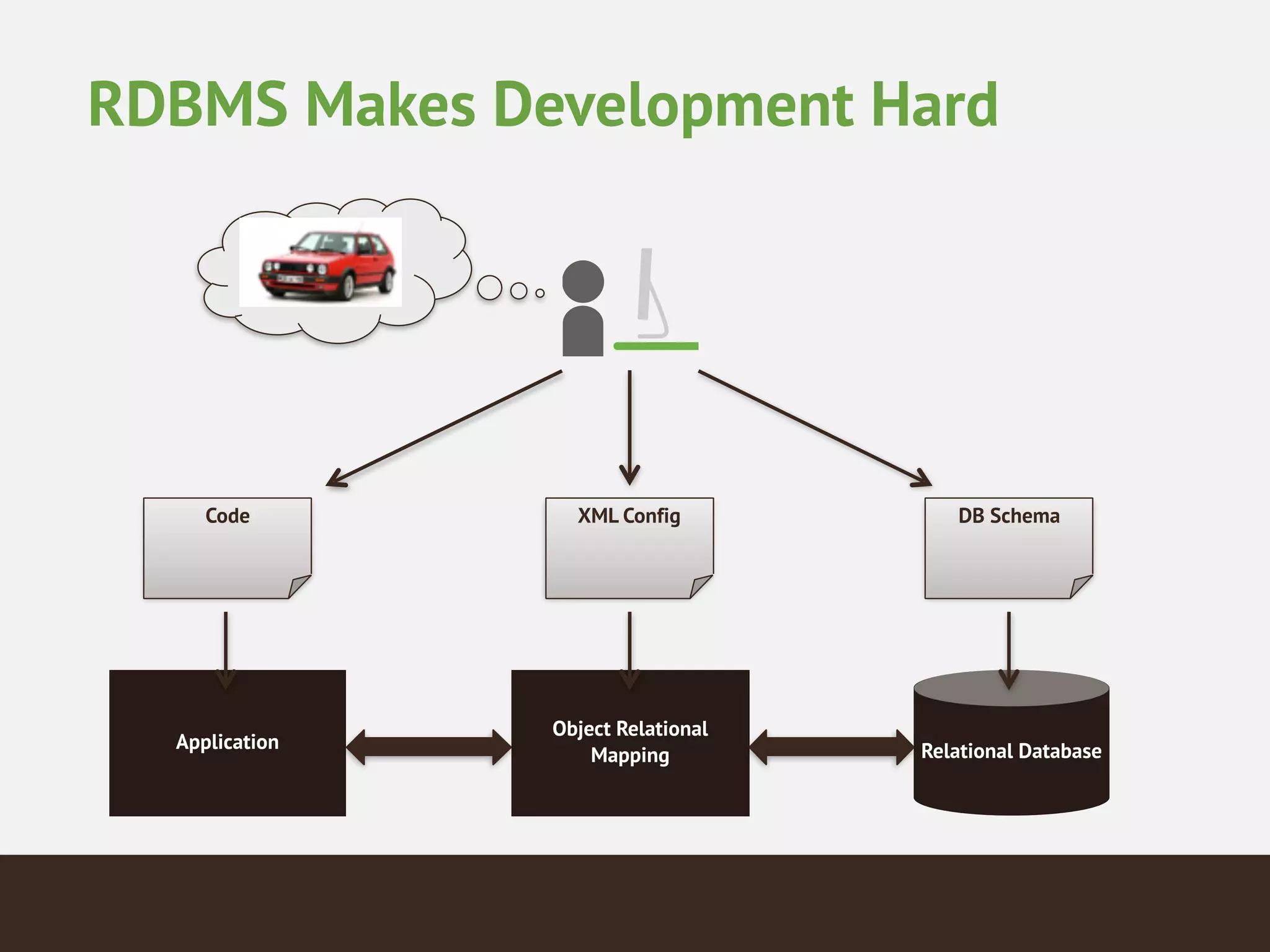
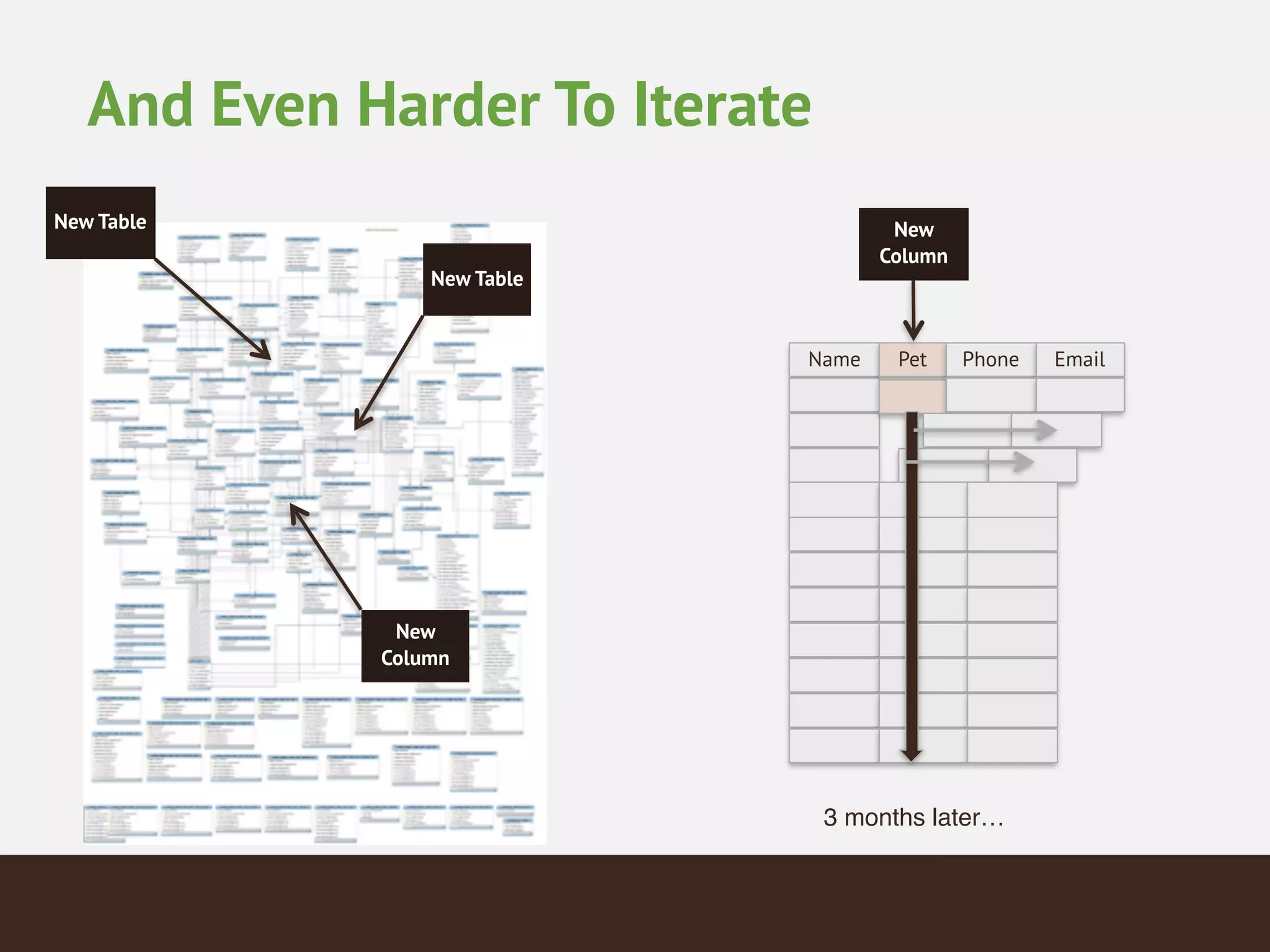
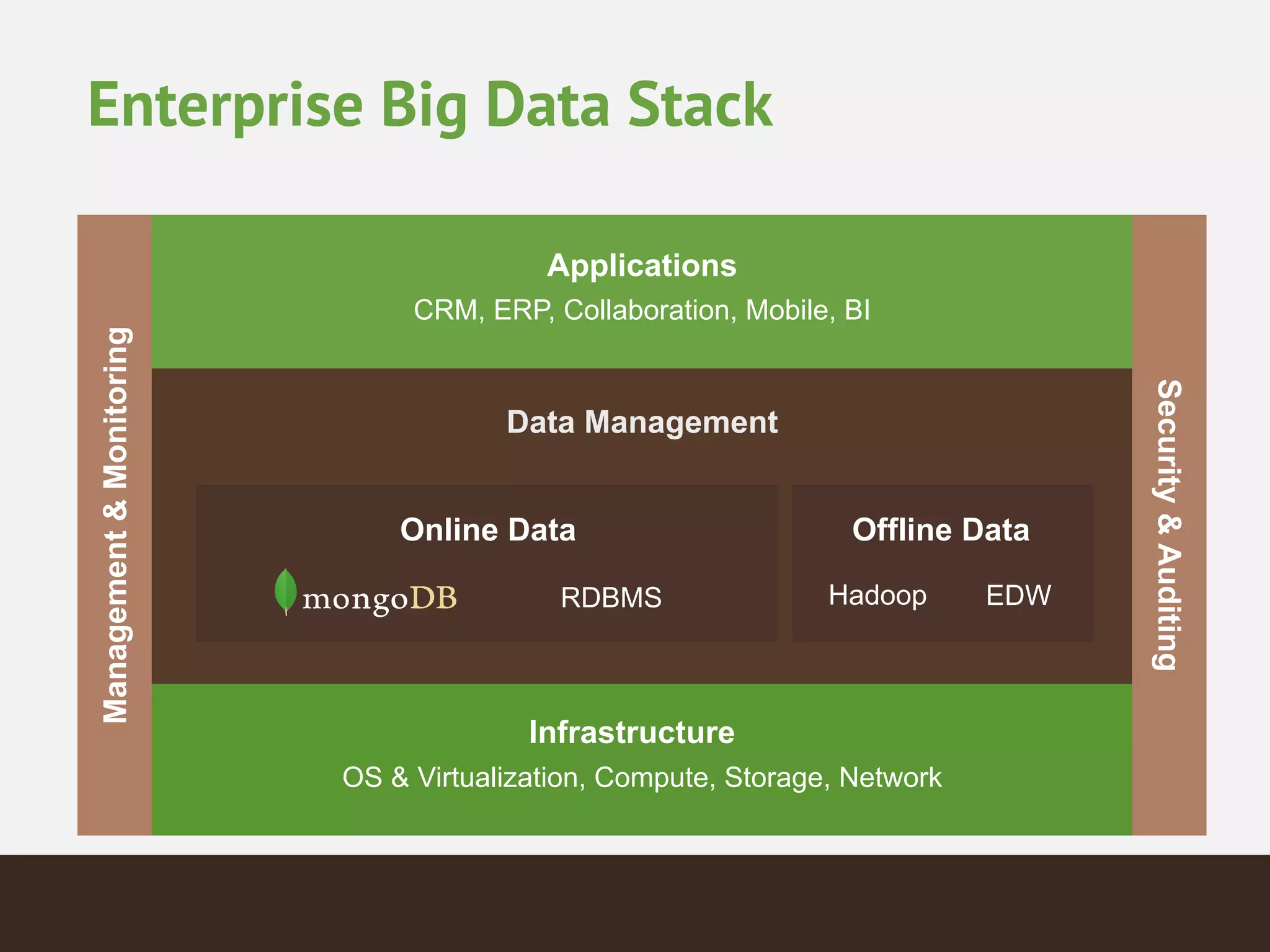
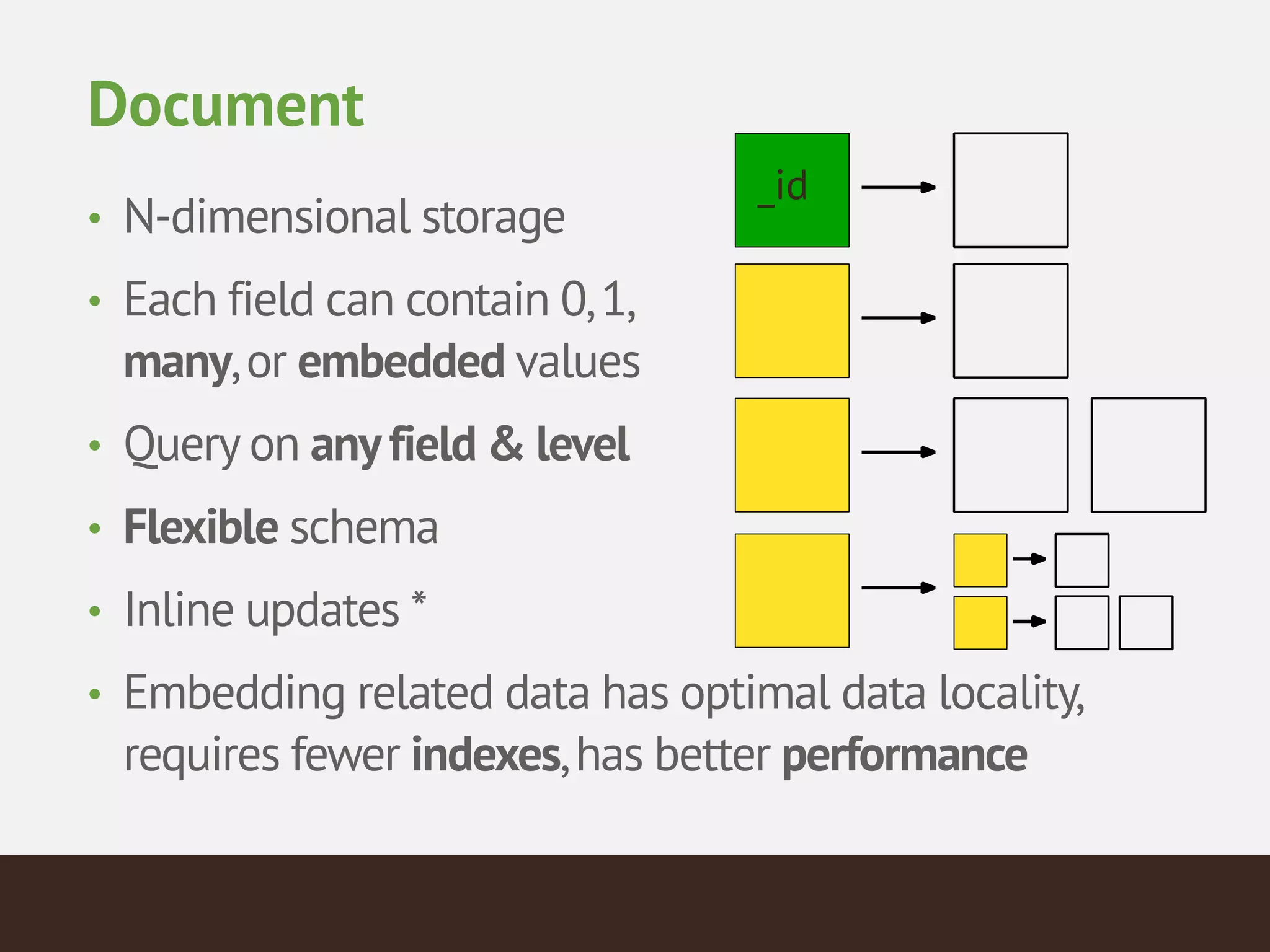
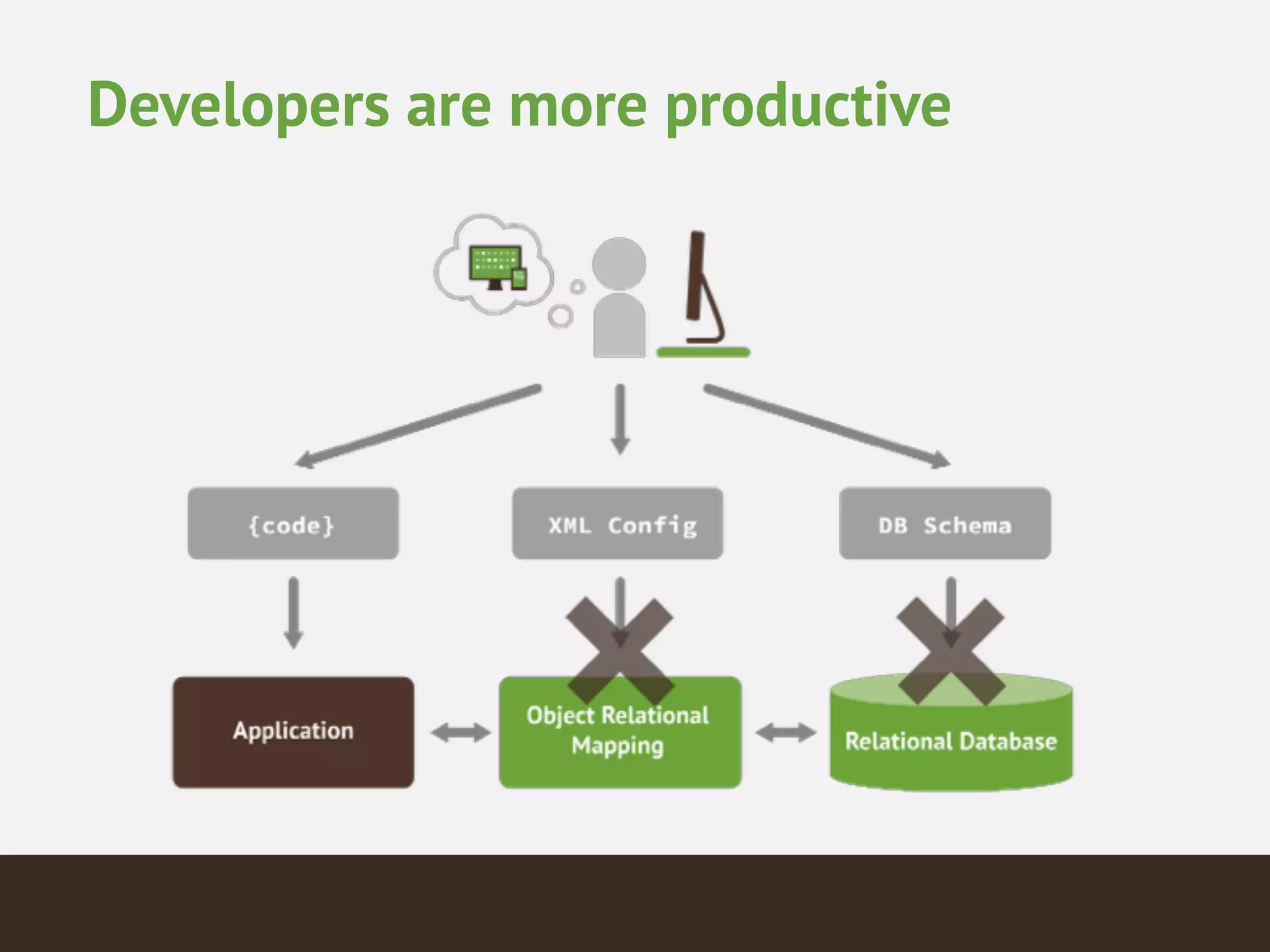
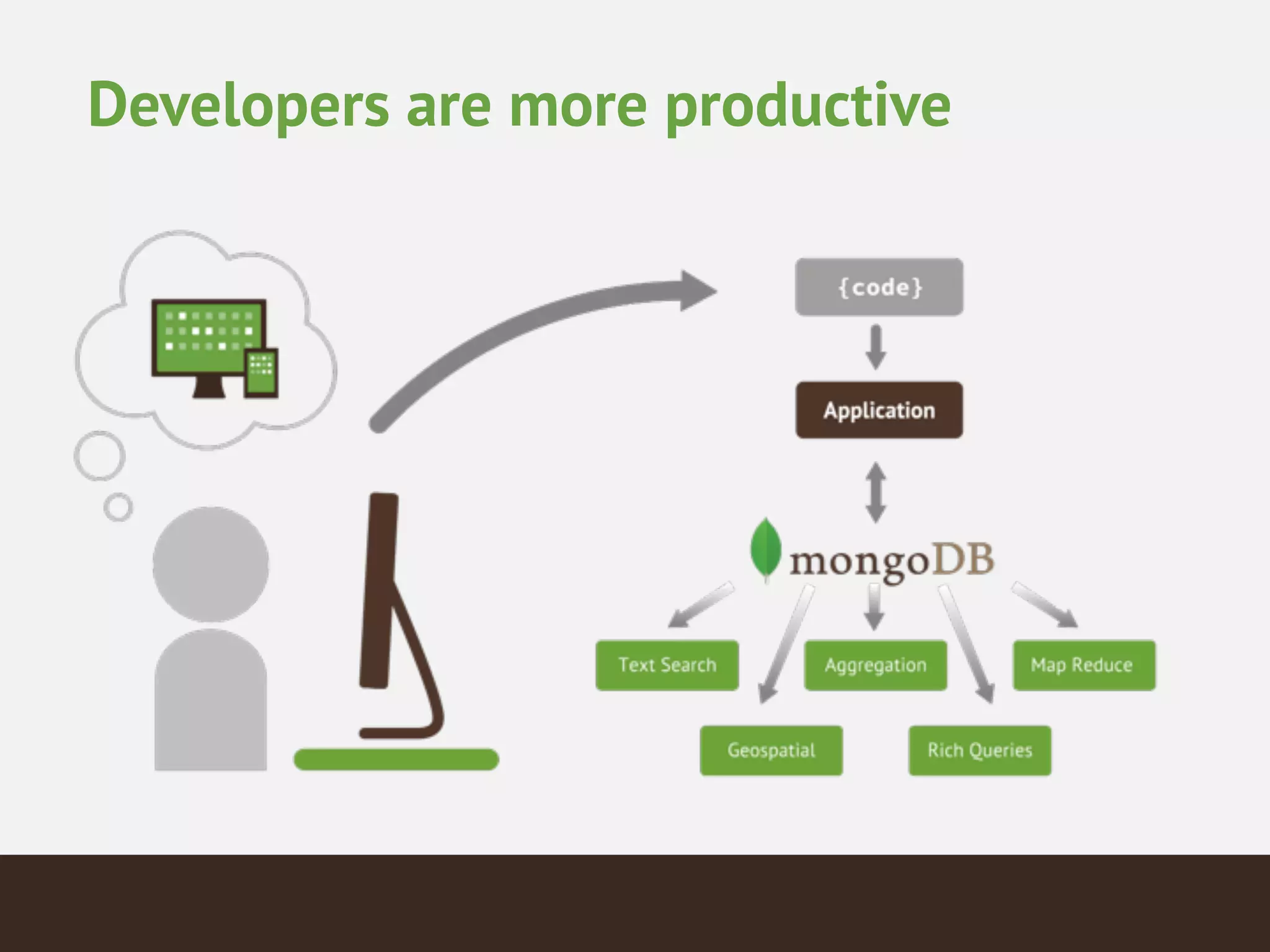
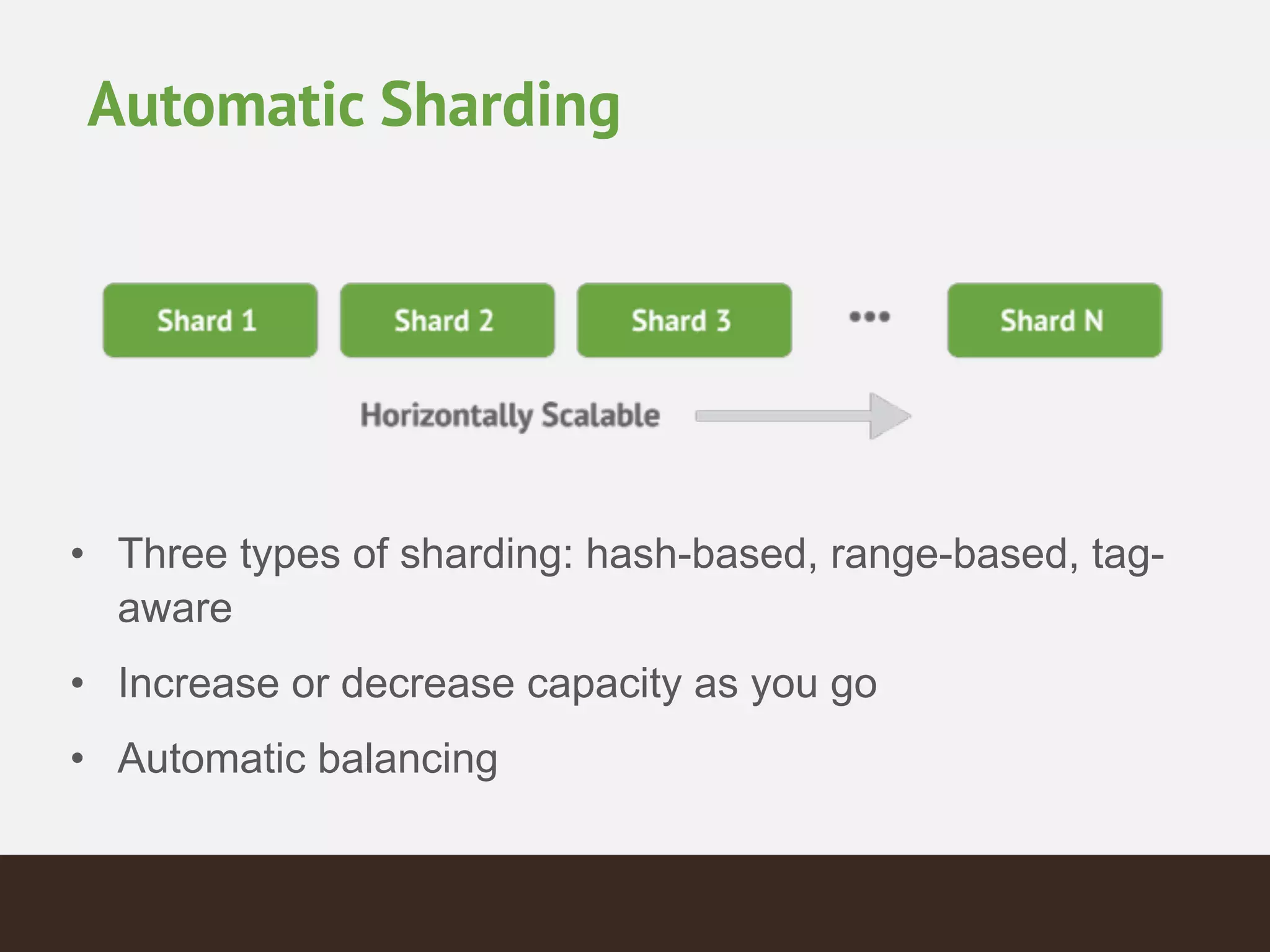
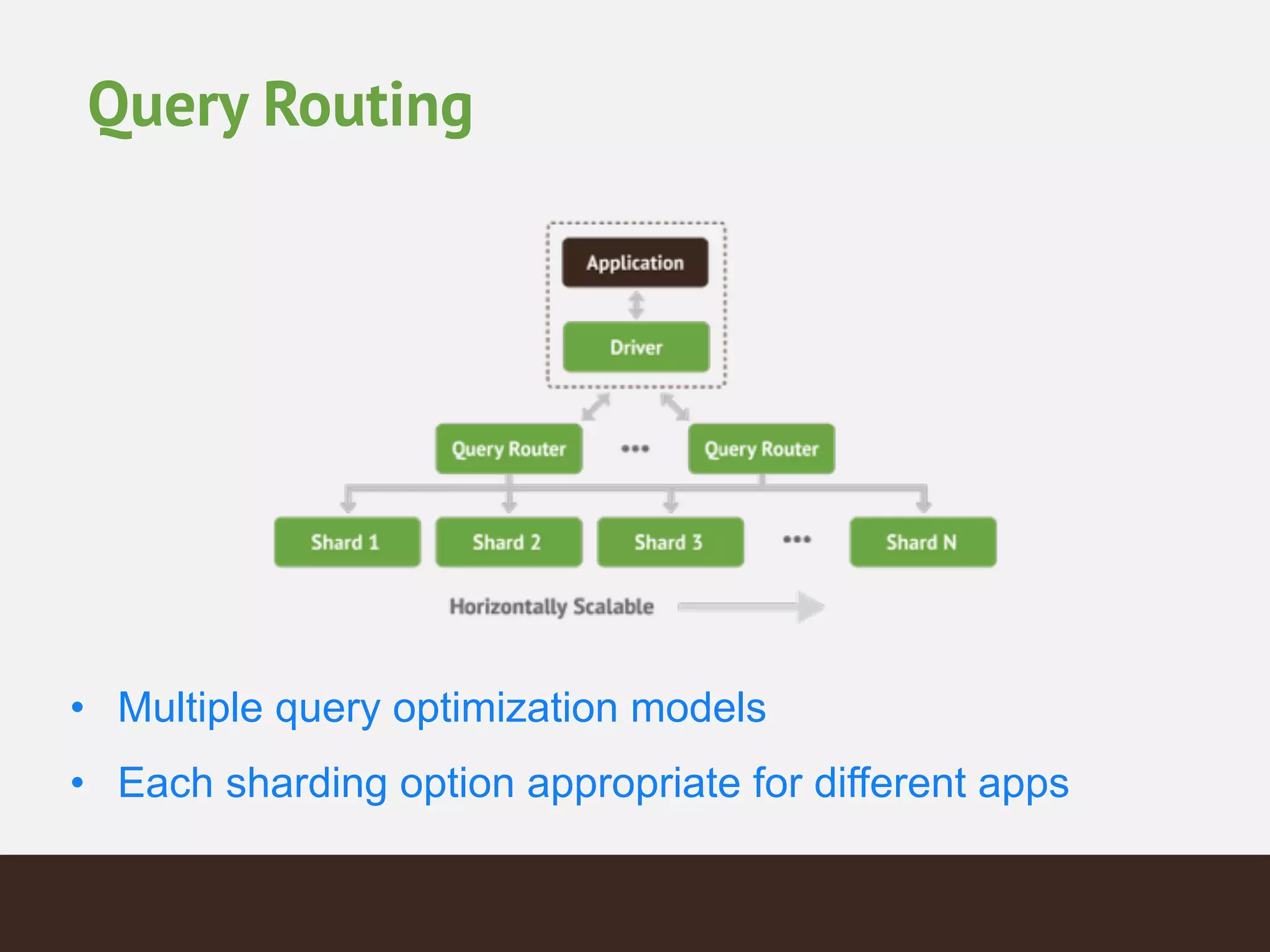
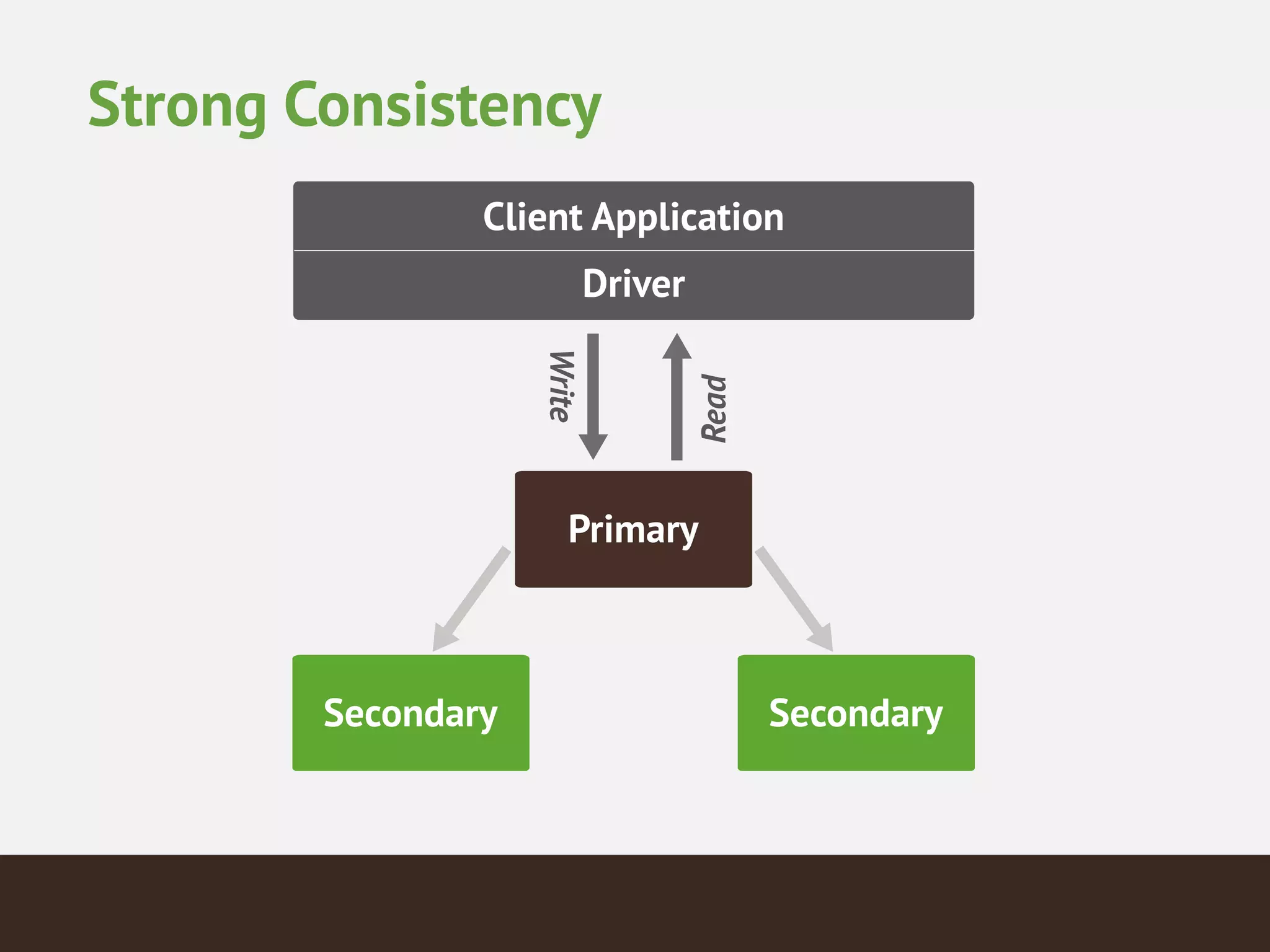
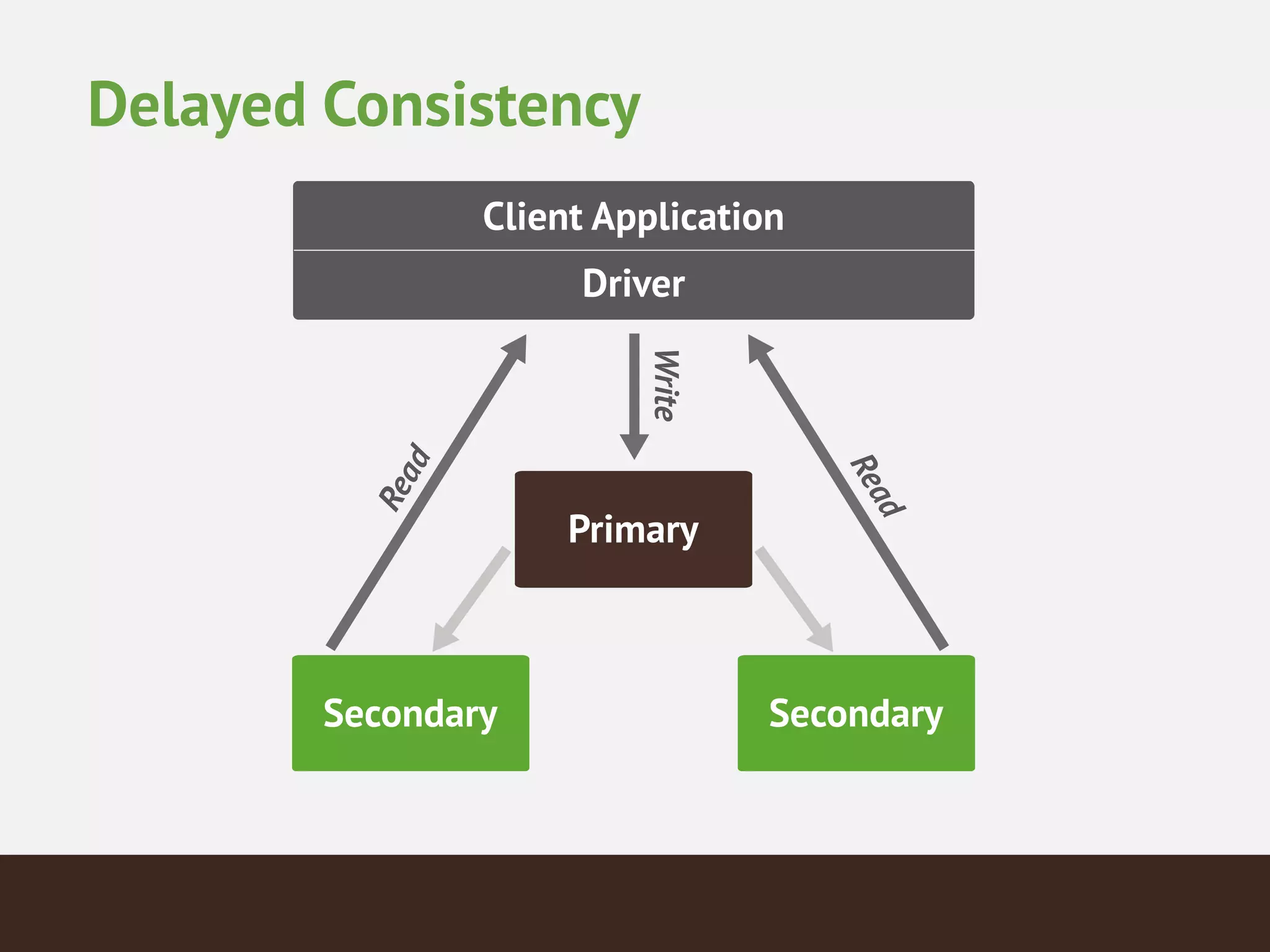
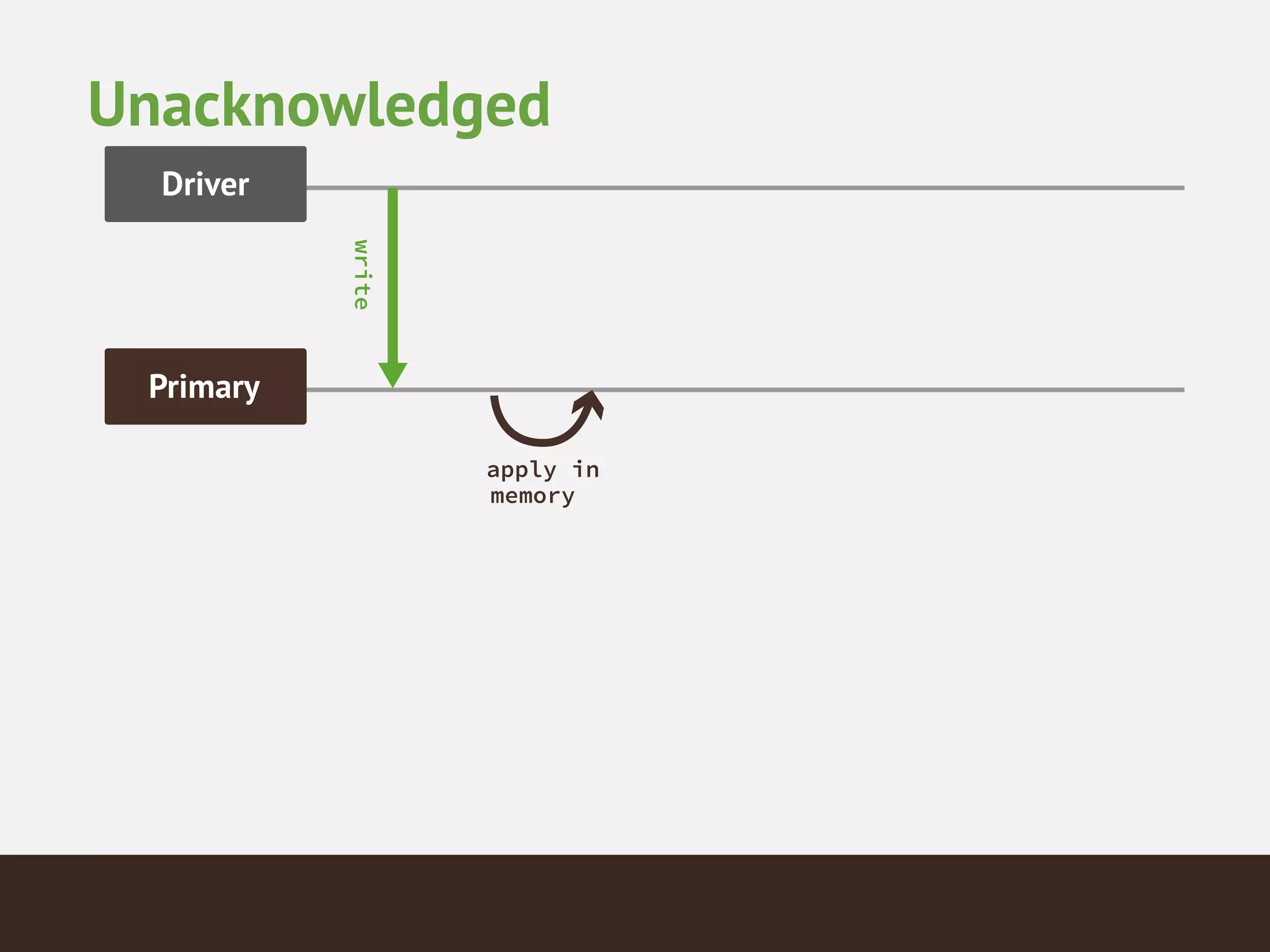
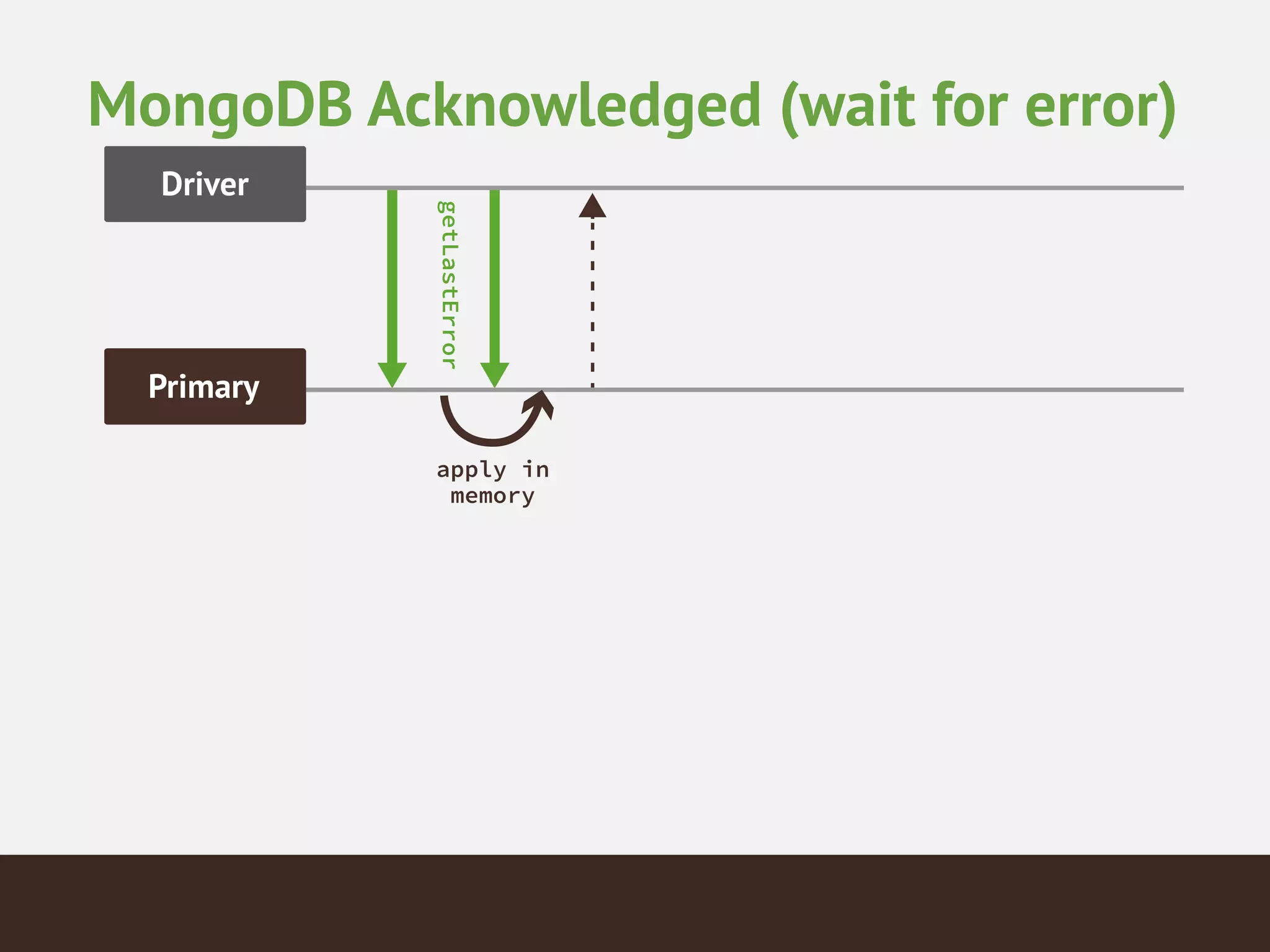
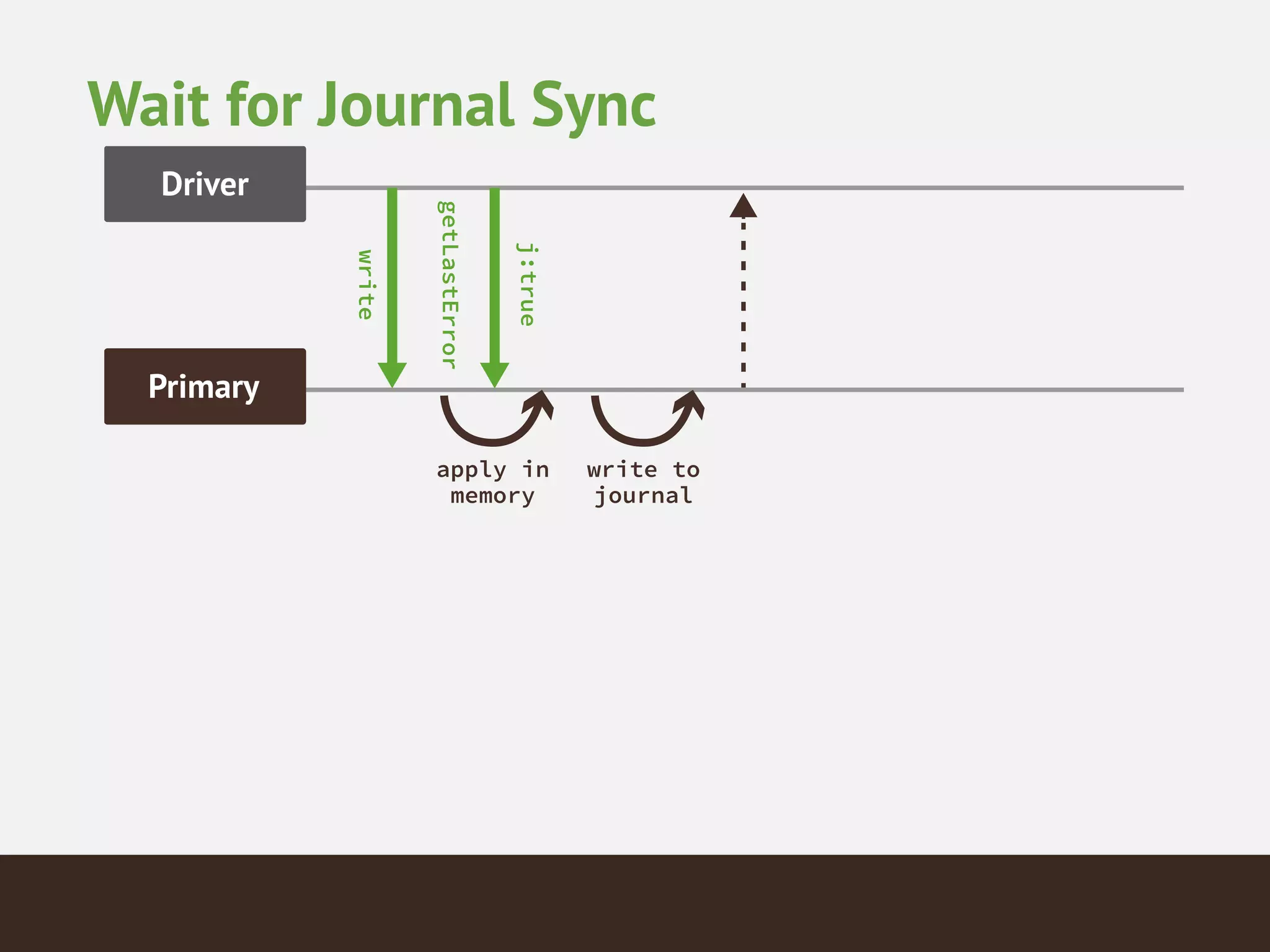
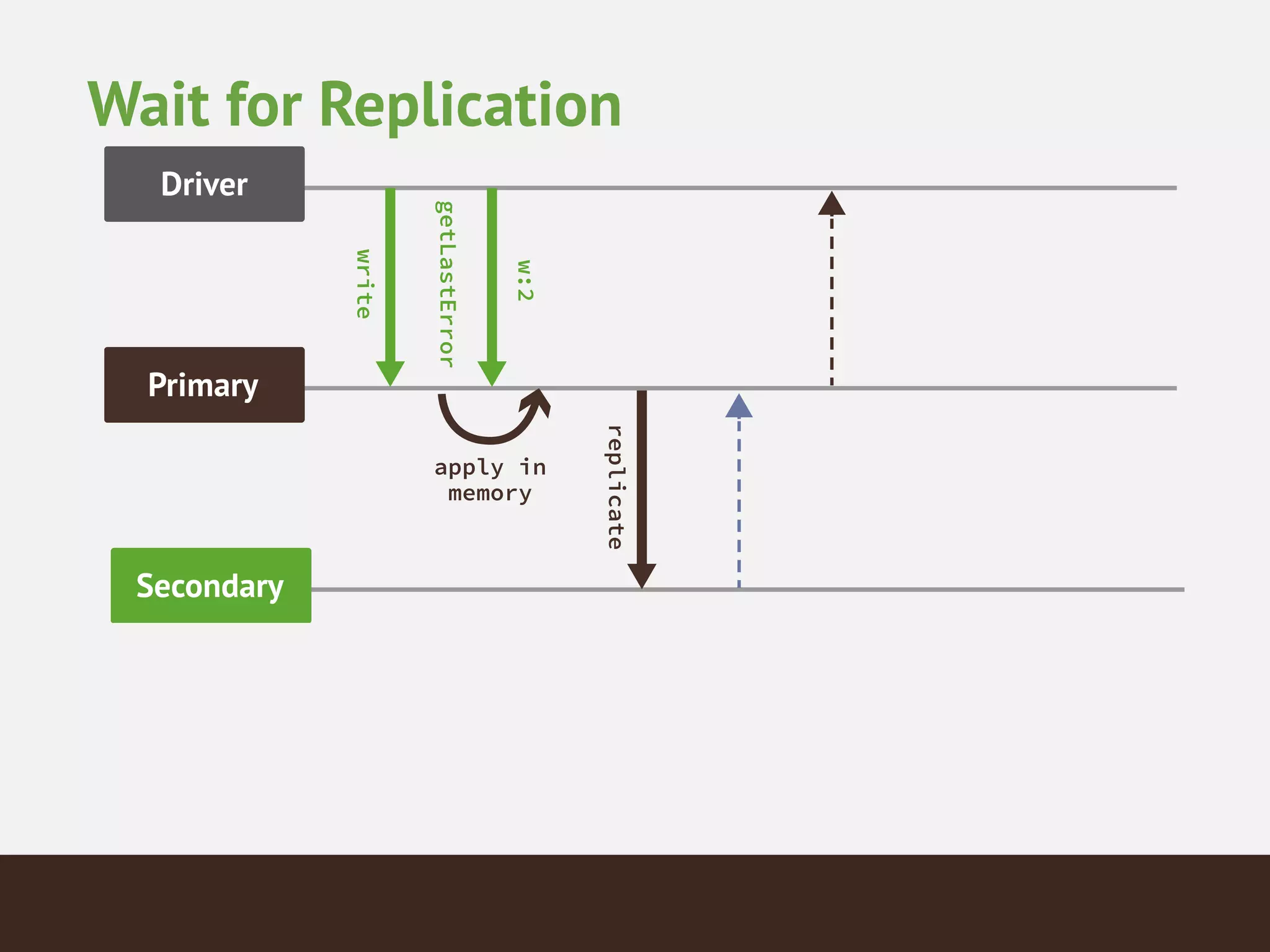
MongoDB is a document database that provides a more flexible schema than relational databases. It allows embedding related data and easier updates than relational databases with object-relational mapping. MongoDB scales horizontally through sharding and provides high availability through replica sets. It supports different consistency models including eventual and strong consistency through write concerns and read preferences.














































































![Automating ISP Networks Using Ansible and IPAM as a Source of Truth [SoT]](https://cdn.slidesharecdn.com/ss_thumbnails/automatingispnetworksusingansibleandipamasasourceoftruthsot-v25-1-251124105117-d7d4ca24-thumbnail.jpg?width=640&height=640&fit=bounds)











