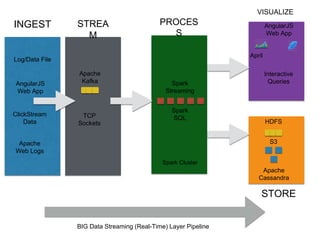
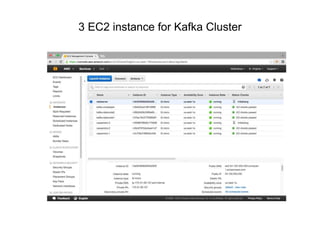
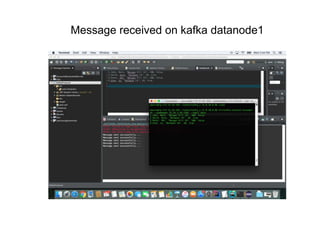
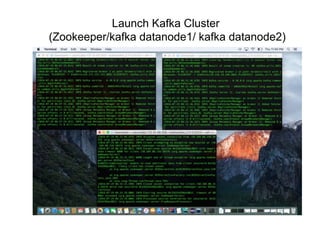
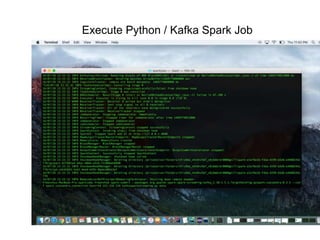
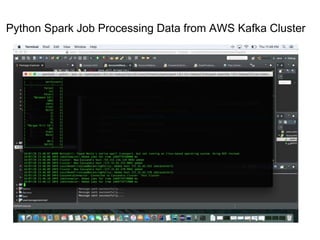
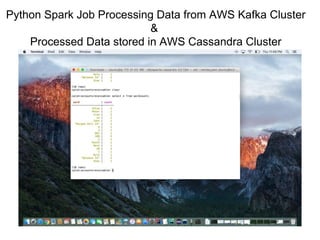
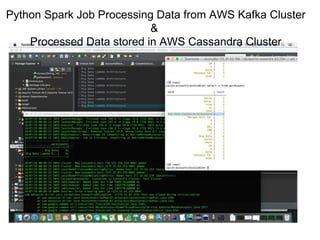
The document outlines a big data pipeline using a lambda architecture that integrates Apache Kafka, Hadoop, Spark, and Cassandra on AWS. It provides detailed instructions for setting up a Kafka cluster, including configuring servers, starting Zookeeper, and creating a data topic, along with a Java producer application for sending messages to Kafka. Additionally, it describes using Python Spark jobs to process data received from the Kafka cluster and storing the results in Cassandra.






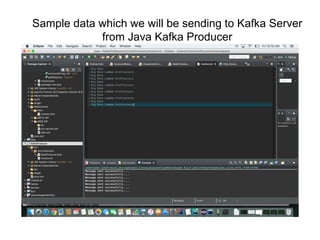
![Java - Kafka Producer Sample Applicationpackage com.himanshu;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
public class DataProducer {
public static void main(String[] args) {
// Check arguments length value
/*
if(args.length == 0) {
System.out.println("Enter topic name");
return;
}
*/
//Assign topicName to string variable
String topicName = "data"; //args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", "54.173.215.211:9092,54.226.29.194:9092");
//props.put("metadata.broker.list", "172.31.63.203:9092,172.31.9.25:9092");](https://image.slidesharecdn.com/bigdatalambdaarchitecture-streaminglayer-160729204204/85/Big-data-lambda-architecture-Streaming-Layer-Hands-On-9-320.jpg)
![//Set acknowledgements for producer requests.
props.put("acks", "all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
String csvFile = "/Users/himanshu/Documents/workspace/KafkaProducer/src/com/himanshu/invoice.txt";
String csvSplitBy = ",";
BufferedReader br = null;
String lineInvoice = "";
try {
br = new BufferedReader(new FileReader(csvFile));
while((lineInvoice = br.readLine()) != null ) {
String[] invoice = lineInvoice.split(csvSplitBy);
producer.send(new ProducerRecord<String, String>(topicName, lineInvoice));
System.out.println("Message sent successfully....");
}
}
catch (FileNotFoundException e) {
e.printStackTrace();
}
Java - Kafka Producer Sample Application](https://image.slidesharecdn.com/bigdatalambdaarchitecture-streaminglayer-160729204204/85/Big-data-lambda-architecture-Streaming-Layer-Hands-On-10-320.jpg)



























































![[Big Data Spain] Apache Spark Streaming + Kafka 0.10: an Integration Story](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataspainapachesparkstreamingkafka0-171117095800-thumbnail.jpg?width=640&height=640&fit=bounds)


























