Download to read offline



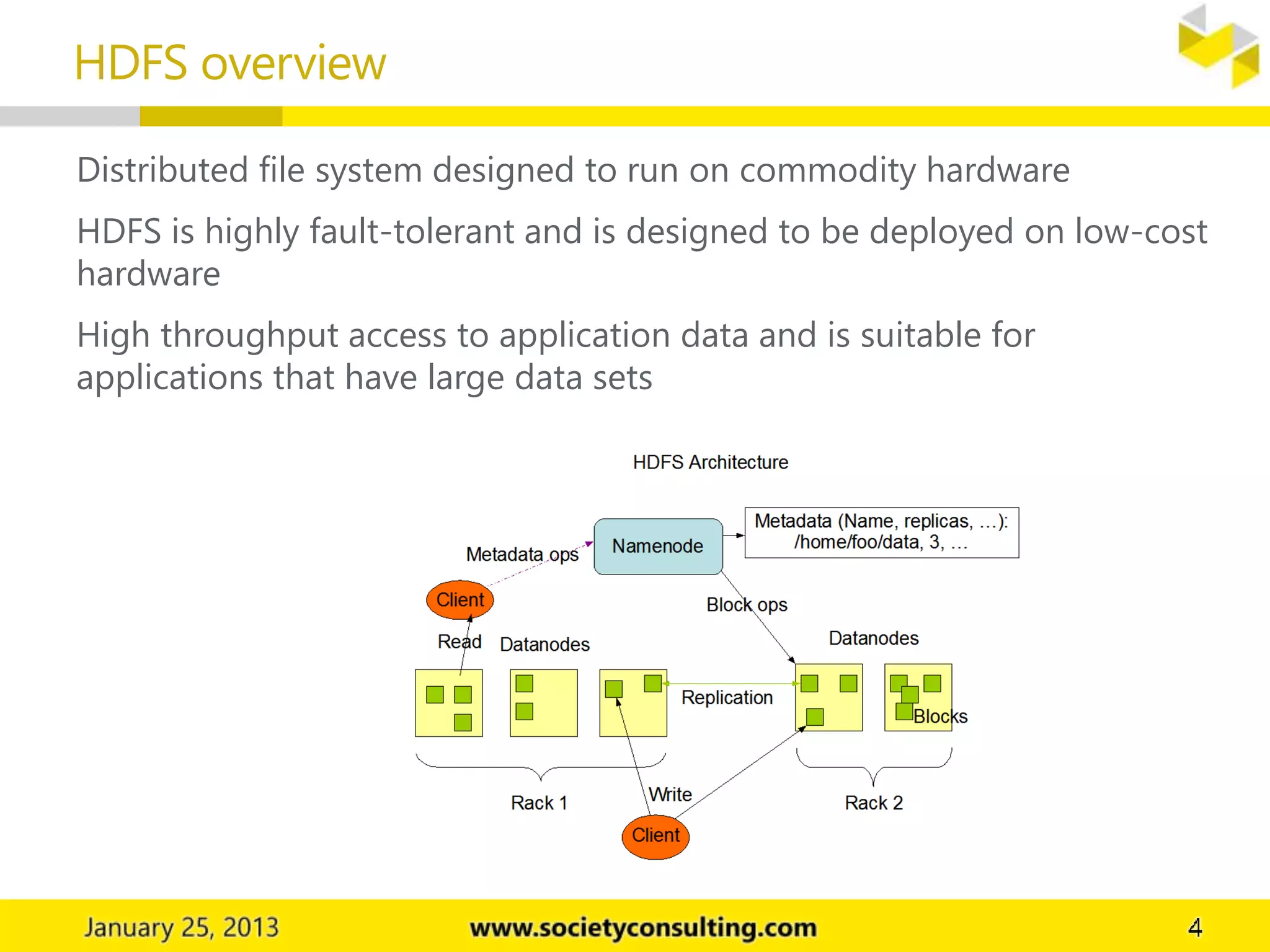

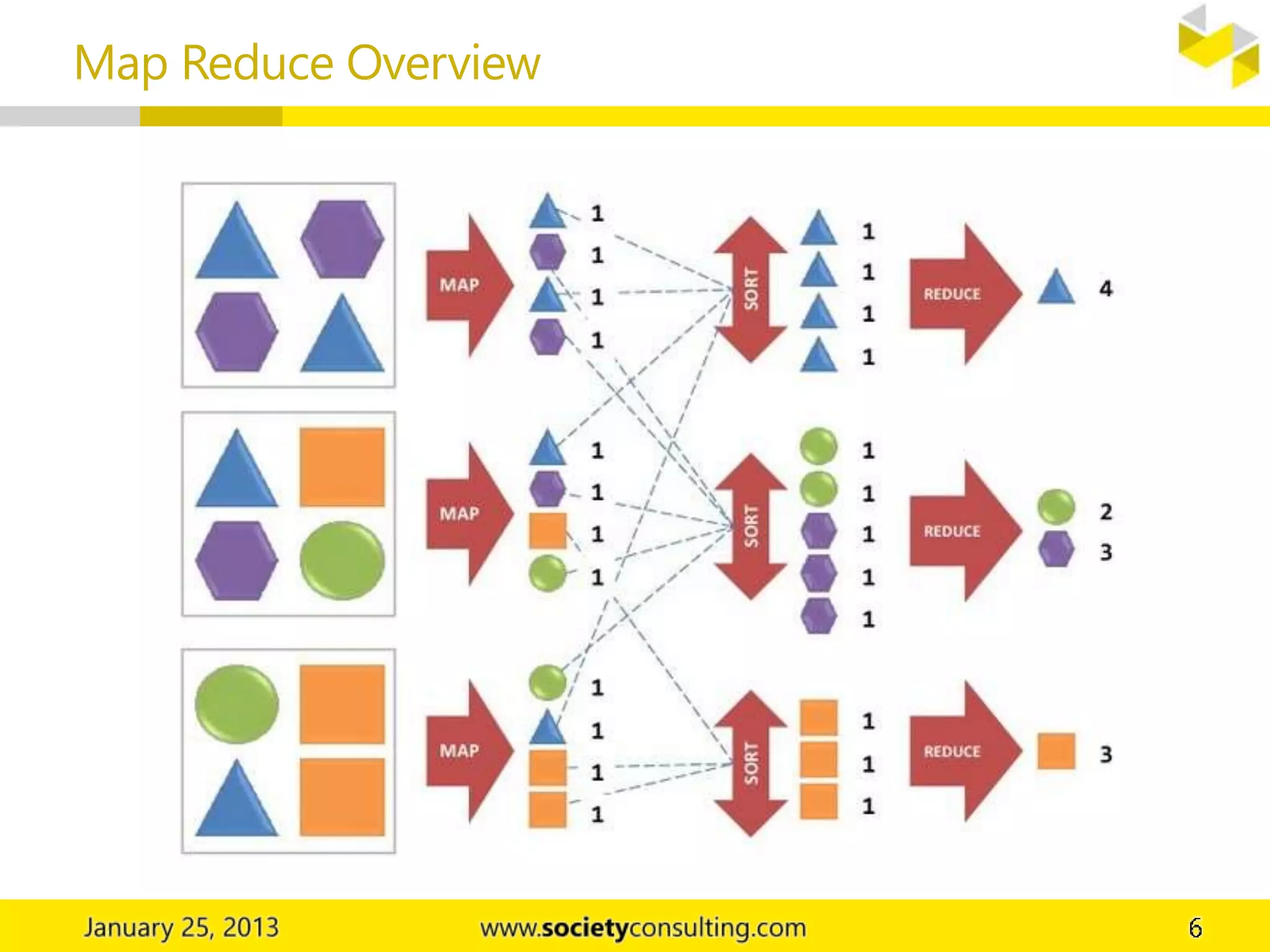
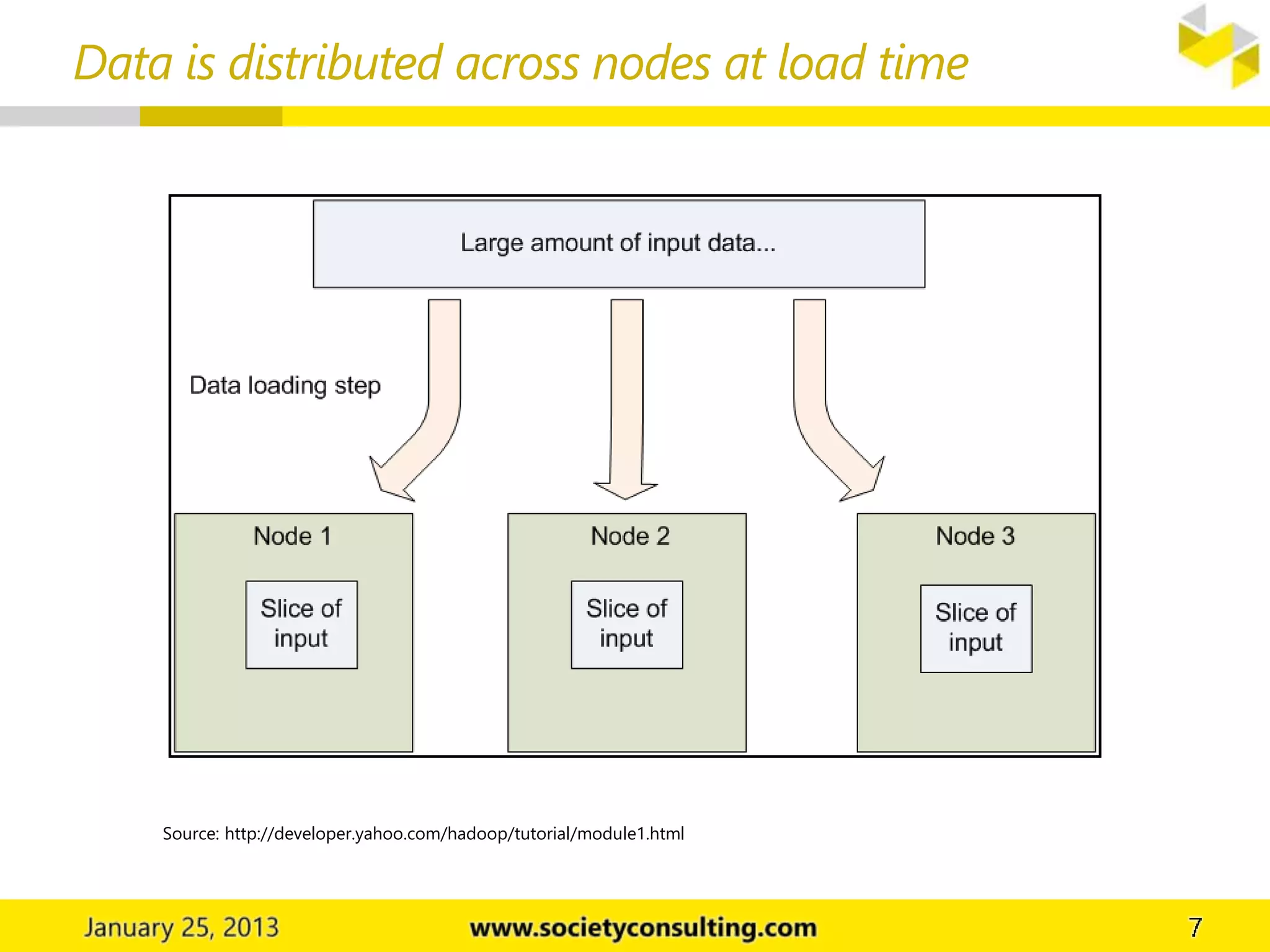
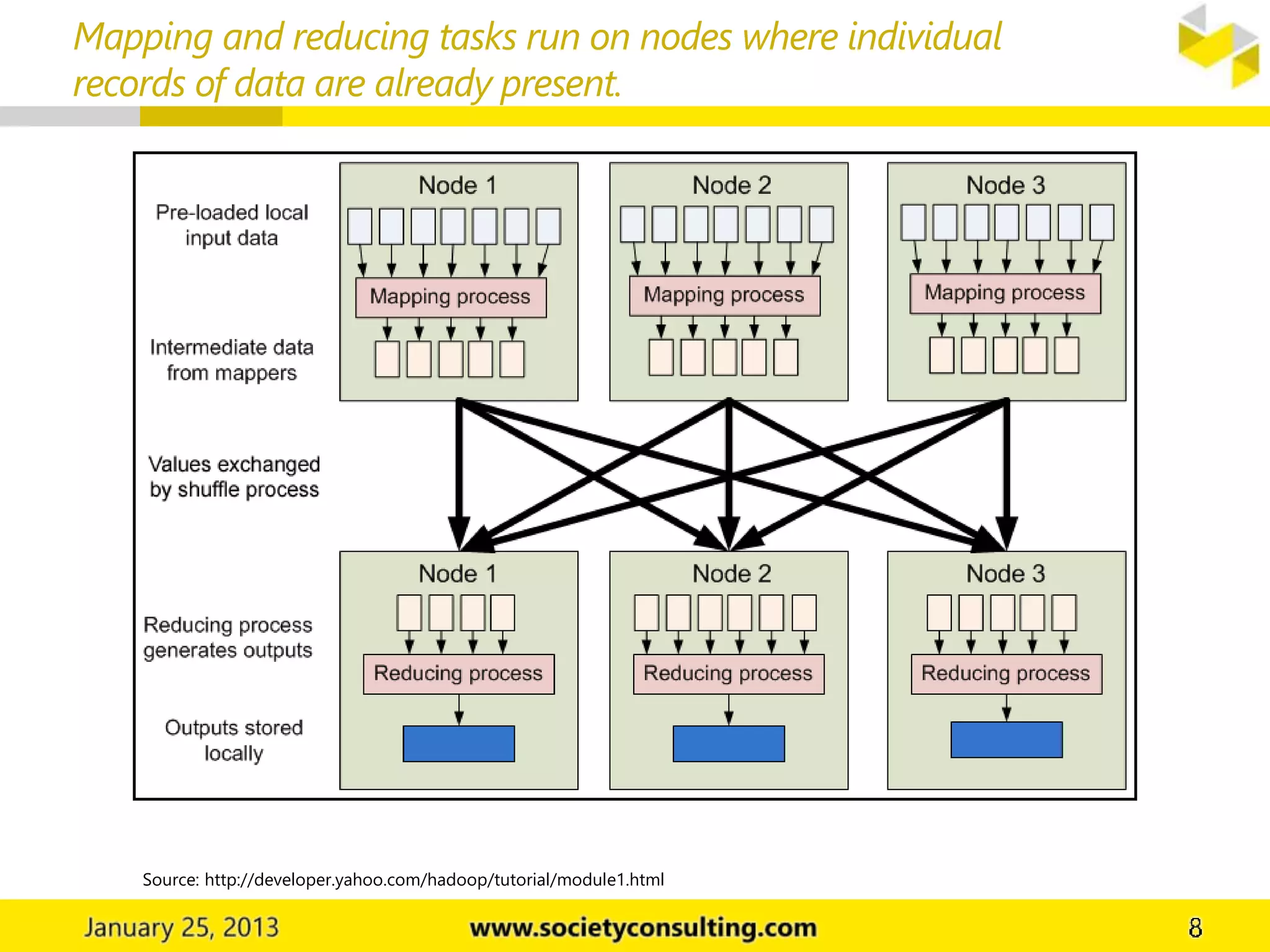
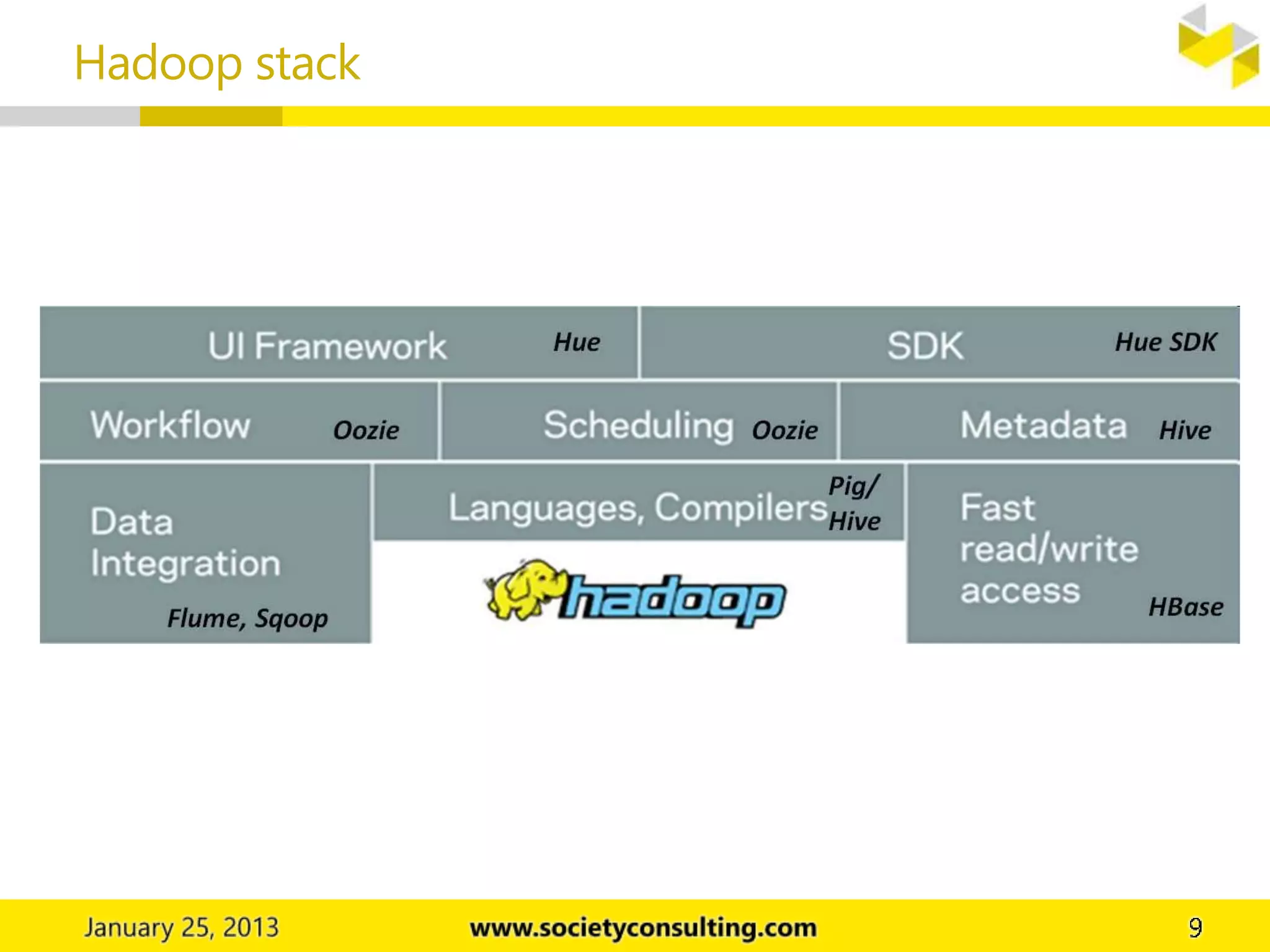


Hadoop is an open source software project that allows for distributed processing of large data sets across clusters of computers. It has two core components: HDFS for data storage, and MapReduce for processing. HDFS stores data across cluster nodes and allows nodes to work on local data. MapReduce consists of map and reduce phases where nodes process data in parallel. Together these components provide fault-tolerant and scalable distributed computing.
















































































