Download to read offline






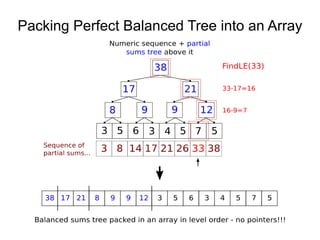
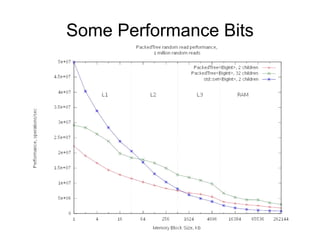
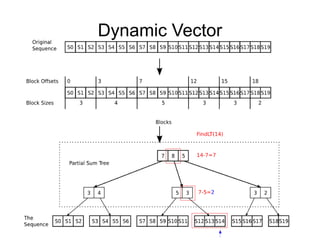
![Dynamic Vector
An ordered sequence of elements (bytes,
integers, strings) of size N
Acess(i) is O(log N)
Insert(i, value) is O(log N)
Delete(i) is O(log N)
We can also define batch operations:
Insert(i, value[])
Delete(i, j)
Split(i); Merge(AnotherVector);...](https://image.slidesharecdn.com/bigdata-150326064518-conversion-gate01/85/Big-Data-8-320.jpg)


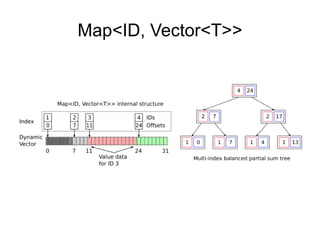

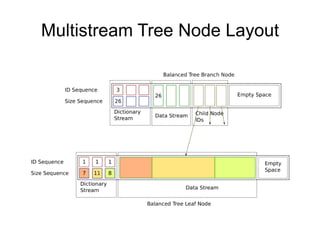
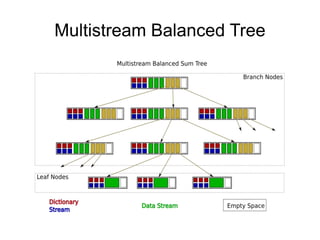

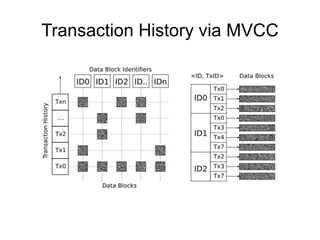

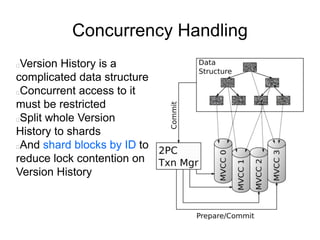
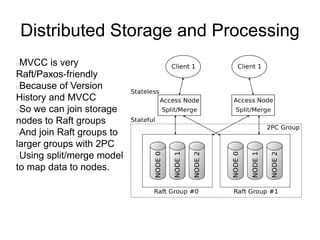
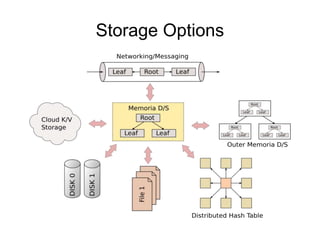


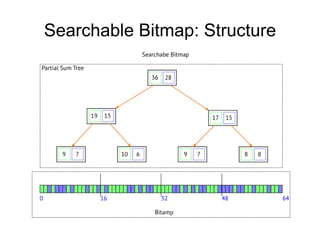
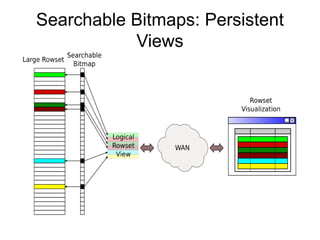
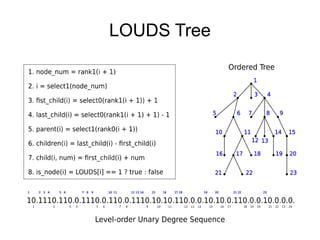
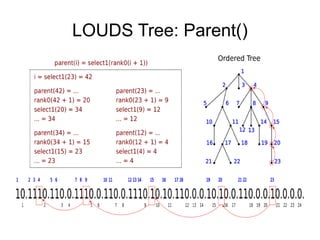

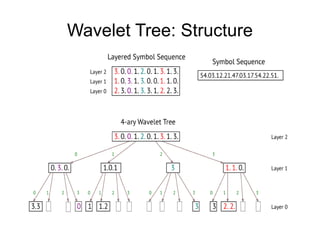
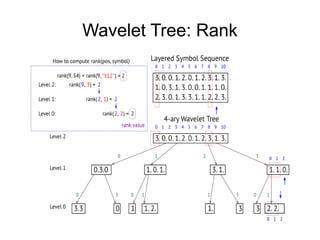
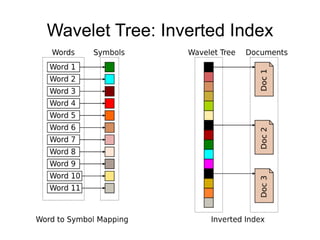
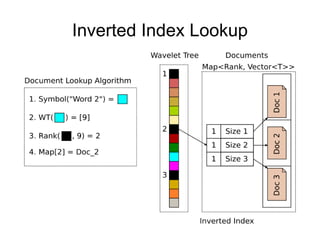


The document discusses advanced non-relational schemas for handling big data, emphasizing the importance of data structures over algorithms in programming. It introduces various data structures such as dynamic vectors, balanced trees, and searchable bitmaps while explaining their time complexities and operations. Additionally, it explores multi-version concurrency control (MVCC) for managing versions of data blocks and enhancing concurrency in distributed storage environments.























































































