ดร.เอกสิทธิ์ พัชรวงศ์ศักดา
ผู้ร่วมก่อตั้งห้างหุ้นส่วนสามัญดาต้า คิวบ์และ
ผู้อำนวยการหลักสูตรวิศวกรรมข้อมูลขนาดใหญ่ (Big Data Engineering)
วิทยาลัยนวัตกรรมด้านเทคโนโลยีและวิศวกรรมศาสตร์ มหาวิทยาลัยธุรกิจบัณฑิตย์
eakasit@datacubeth.ai
Automation Expo 2019
วันพฤหัสบดีที่ 14 มีนาคม 2562
First Step to Big Data
2.
http://dataminingtrend.com http://facebook.com/datacube.th
About us
•ชื่อ: เอกสิทธิ์ พัชรวงศ์ศักดา
• การศึกษา:
• ปริญญาเอก วิทยาการคอมพิวเตอร์
สถาบันเทคโนโลยีนานาชาติสิรินธร (SIIT) มหาวิทยาลัยธรรมศาสตร์
• ปริญญาโท วิศวกรรมคอมพิวเตอร์ มหาวิทยาลัยเกษตรศาสตร์
• ปริญญาตรี วิศวกรรมคอมพิวเตอร์ มหาวิทยาลัยเกษตรศาสตร์
(เกียรตินิยมอันดับ 2)
• ประสบการณ์
• Certified RapidMiner Expert and Ambassador
• Research Collaboration with Western Digital (Thailand) เฟสที่ 1 ระยะเวลา 6 เดือน
• ร่วมวิจัย โครงการสํารวจข้อมูลเพื่อการวิเคราะห์พฤติกรรมของนักท่องเที่ยวเชิงลึก ด้วยวิธีการทําเหมือง
ข้อมูล การท่องเที่ยวแห่งประเทศไทย (ททท)
• วิทยากรอบรมการใช้งานซอฟต์แวร์ open source ทางด้าน data mining
2
http://dataminingtrend.com http://facebook.com/datacube.th
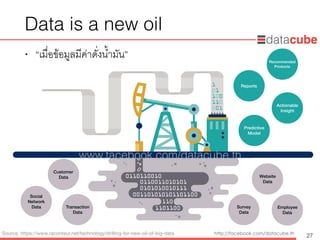
Data isa new oil
• “เมื่อข้อมูลมีค่าดั่งน้ำมัน”
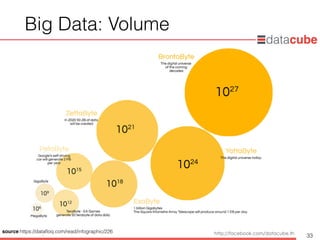
27Source: https://www.raconteur.net/technology/drilling-for-new-oil-of-big-data
Customer
Data
Transaction
Data
Website
Data
Survey
Data
Social
Network
Data Employee
Data
Reports
Actionable
Insight
Predictive
Model
Recommended
Products
www.facebook.com/datacube.th
http://dataminingtrend.com http://facebook.com/datacube.th
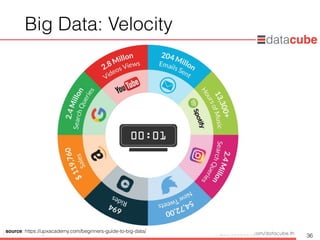
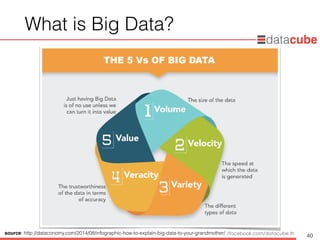
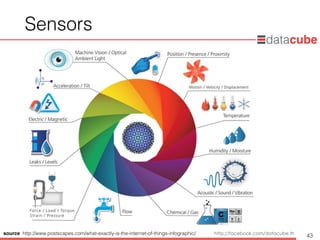
What isBig Data?
• Huge volume of data
• ข้อมูลมีขนาดใหญ่มากๆ เช่น มีจำนวนเป็นพันล้านแถว (billion row) หรือ
เป็นล้านคอลัมน์ (million columns)
• Speed of new data creation and growth
• ข้อมูลเกิดขึ้นอย่างรวดเร็วมากๆ
35
http://dataminingtrend.com http://facebook.com/datacube.th
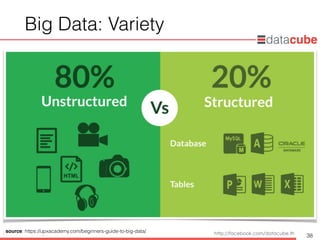
What isBig Data?
• Huge volume of data
• ข้อมูลมีขนาดใหญ่มากๆ เช่น มีจำนวนเป็นพันล้านแถว (billion row) หรือ
เป็นล้านคอลัมน์ (million columns)
• Speed of new data creation and growth
• ข้อมูลเกิดขึ้นอย่างรวดเร็วมากๆ
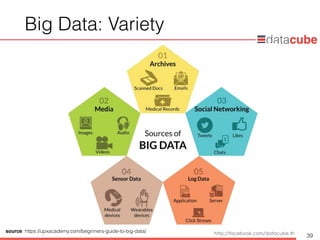
• Complexity of data types and structures
• ข้อมูลมีความหลากหลาย ไม่ได้อยู่ในรูปแบบของตารางเท่านั้น อาจจะเป็น
รูปแบบของข้อความ (text) รูปภาพ (images) หรือ วิดีโอ (video clip)
37
http://dataminingtrend.com http://facebook.com/datacube.th
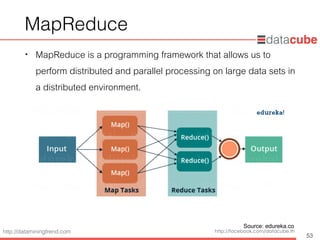
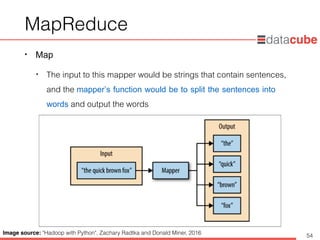
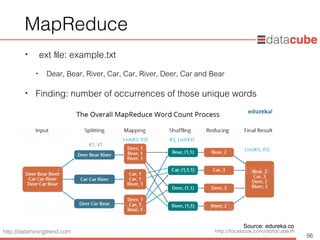
MapReduce
• Map
•The input to this mapper would be strings that contain sentences,
and the mapper’s function would be to split the sentences into
words and output the words
54
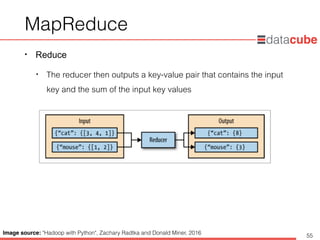
Image source: "Hadoop with Python", Zachary Radtka and Donald Miner, 2016
http://dataminingtrend.com http://facebook.com/datacube.th
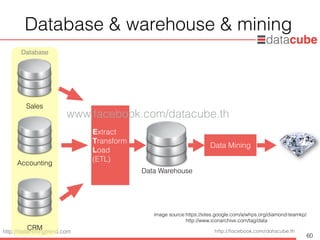
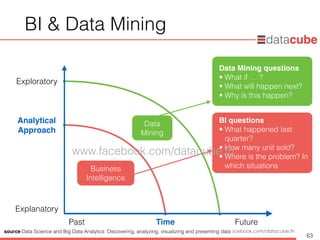
BI &Data Mining
63
Business
Intelligence
Data
Mining
Time
Analytical
Approach
Past Future
Explanatory
Exploratory
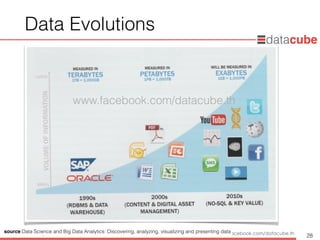
source:Data Science and Big Data Analytics: Discovering, analyzing, visualizing and presenting data
BI questions
• What happened last
quarter?
• How many unit sold?
• Where is the problem? In
which situations
Data Mining questions
• What if … ?
• What will happen next?
• Why is this happen?
www.facebook.com/datacube.th
64.
http://dataminingtrend.com http://facebook.com/datacube.th
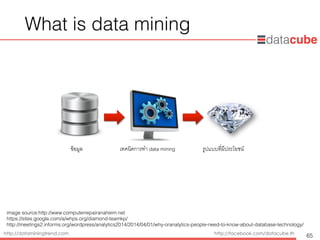
What isdata mining
• “The exploration and analysis of large quantities
of data in order to discover meaningful patterns and
rules” – Data Mining Techniques (3rd Edition)
• เป็นการวิเคราะห์ข้อมูล เพื่อหารูปแบบ (patterns) หรือความสัมพันธ์
(relation) ระหว่างข้อมูลในฐานข้อมูลขนาดใหญ่
• “Extraction of interesting (non-trivial, previously,
unknown and potential useful) information from data in
large databases” – Data Mining Concepts &
Techniques (3rd Edition)
• เป็นกระบวนการดึงข่าวสารที่น่าสนใจ และมีประโยชน์แต่ไม่เคยรู้มา
ก่อนจากฐานข้อมูลขนาดใหญ่
64
image sources: https://binarylinks.wordpress.com/tag/data-mining/
http://www.amazon.com/Data-Mining-Techniques-Relationship-Management/dp/0470650931
65.
http://dataminingtrend.com http://facebook.com/datacube.th
What isdata mining
65
ข้อมูล' เทคนิคการทำ data mining' รูปแบบที่มีประโยชน์'
image source:http://www.computerrepairanaheim.net
https://sites.google.com/a/whps.org/diamond-teamkp/
http://meetings2.informs.org/wordpress/analytics2014/2014/04/01/why-oranalytics-people-need-to-know-about-database-technology/
http://dataminingtrend.com http://facebook.com/datacube.th
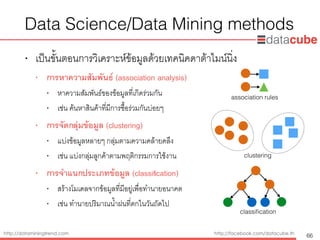
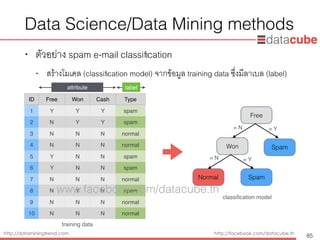
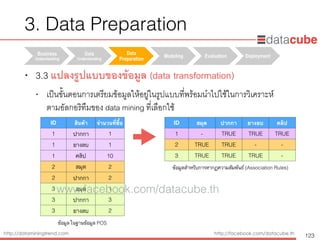
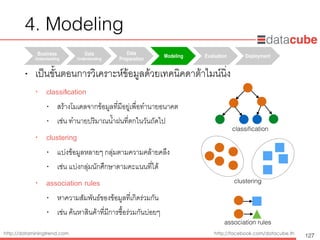
Data Science/DataMining methods
• ตัวอย่าง spam e-mail classification
• สร้างโมเดล (classification model) จากข้อมูล training data ซึ่งมีลาเบล (label)
85
ID Free Won Cash Type
1 Y Y Y spam
2 N Y Y spam
3 N N N normal
4 N N N normal
5 Y N N spam
6 Y N N spam
7 N N N normal
8 N Y N spam
9 N N N normal
10 N N N normal
attribute label
Free
Won
Normal Spam
Spam
classification model
= N = Y
= N = Y
training data
www.facebook.com/datacube.th
86.
http://dataminingtrend.com http://facebook.com/datacube.th
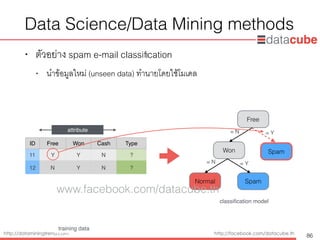
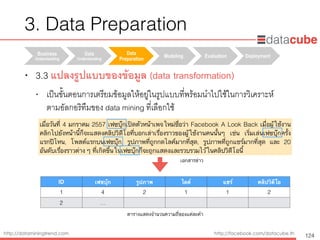
Data Science/DataMining methods
• ตัวอย่าง spam e-mail classification
• นำข้อมูลใหม่ (unseen data) ทำนายโดยใช้โมเดล
86
attribute
Free
Won
Normal Spam
Spam
classification model
= N = Y
= N = Y
training data
ID Free Won Cash Type
11 Y Y N ?
12 N Y N ?
www.facebook.com/datacube.th
87.
http://dataminingtrend.com http://facebook.com/datacube.th
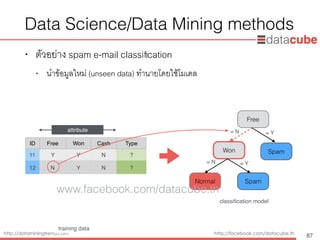
Data Science/DataMining methods
• ตัวอย่าง spam e-mail classification
• นำข้อมูลใหม่ (unseen data) ทำนายโดยใช้โมเดล
87
attribute
Free
Won
Normal Spam
Spam
classification model
= N = Y
= N = Y
training data
ID Free Won Cash Type
11 Y Y N ?
12 N Y N ?
www.facebook.com/datacube.th
88.
http://dataminingtrend.com http://facebook.com/datacube.th
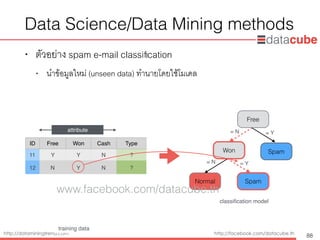
Data Science/DataMining methods
• ตัวอย่าง spam e-mail classification
• นำข้อมูลใหม่ (unseen data) ทำนายโดยใช้โมเดล
88
attribute
Free
Won
Normal Spam
Spam
classification model
= N = Y
= N = Y
training data
ID Free Won Cash Type
11 Y Y N ?
12 N Y N ?
www.facebook.com/datacube.th
89.
http://dataminingtrend.com http://facebook.com/datacube.th
• ตัวอย่างspam e-mail classification
ID Free Won Cash Type
1 Y Y Y spam
2 N Y Y spam
3 N N N normal
4 N N N normal
5 Y N N spam
Classification example
89
attribute labelID
training data
สร้าง classification model
ID Free Won Cash Type
11 Y Y N ?
12 N Y N ?
unseen data
classification model
ID Type
11 spam
12 spam
1
2
3 4
www.facebook.com/datacube.th
90.
http://dataminingtrend.com http://facebook.com/datacube.th
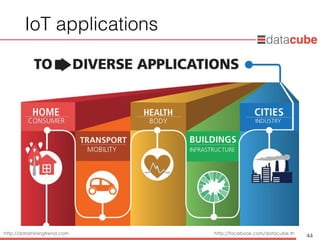
• แนะนำข้อมูลขนาดใหญ่(Big Data)
• แนะนำเทคโนโลยี Internet of Things (IoT)
• แนะนำเทคโนโลยีการจัดการข้อมูลขนาดใหญ่
• แนะนำเทคนิคการวิเคราะห์ข้อมูลด้วยดาต้า ไมน์นิง
• ตัวอย่างการประยุกต์ใช้งาน
• กระบวนการมาตรฐานในการวิเคราะห์ข้อมูลด้วยเทคนิคดาต้า ไมน์นิง
หัวข้อการบรรยาย
90
http://dataminingtrend.com http://facebook.com/datacube.th
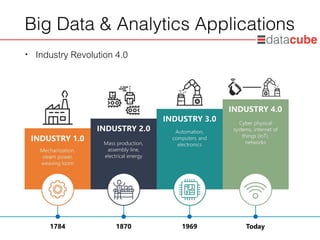
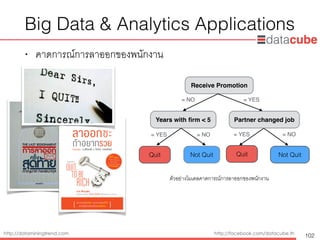
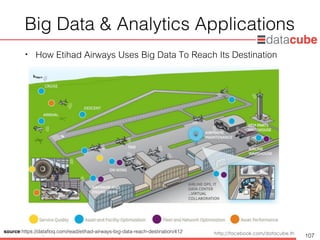
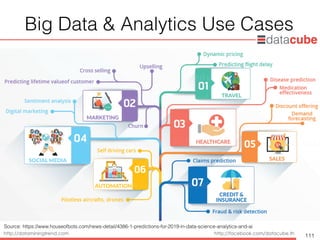
Big Data& Analytics Applications
• คาดการณ์การลาออกของพนักงาน
102
Receive Promotion
= NO = YES
Years with firm < 5
Not Quit
= YES = NO
Partner changed job
Quit Not Quit
= YES = NO
Quit
ตัวอย่างโมเดลคาดการณ์การลาออกของพนักงาน
http://dataminingtrend.com http://facebook.com/datacube.th
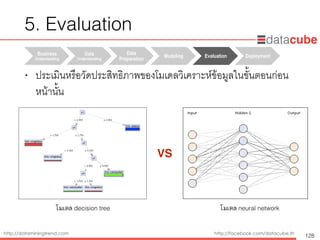
Data ScienceUse cases
108
• Churn Prevention
• Identify customers likely to leave, take
preventative action.
• Customer Lifetime Value
• Distinguish between customers based on
business value.
• Customer Segmentation
• Create meaningful customer groups for
more relevant interactions.
• Demand Forecasting
• Know what volumes to expect to improve
planning.
• Fraud Detection
• Identify fraudulent activity quickly, and
end it.
• Next Best Action
• The right action at the right time for the
right customer.
• Price Optimization
• Set prices that balance demand, profit,
and risk.
• Product Propensity
• Predict what your customers will buy,
before even they know it.
109.
http://dataminingtrend.com http://facebook.com/datacube.th
Data ScienceUse cases
109
• Text Mining
• Extract insight from unstructured content.
• Next Best Action
• The right action at the right time for the
right customer.
• Price Optimization
• Set prices that balance demand, profit,
and risk.
• Product Propensity
• Predict what your customers will buy,
before even they know it.
• Quality Assurance
• Resolve quality issues before they
become a problem.
• Predictive Maintenance
• Predict equipment failure, plan cost-
effective maintenance.
• Risk Management
• Understand risk to manage it.
• Up- and Cross-Selling
• Convince customers to buy more.
http://dataminingtrend.com http://facebook.com/datacube.th
• แนะนำข้อมูลขนาดใหญ่(Big Data)
• แนะนำเทคโนโลยี Internet of Things (IoT)
• แนะนำเทคโนโลยีการจัดการข้อมูลขนาดใหญ่
• แนะนำเทคนิคการวิเคราะห์ข้อมูลด้วยดาต้า ไมน์นิง
• ตัวอย่างการประยุกต์ใช้งาน
• กระบวนการมาตรฐานในการวิเคราะห์ข้อมูลด้วยเทคนิคดาต้า
ไมน์นิง
หัวข้อการบรรยาย
112
113.
http://dataminingtrend.com http://facebook.com/datacube.th
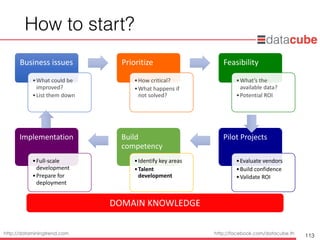
How tostart?
113
ow To Start?
Implementation
•Full-scale
development
•Prepare for
deployment
Build
competency
•Identify key areas
•Talent
development
Pilot Projects
•Evaluate vendors
•Build confidence
•Validate ROI
DOMAIN KNOWLEDGE
Business issues
•What could be
improved?
•List them down
Prioritize
•How critical?
•What happens if
not solved?
Feasibility
•What’s the
available data?
•Potential ROI
114.
http://dataminingtrend.com http://facebook.com/datacube.th
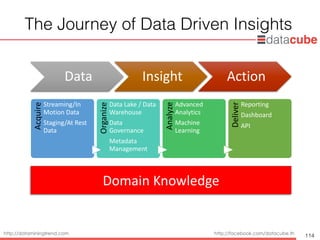
The Journeyof Data Driven Insights
114
Data Insight Action
The Journey of Data Driven InsightsAcquire
Streaming/In
Motion Data
Staging/At Rest
Data
OrganizeData Lake / Data
Warehouse
Data
Governance
Metadata
Management
Analyze
Advanced
Analytics
Machine
Learning
Deliver
Reporting
Dashboard
API
Domain Knowledge
115.
http://dataminingtrend.com http://facebook.com/datacube.th
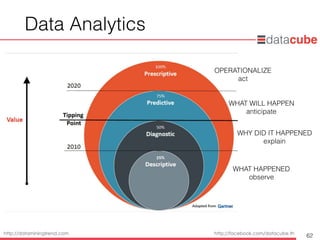
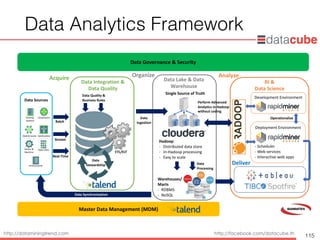
Data AnalyticsFramework
115
Data Sources
Web & Social
Existing
Systems
Clickstream
Geolocation
Sensor &
Machine
Open Data
Unstructured
Data Quality &
Business Rules
Data
Stewardship
Data Integration &
Data Quality
Data
Ingestion
ETL/ELT
Data Lake & Data
Warehouse
Hadoop:
- Distributed data store
- In-Hadoop processing
- Easy to scale
Data Synchronization
BI &
Data Science
Development Environment
Deployment Environment
- Scheduler
- Web services
- Interactive web apps
Operationalize
Batch
Stream
Real-Time
Data Governance & Security
Master Data Management (MDM)
Perform Advanced
Analytics in-Hadoop
without coding
Single Source of Truth
Warehouses/
Marts
- RDBMS
- NoSQL
Data
Processing
Acquire Organize Analyze
Deliver
http://dataminingtrend.com http://facebook.com/datacube.th
References
• AndrewChisholm, Exploring Data with RapidMiner, November 2013
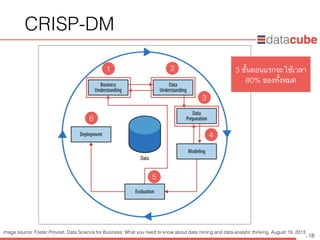
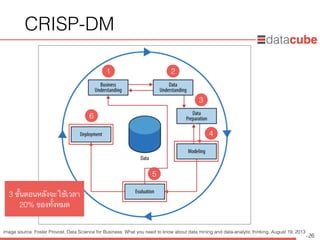
• Markus Hofmann, Ralf Klinkenberg, RapidMiner: Data Mining Use Cases and
Business Analytics Applications, October 25, 2013
• Foster Provost, Data Science for Business: What you need to know about
data mining and data-analytic thinking, August 19, 2013
• Eakasit Pacharawongsakda, An Introduction to Data Mining Techniques (Thai
version), 2014
130








































































































![วิชาการผลิตมัลติมีเดีย 1 [Multimedia I]](https://cdn.slidesharecdn.com/ss_thumbnails/1-140522010448-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































