This document is a dissertation submitted by Steven Berard in partial fulfillment of the requirements for a Master of Science degree in Electrical Engineering from New Mexico State University. The dissertation evaluates the ability of artificial neural networks to localize dipole sources within a high-resolution realistic head model using different sensor configurations and levels of noise. Results show that neural networks can localize dipoles with accuracy even in the presence of noise, and that performance generally improves with more sensors and complex network architectures.










![LIST OF FIGURES
1 Example of a Single Neuron . . . . . . . . . . . . . . . . . . . . . 5
2 Example of a Single Layer of Neurons . . . . . . . . . . . . . . . . 6
3 Example of a Three Layer of Neural Network . . . . . . . . . . . . 7
4 Example of a Single Dipole in a 2D Airhead Model . . . . . . . . 13
5 Sensor and Training Dipole Locations for 2D Homogeneous Head
Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
6 FMRI Image Used for Realistic Head Model (ITK-SNAP [13]) . . 16
7 Sensor Placement for 32 Electrodes . . . . . . . . . . . . . . . . . 17
8 Sensor Placement for 64 Electrodes . . . . . . . . . . . . . . . . . 19
9 Sensor Placement for 128 Electrodes . . . . . . . . . . . . . . . . 19
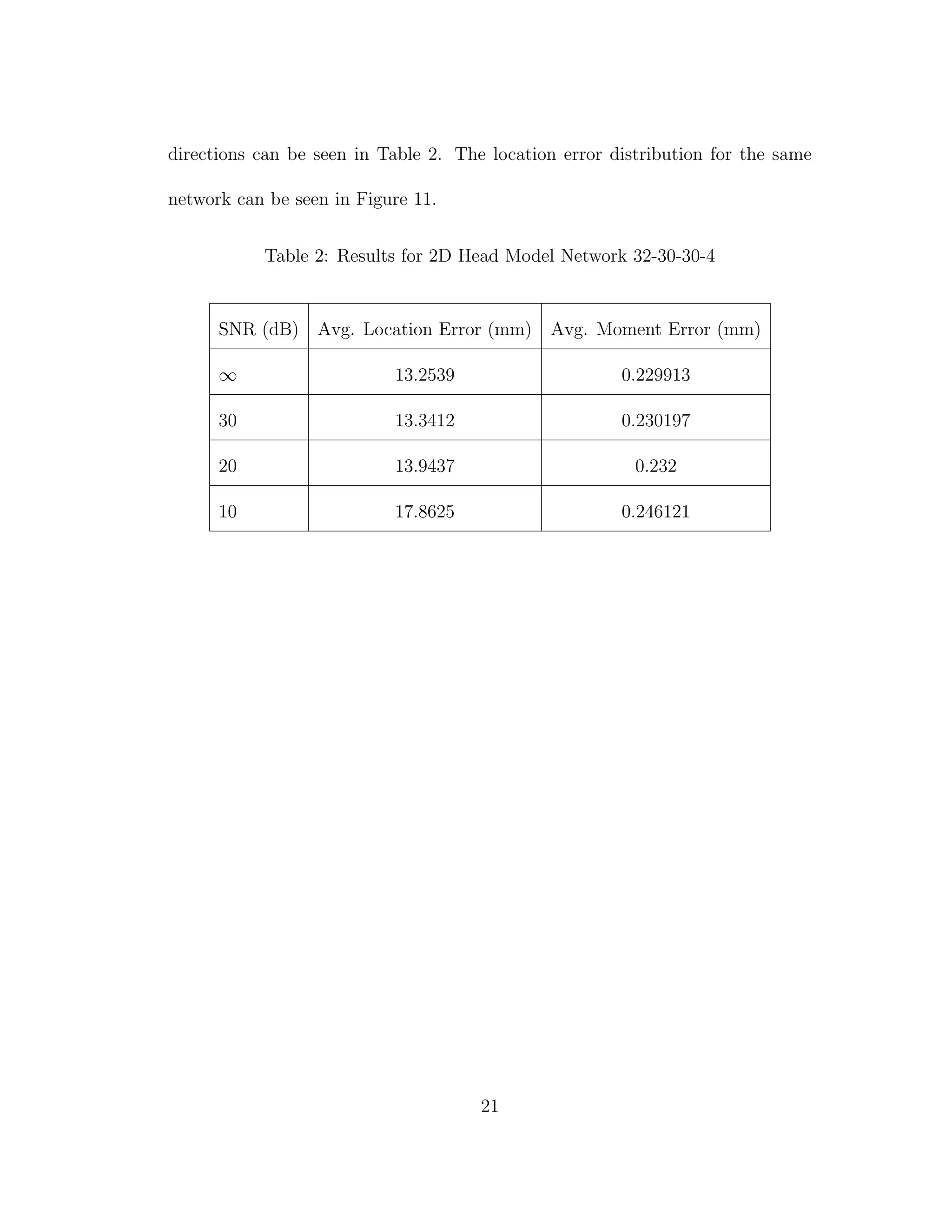
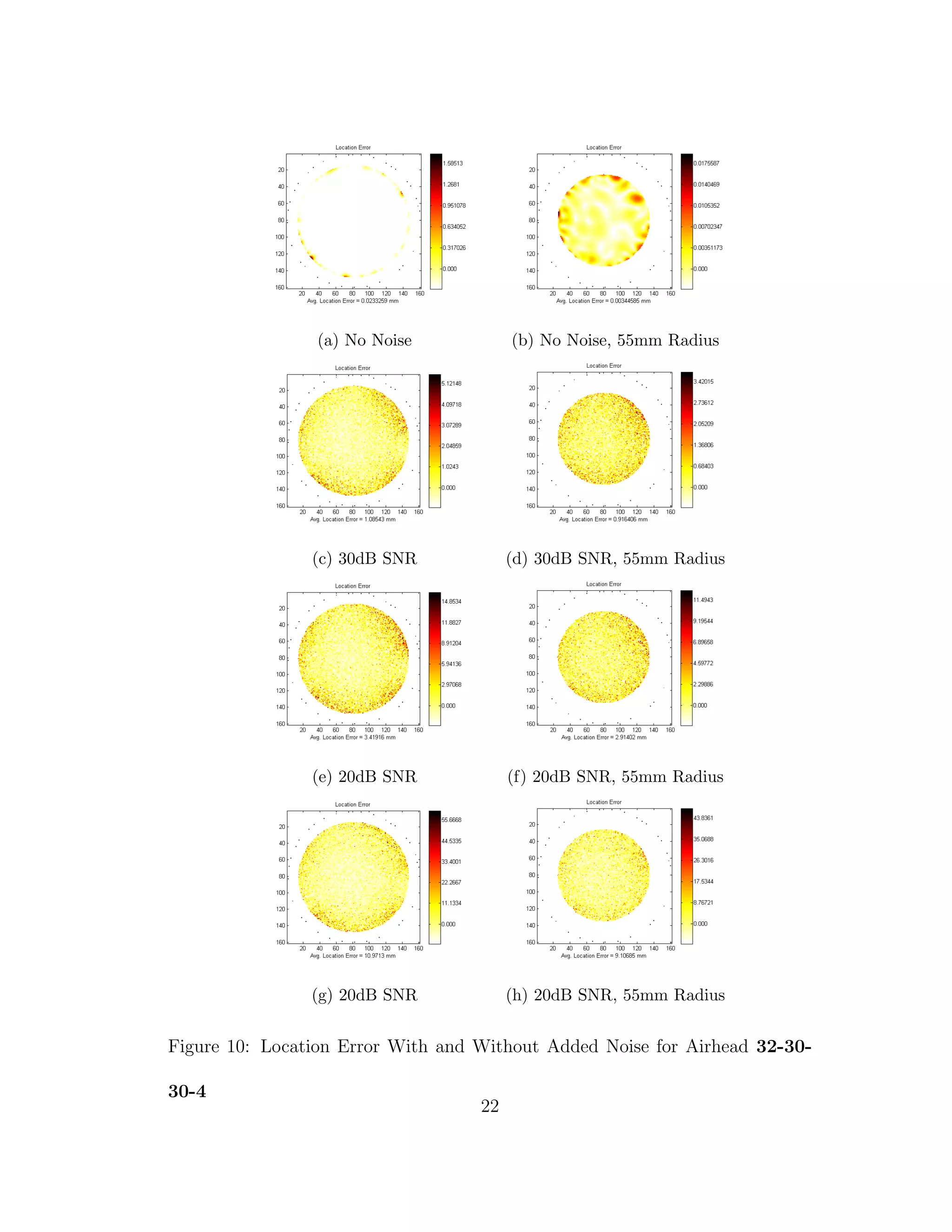
10 Location Error With and Without Added Noise for Airhead 32-
30-30-4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
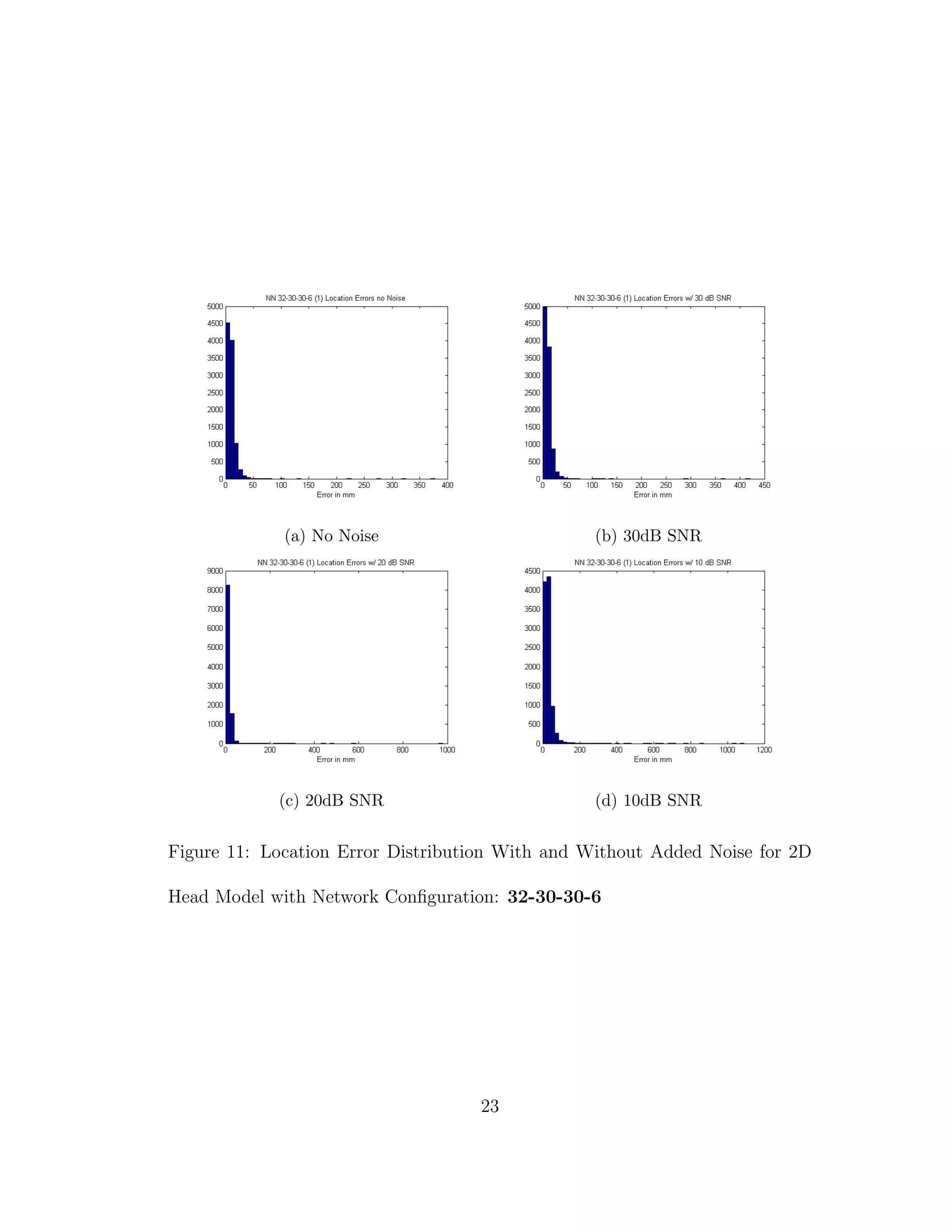
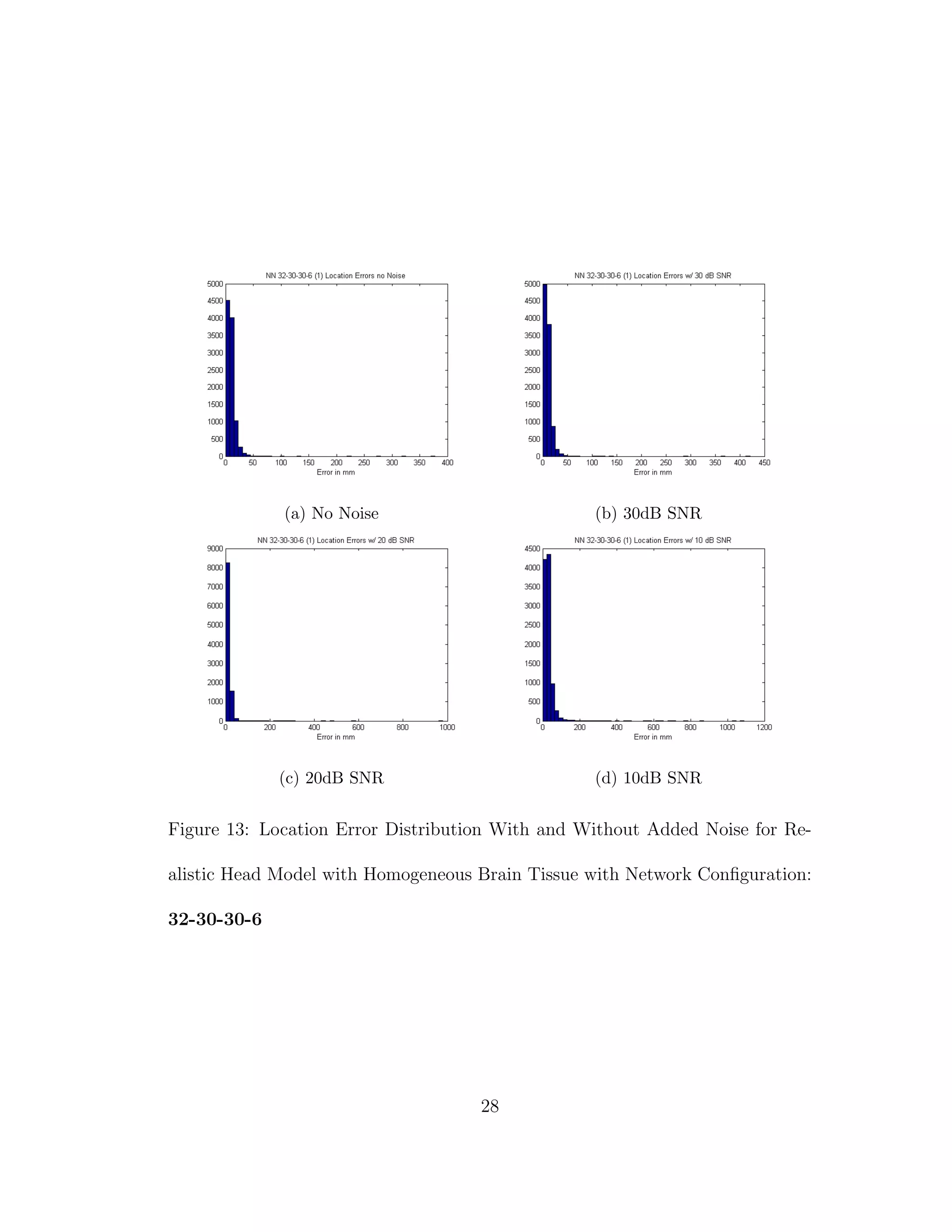
11 Location Error Distribution With and Without Added Noise for
2D Head Model with Network Configuration: 32-30-30-6 . . . . 23
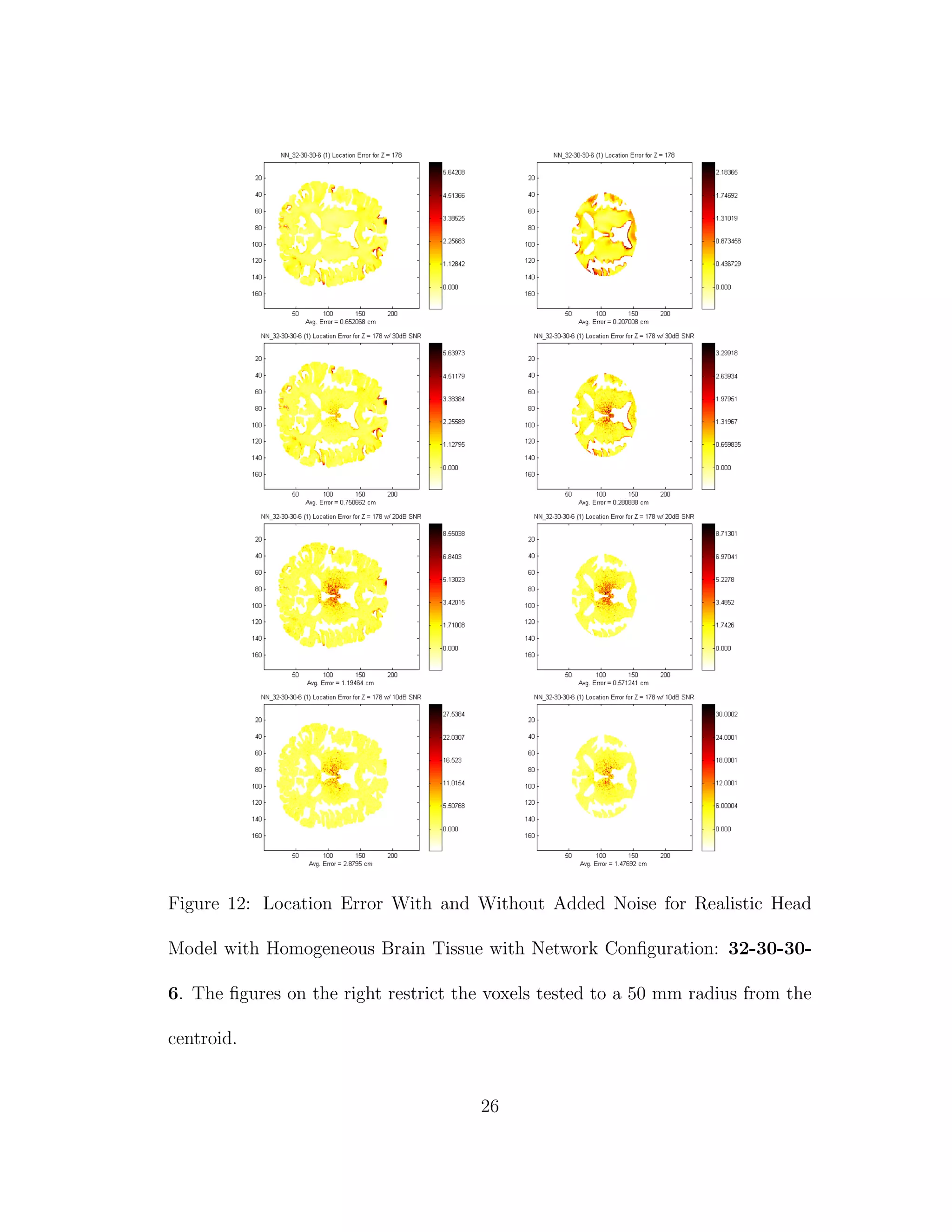
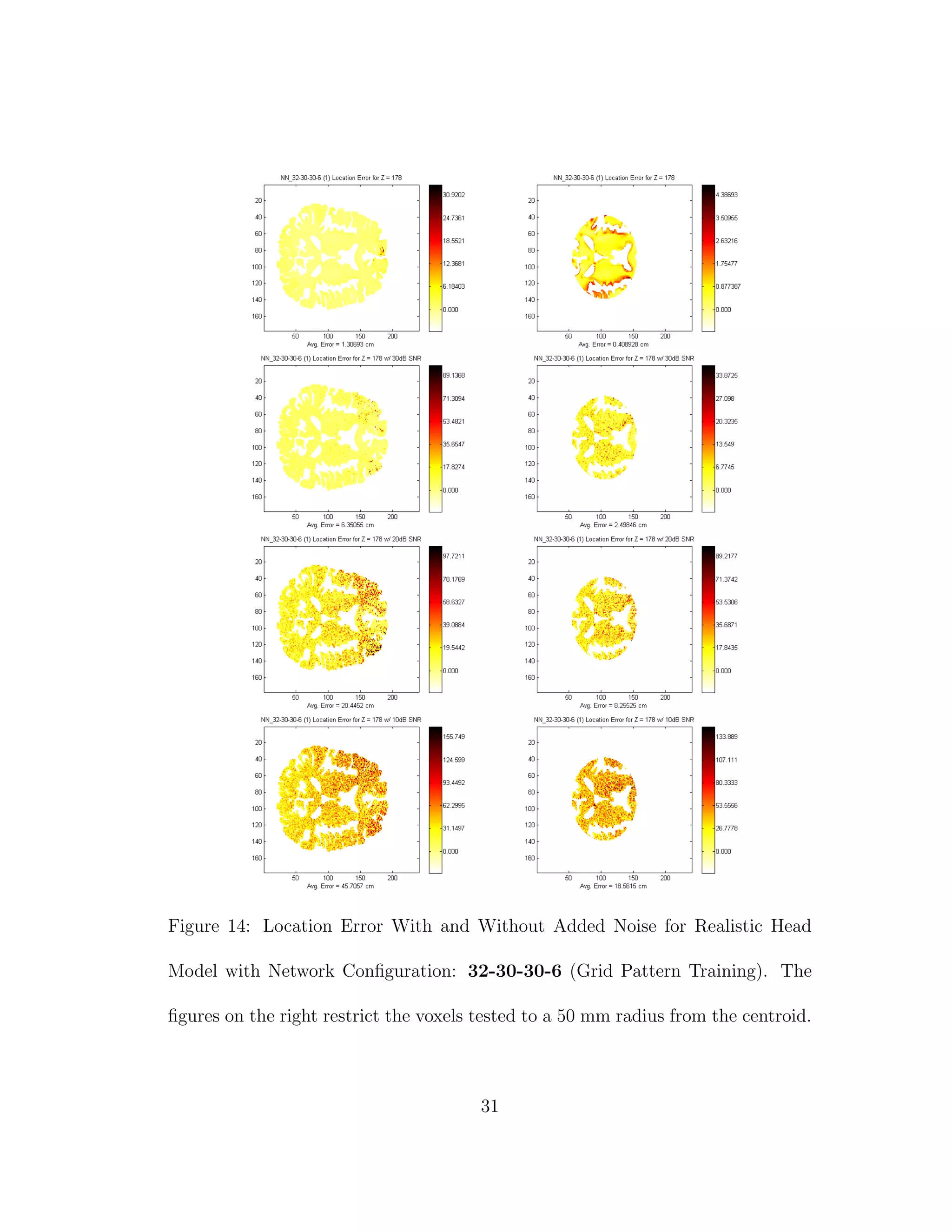
12 Location Error With and Without Added Noise for Realistic Head
Model with Homogeneous Brain Tissue with Network Configura-
tion: 32-30-30-6. The figures on the right restrict the voxels tested
to a 50 mm radius from the centroid. . . . . . . . . . . . . . . . . 26
xi](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-11-2048.jpg)



![1 INTRODUCTION
The brain is widely recognized as the main controller of the human body. It
is also extremely hard to study without causing harm to the subject. Electroen-
cephalography (EEG) is a promising method for studying the way the brain works
using only passive means of observation. Unfortunately there is still the problem
of interpreting the data that we receive from EEG readings into accurate data
that we can use.
Source location is a significant problem due to the fact that it is ill posed.
Given a set of potentials for the electrodes there is an infinite number of possible
dipole strengths and locations that could have created this data set. There have
been many proposed solutions to this problem: iterative techniques, beamforming,
and artificial neural networks. Iterative techniques require immense amounts of
computations to arrive at their solutions and are not very robust to noise [2].
Beamformers have been shown to localize well with and without the presence of
noise [4], however they are still rather computationally intensive and are difficult
to impossible to perform in real time. Artificial neural networks (ANNs) could
provide us with a solution that is robust to noise [1][2][10][14][15] and can make
accurate location predictions fast enough to work in real time [10].
The ability to accurately detect brain activity location in real time could
lead to breakthroughs in psychology and thought activated devices. At the time of
1](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-15-2048.jpg)
![writing I have only found one published article that tests artificial neural networks
with a realistic head model [10]. In said article the model was not as detailed as
models we could create today. While ANNs have been shown to be accurate
enough using simplistic head models, can an ANN show similar results if the head
is more complex, more closely related to our own heads?
2](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-16-2048.jpg)
![2 THEORY
This paper requires the knowledge of two subjects, the process for which the
forward solution was obtained, Finite Difference Neuroelectromagnetic Modeling
Software (FNS), and the process for which the inverse solution was obtained,
artificial neural networking.
2.1 FNS: Finite Difference Neuroelectromagnetic Modeling Software
The Finite Difference Neuroelectromagnetic Modeling Software (FNS) written
by Hung Dang [3] is a realistic head model EEG forward solution package. It
uses finite difference formulation for a general inhomogeneous anisotropic body
to obtain the system matrix equation, which is then solved using the conjugate
gradient algorithm. Reciprocity is then utilized to limit the number of solutions
to a manageable level.
This software attempts to solve the Poisson equation that governs electric
potential φ:
· (σ φ) = · Ji (1)
where σ is the conductivity and Ji is the impressed current density. It accom-
plishes this using the finite difference approximation for the Laplacian:
3](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-17-2048.jpg)



![Figure 3: Example of a Three Layer of Neural Network
matrix, P, to the output matrix, A3
, is
A3
= f3
(W3
f2
(W2
f1
(W1
P + b1
) + b2
) + b3
)
2.2.1 Backpropagation
The best part about neural networks is their ability to replicate complex sys-
tems with only knowing input-output combinations. There are basically two ways
for a network to do this, supervised and unsupervised learning. For this paper we
will focus on supervised learning. The most common form of supervised learning
is the backpropagation method [1]. The backpropagation method uses calculus’
Chain Rule to propagate the mean square error of an input-output pair back
7](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-21-2048.jpg)

![of Newton’s method that was designed for minimizing functions that are sums of
squares of other nonlinear functions” [5]. It is a batch learning algorithm that
can adjust its learning rate in order to find the best weights and biases in the
fewest number of iterations. The main problem with this method is the extreme
memory requirement with larger networks. For example Matlab required around
40 gigabytes of virtual memory during the training of each of the 128-30-30-6
networks discussed in this paper.
Definition 2.2. The Levenberg-Marquardt backpropagation algorithm is as fol-
lows:
1. For Q input-output pairs, run all inputs through the network to obtain the
errors, Eq = Tq − AM
q . Then determine the sum of squared errors over all
inputs, F(x).
F(x) =
Q
q=1
(Tq − Aq) (Tq − Aq) (10)
9](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-23-2048.jpg)
![2. Determine the Jacobian matrix:
J(x) =
∂e1,1
∂w1
1,1
∂e1,1
∂w1
1,2
· · ·
∂e1,1
∂w1
S1,R
∂e1,1
∂b1
1
· · ·
∂e2,1
∂w1
1,1
∂e2,1
∂w1
1,2
· · ·
∂e2,1
∂w1
S1,R
∂e2,1
∂b1
1
· · ·
...
...
...
...
∂eSM ,1
∂w1
1,1
∂eSM ,1
∂w1
1,2
· · ·
∂eSM ,1
∂w1
S1,R
∂eSM ,1
∂b1
1
· · ·
∂e1,2
∂w1
1,1
∂e1,2
∂w1
1,2
· · ·
∂e1,2
∂w1
S1,R
∂e1,2
∂b1
1
· · ·
...
...
...
...
(11)
Calculate the sensitivities:
˜sm
i,h ≡
∂vh
∂nm
i,q
=
∂ek,q
∂nm
i,q
(Marquardt Sensitivity) where h = (q−1)SM
+k (12)
˜SM
q = − ˙FM
(nM
q ) (13)
˜Sm
q = ˙F(nm
q )(Wm+1
) ˜Sm+1
q (14)
˜Sm
= ˜Sm
1
˜Sm
2 · · · ˜Sm
Q
(15)
And compute the elements of the Jacobian matrix:
[J]h,l =
∂vh
∂xl
=
∂ek,q
∂wm
i,j
=
∂ek,q
∂nm
i,q
×
∂nm
i,q
∂wm
i,j
= ˜sm
i,h ×
∂nm
i,q
∂wm
i,j
= ˜sm
i,h × am−1
j,q
for weight xl (16)
[J]h,l =
∂vh
∂xl
=
∂ek,q
∂bm
i
=
∂ek,q
∂nm
i,q
×
∂nm
i,q
∂bm
i
= ˜sm
i,h ×
∂nm
i,q
∂bm
i
= ˜sm
i,h
for bias xl (17)
10](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-24-2048.jpg)
![Where:
v = v1 v2 · · · vN
= e1,1 e2,1 · · · eSM ,1 e1,2 · · · eSM ,Q
(18)
x = x1 x2 · · · xN
= w1
1,1 w1
1,2 · · · w1
S1,R b1
1 · · · b1
S1 w2
1,1 · · · bM
SM
(19)
3. Solve:
∆xk = −[J (xk)J(xk) + µkI]−1
J (xk)v(xk) (20)
4. Compute F(x), Eq (10), using xk + ∆xk. If the result is less than the
previous F(x) divide µ by ϑ, let xk+1 = xk + ∆xk and go back to step 1. If
not, multiply µ by ϑ and go back to step 3. The variable, ϑ, must be greater
than 1 (e.g., ϑ = 10).
11](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-25-2048.jpg)

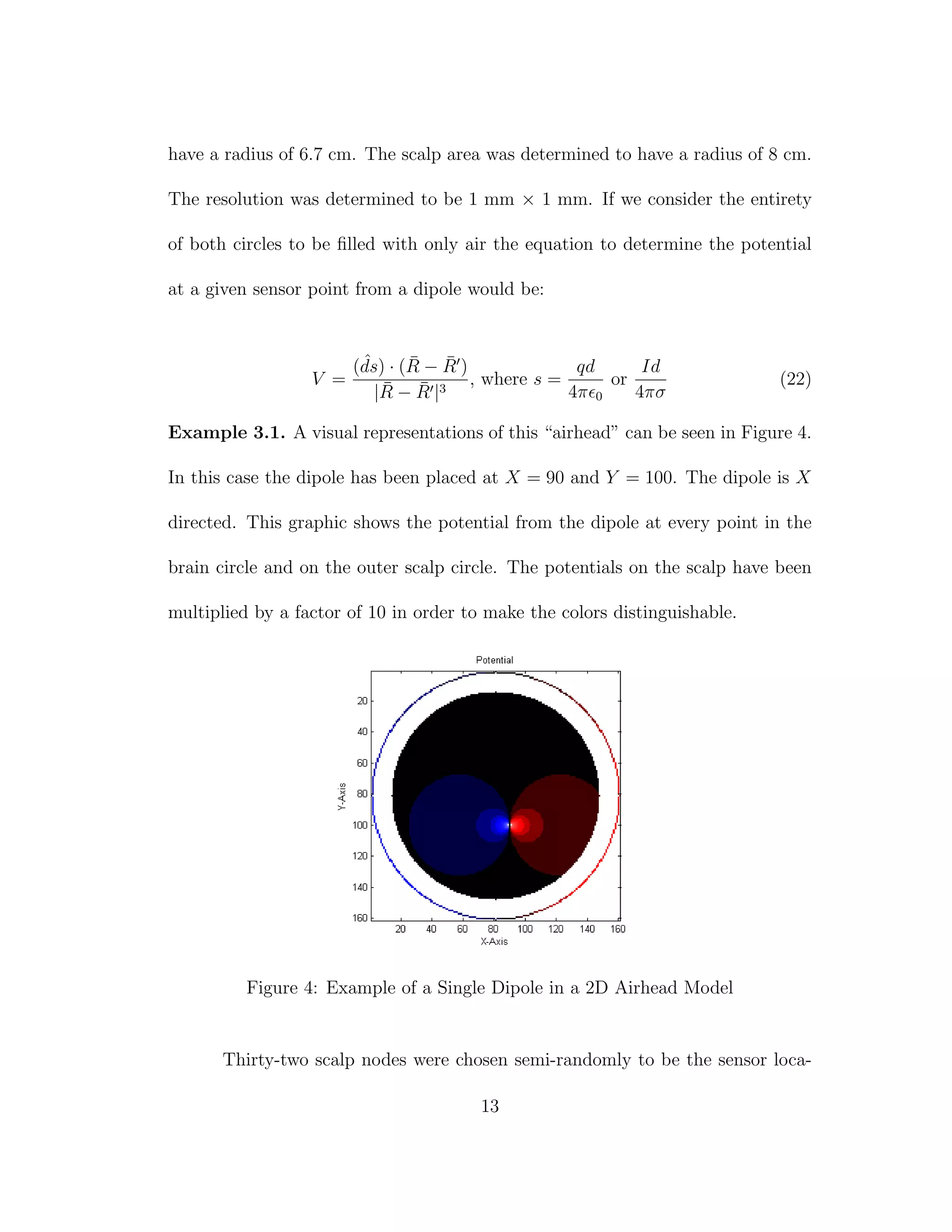
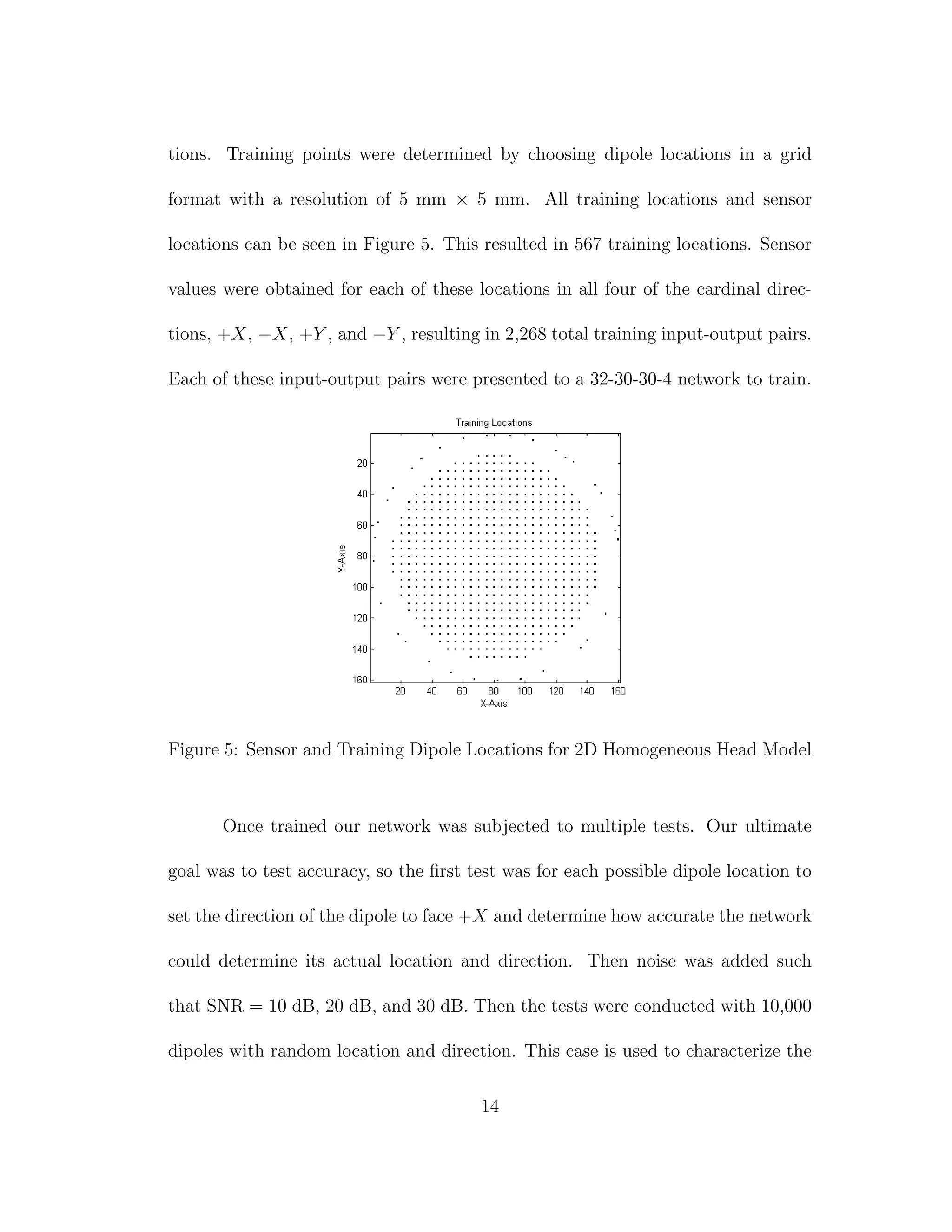
![general accuracy of the network. In all cases each dipole was required to have the
same magnitude.
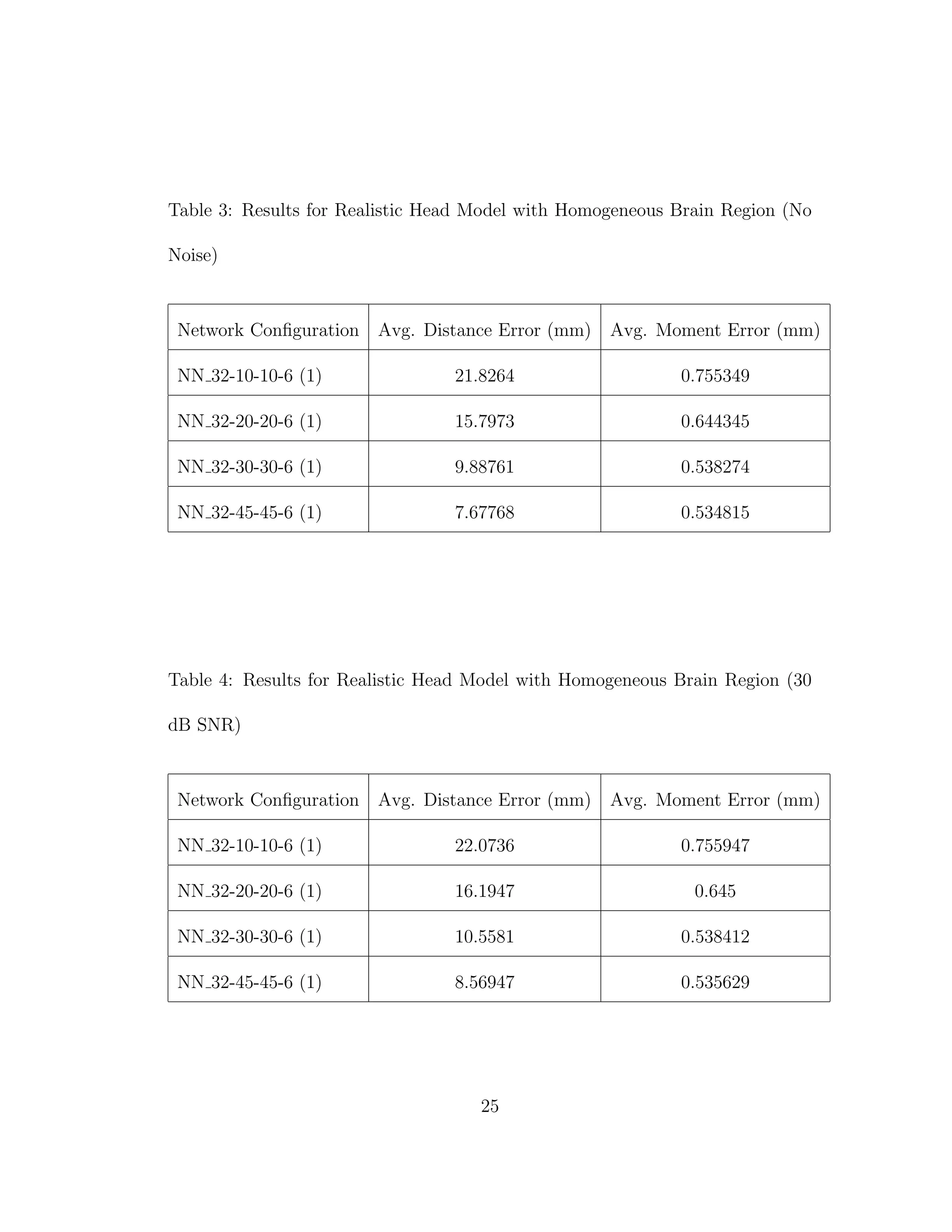
3.2 Realistic Head Model - Homogeneous Brain Region
In order to create a truly realistic head model we must start with an FMRI
image such as can be seen in Figure 6. The FMRI image used had a resolution of
1 mm × 1 mm × 1 mm. The image was segmented using the program, FSL [6].
The segmented image was then fed into FNS [3] to obtain the reciprocity data
for all possible dipole locations at the chosen sensor locations. Sensor locations
were chosen according to the International 10-20 system for 32 electrodes. The
placement of these sensors can be seen in Figure 7. In order to make the brain
area homogeneous the conductivity of the white matter was changed to that of
grey matter. The conductivities can be seen in Table 1.
Once the reciprocity data had been obtained training dipole locations and
directions were chosen. Training locations were chosen in a grid format with a
resolution of 5 mm × 5 mm × 5 mm. Training directions were chosen as +X,
−X, +Y , −Y , +Z, −Z, and 4 other random directions. Because dipoles could
only occur in grey matter this yielded 100,340 different input-output pairs. These
training pairs were then presented to the networks for training.
Once the networks were trained the sensor data from 10,000 dipoles with
random locations and directions were presented to the network. The average
15](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-29-2048.jpg)
![Figure 6: FMRI Image Used for Realistic Head Model (ITK-SNAP [13])
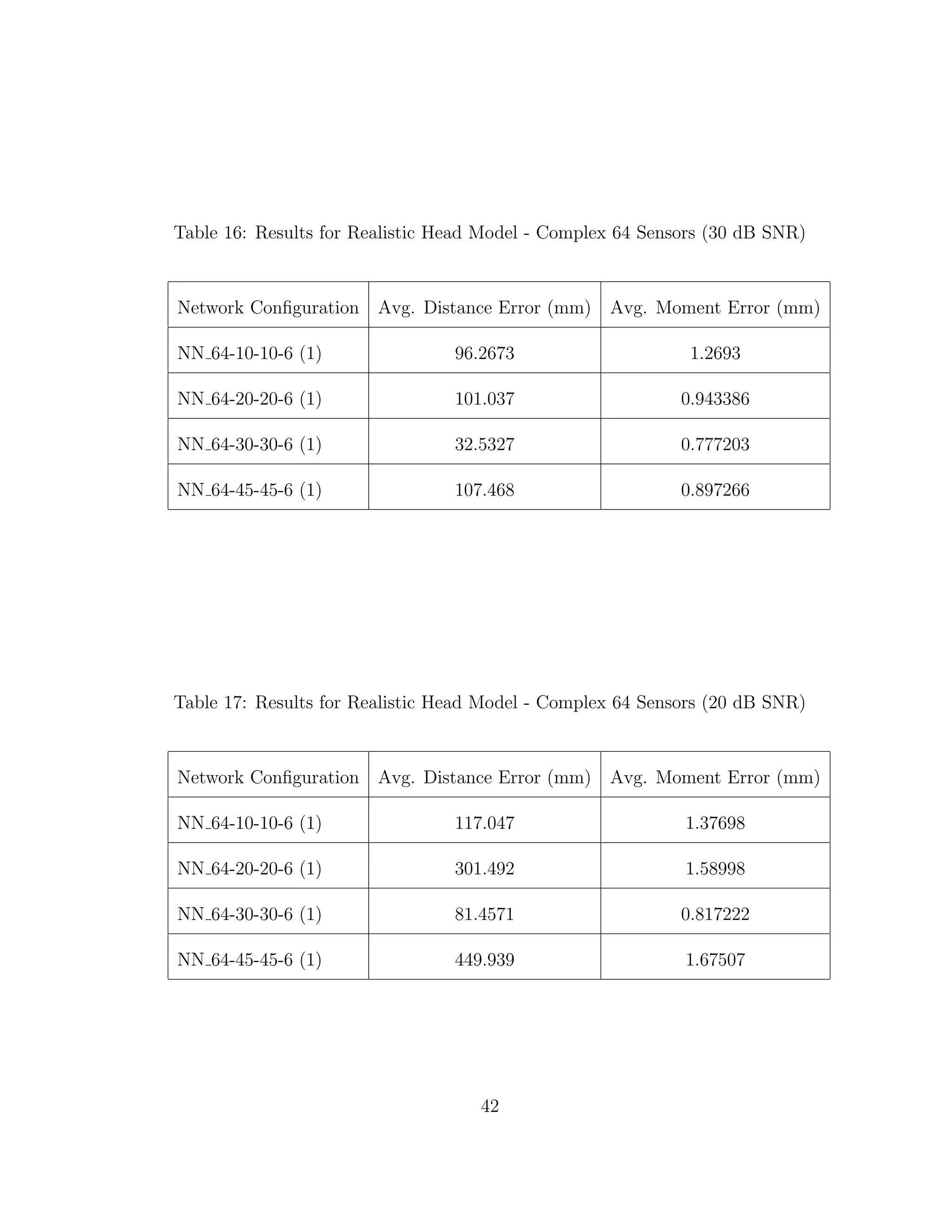
location and direction errors were recorded. Next every grey matter node where
Z = 178 was used as a dipole location with direction +Z. Layer Z = 178 was
chosen because it is a thick area of the brain near the center of mass. The average
location and direction errors are recorded. Noise is then introduced such that
SNR = 10 dB, 20 dB, and 30 dB. The same tests are performed again for any
voxels within 55 mm of the centroid of the layer. This is done, because it has
been noted that neural networks tend to have larger errors when source locating
near the boundary of the training area and would have better average accuracy
near the centroid of the training area [10].
16](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-30-2048.jpg)






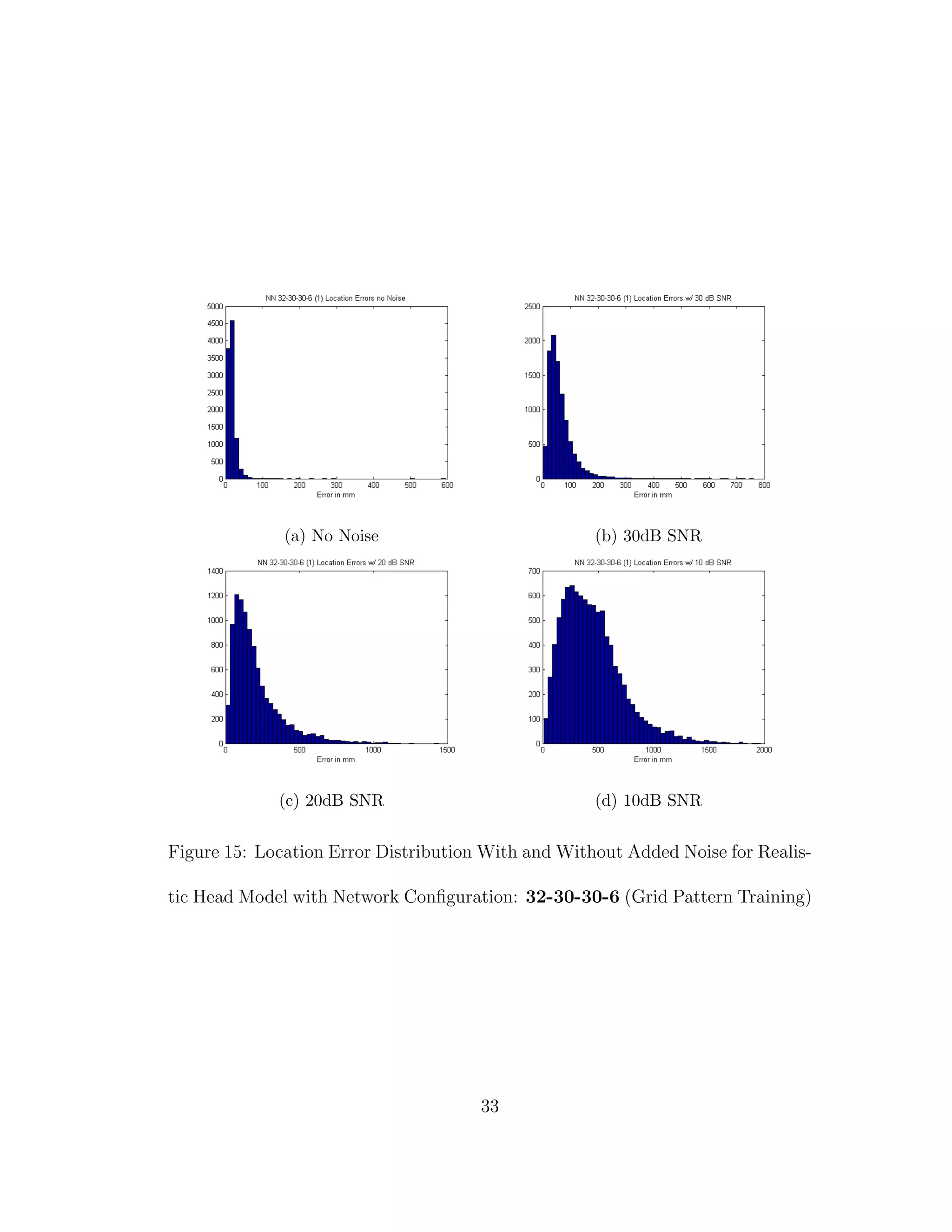

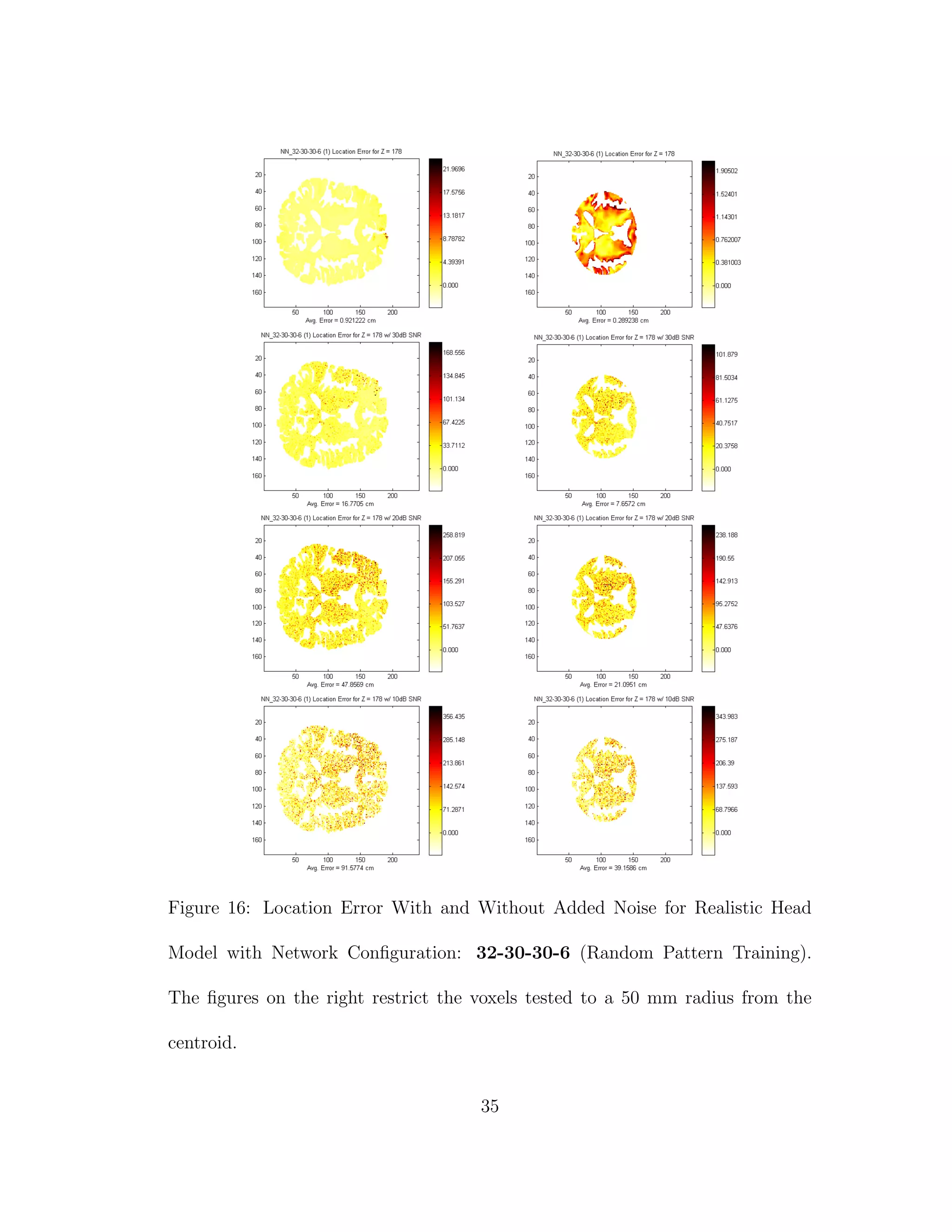
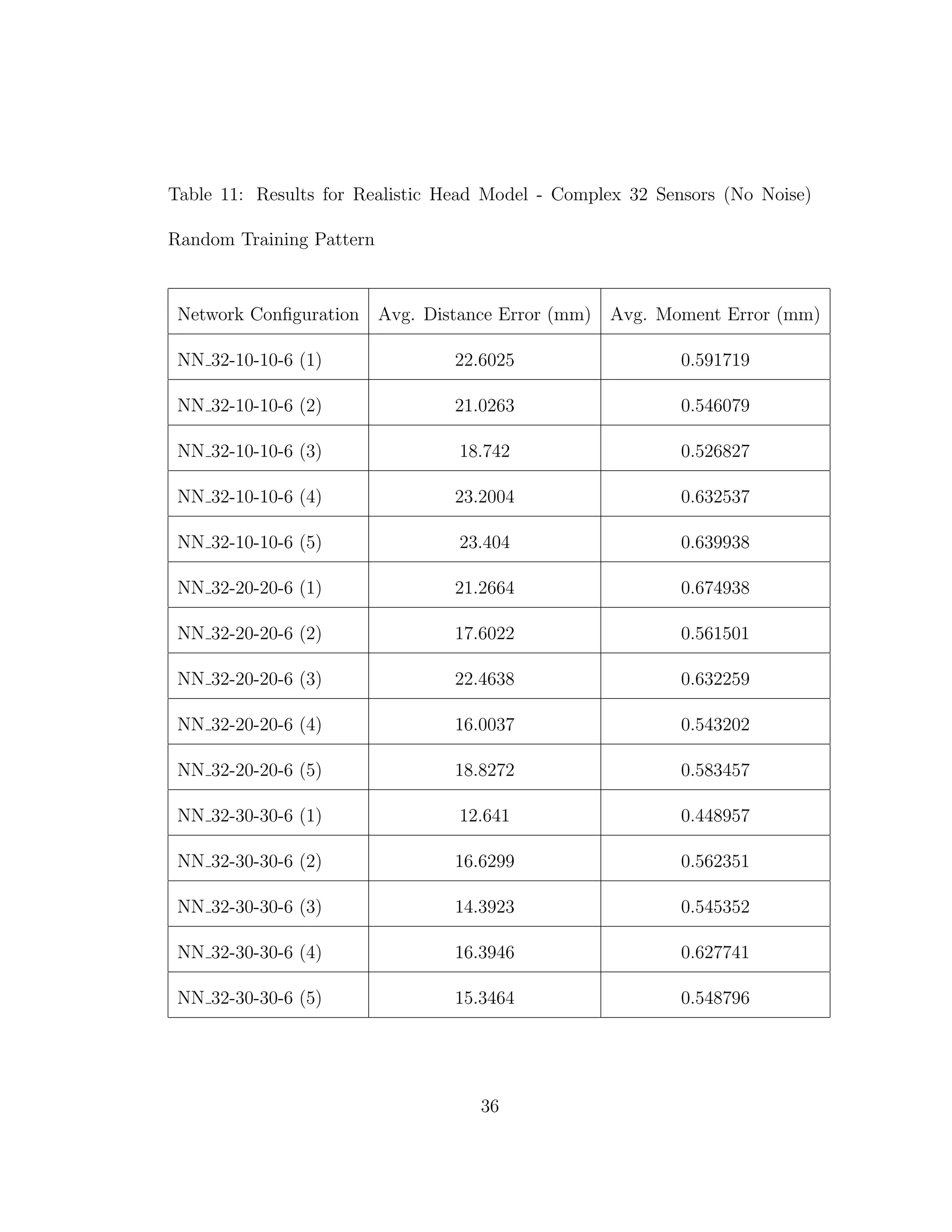
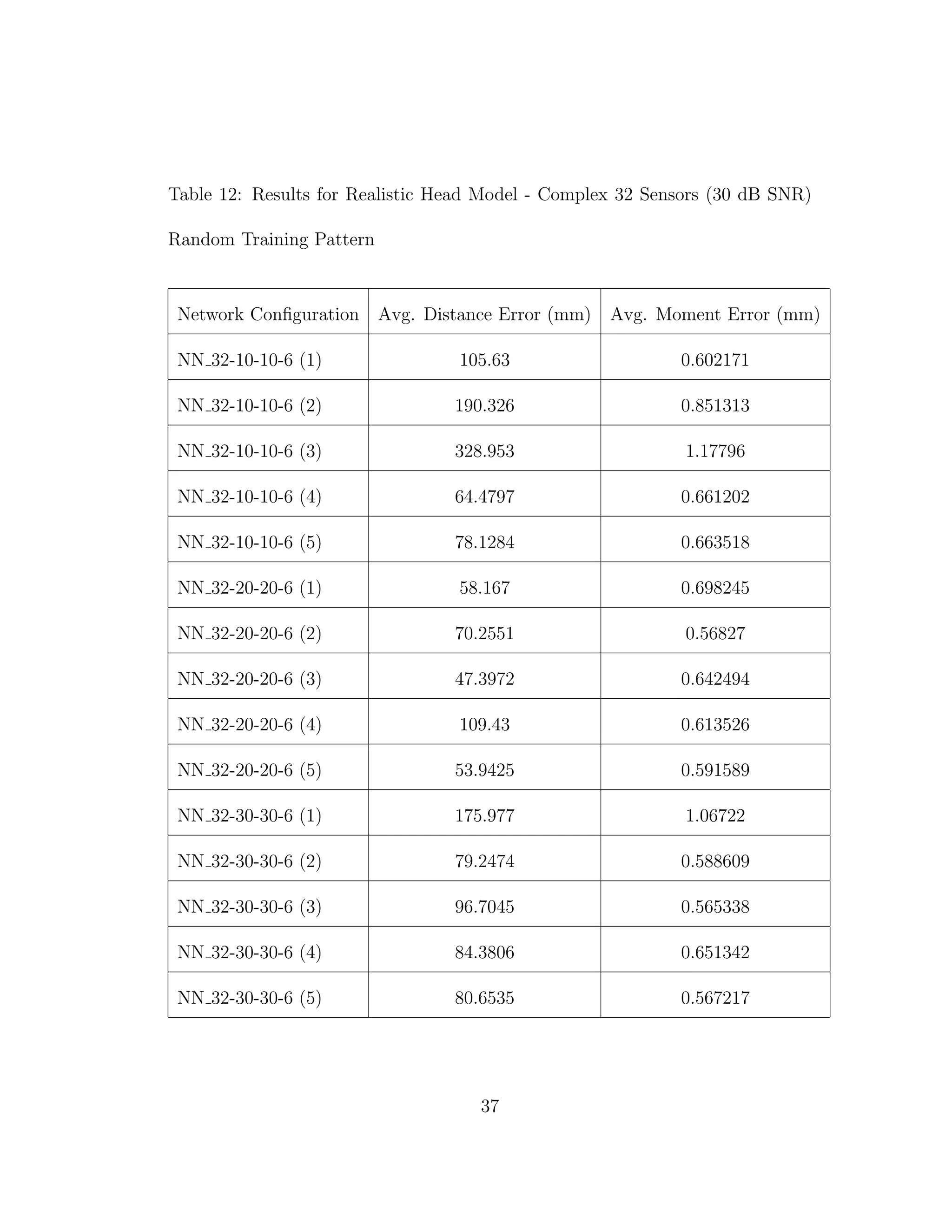
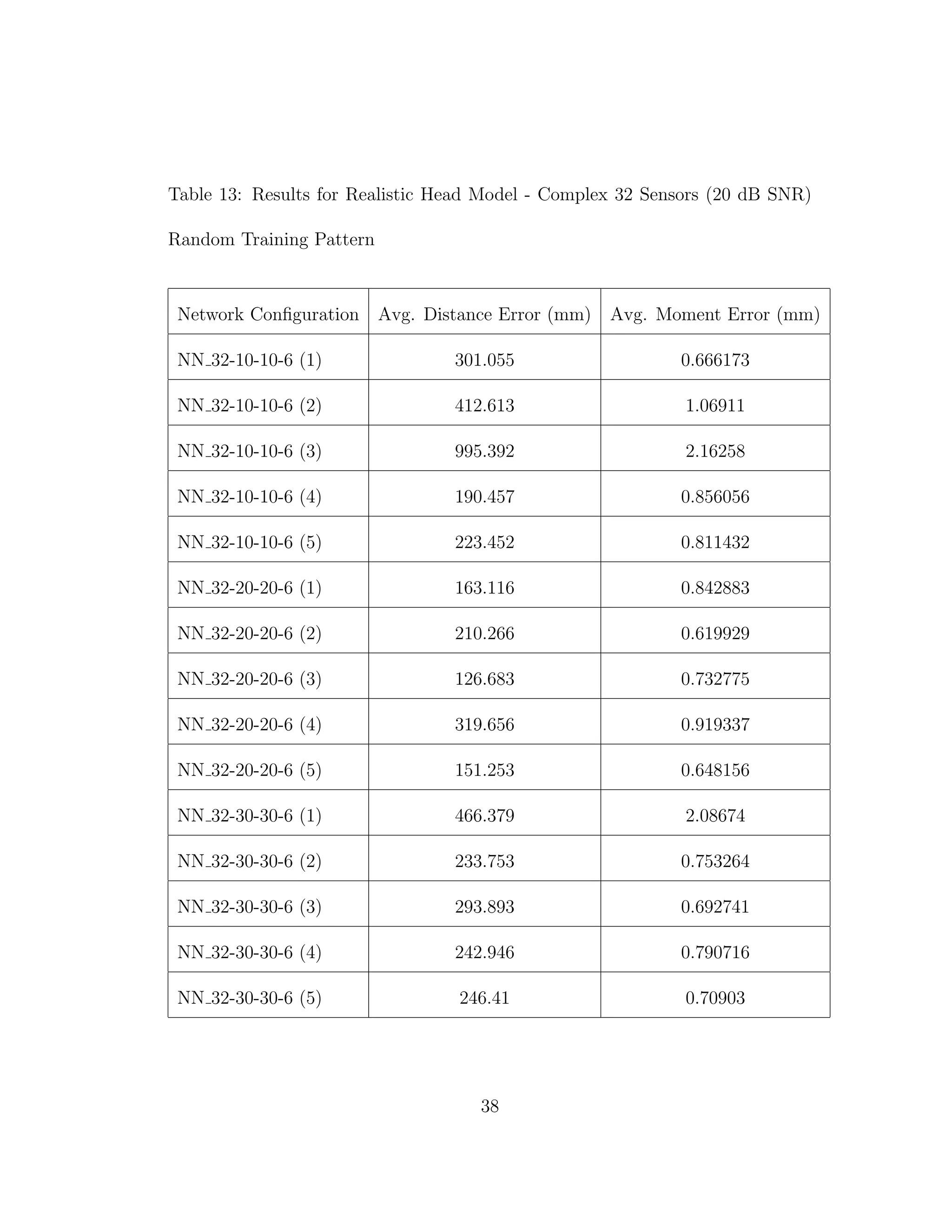
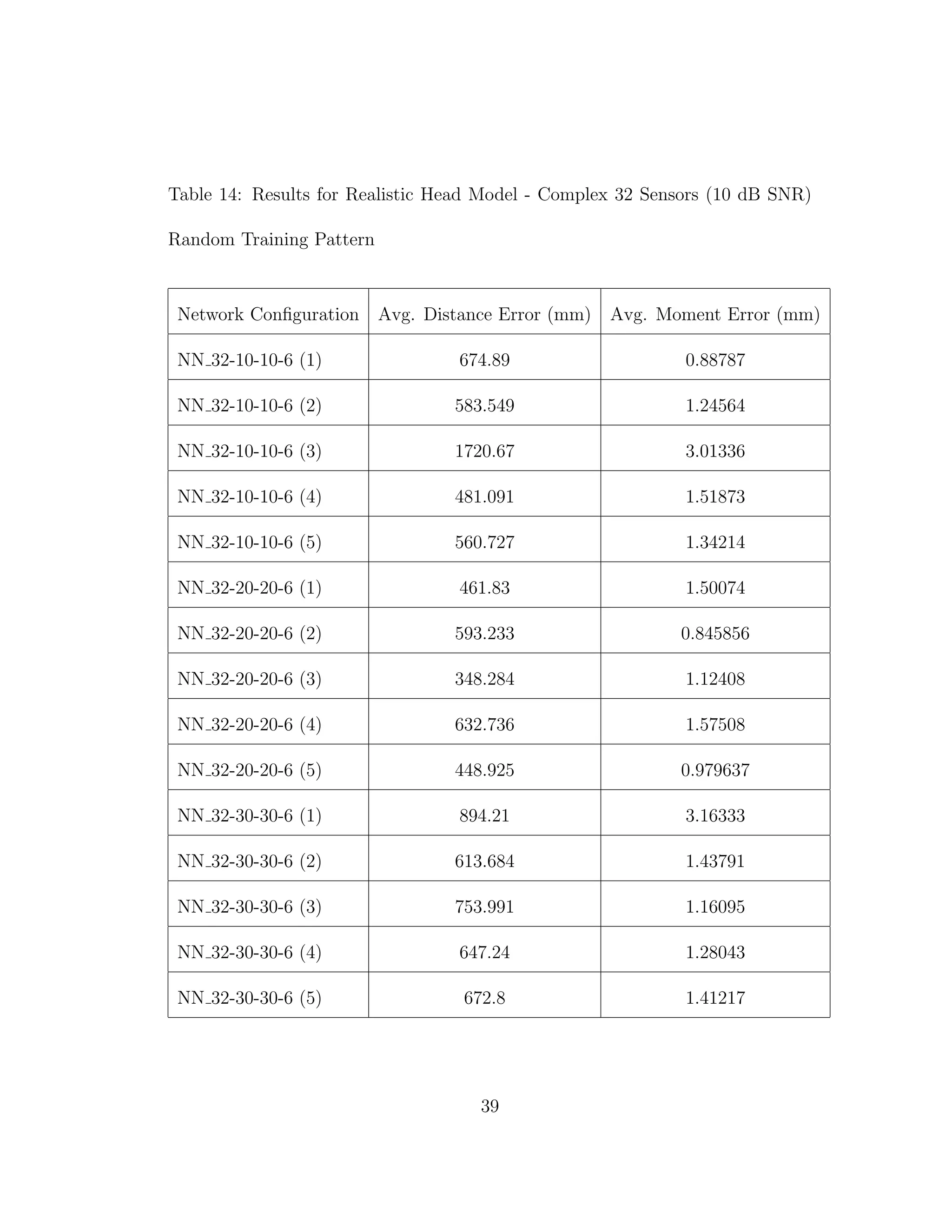
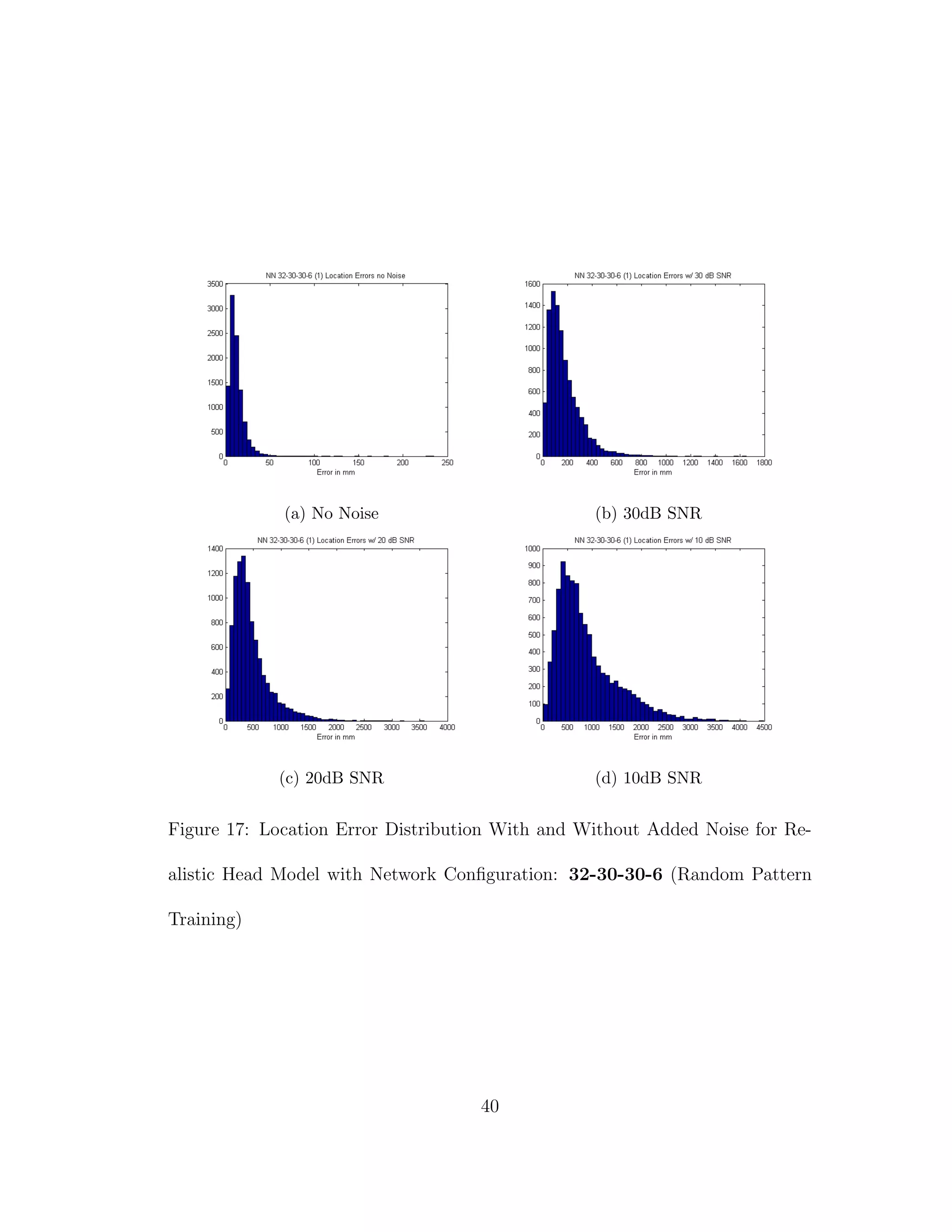
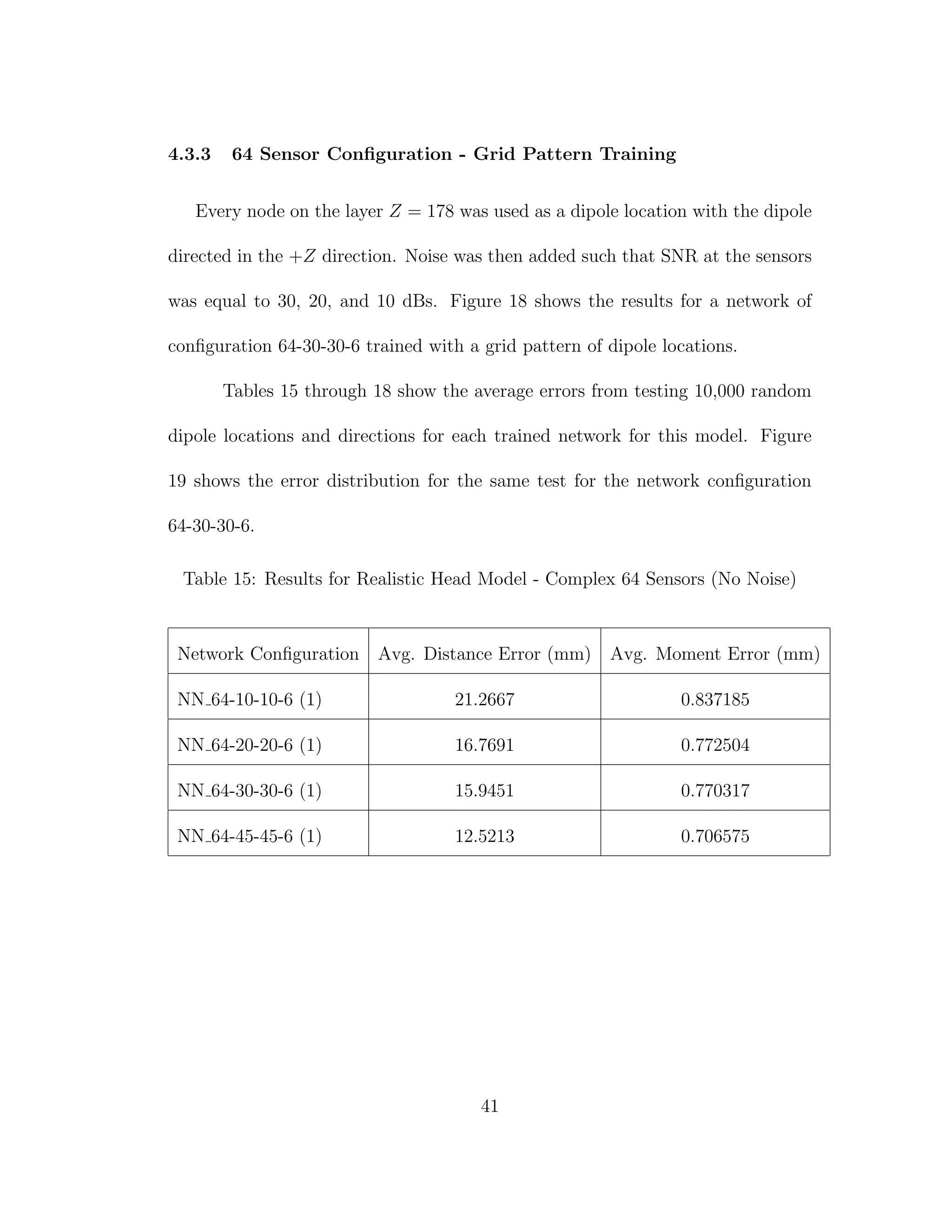

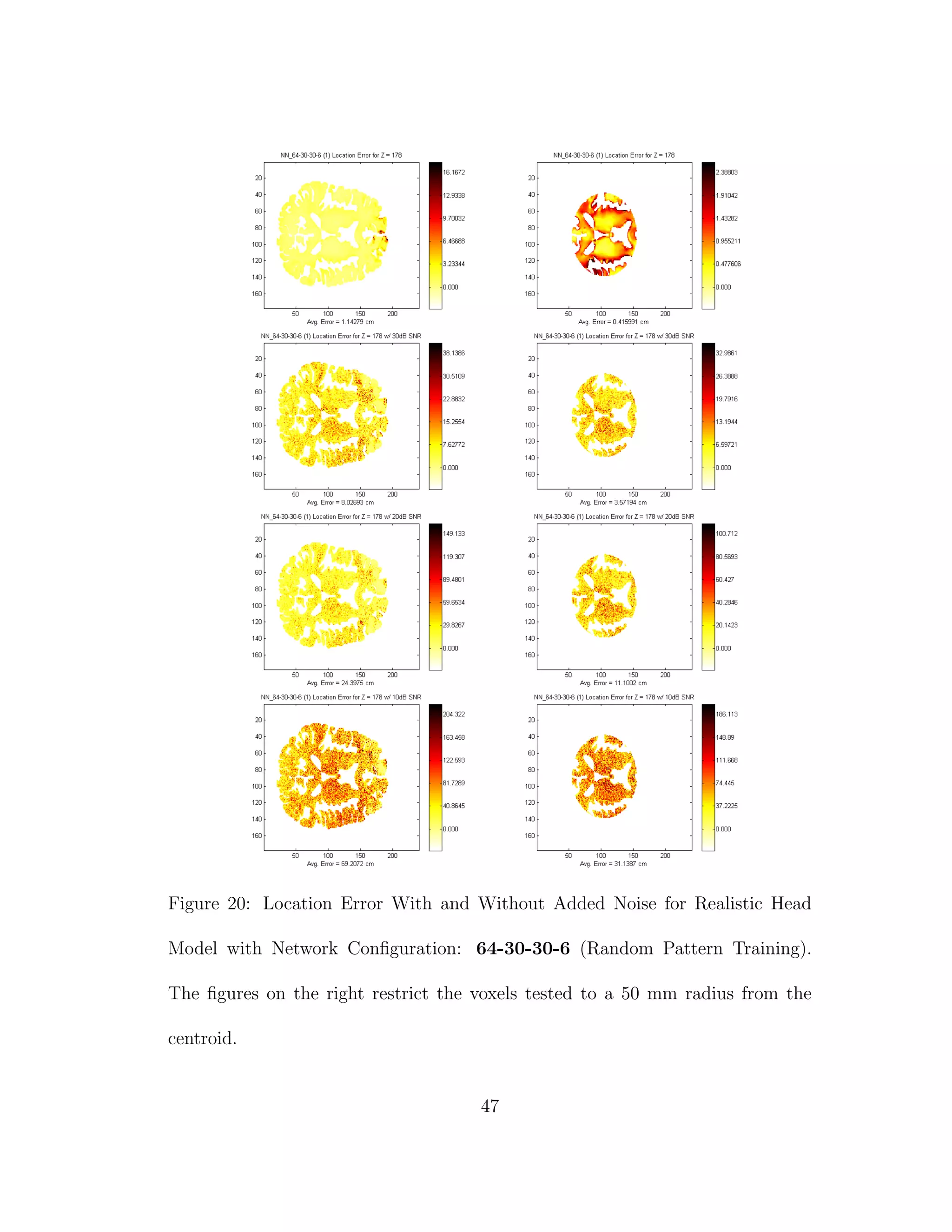
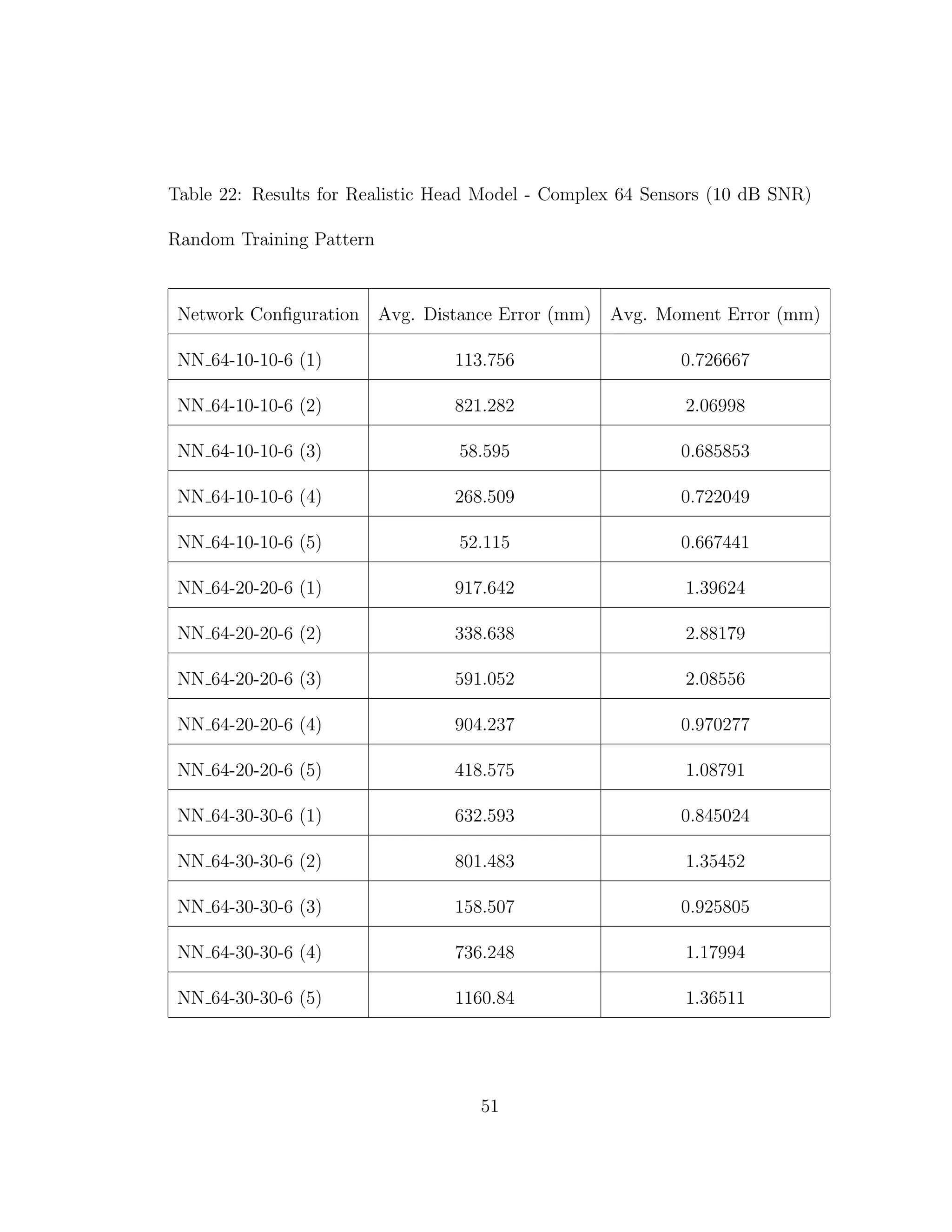
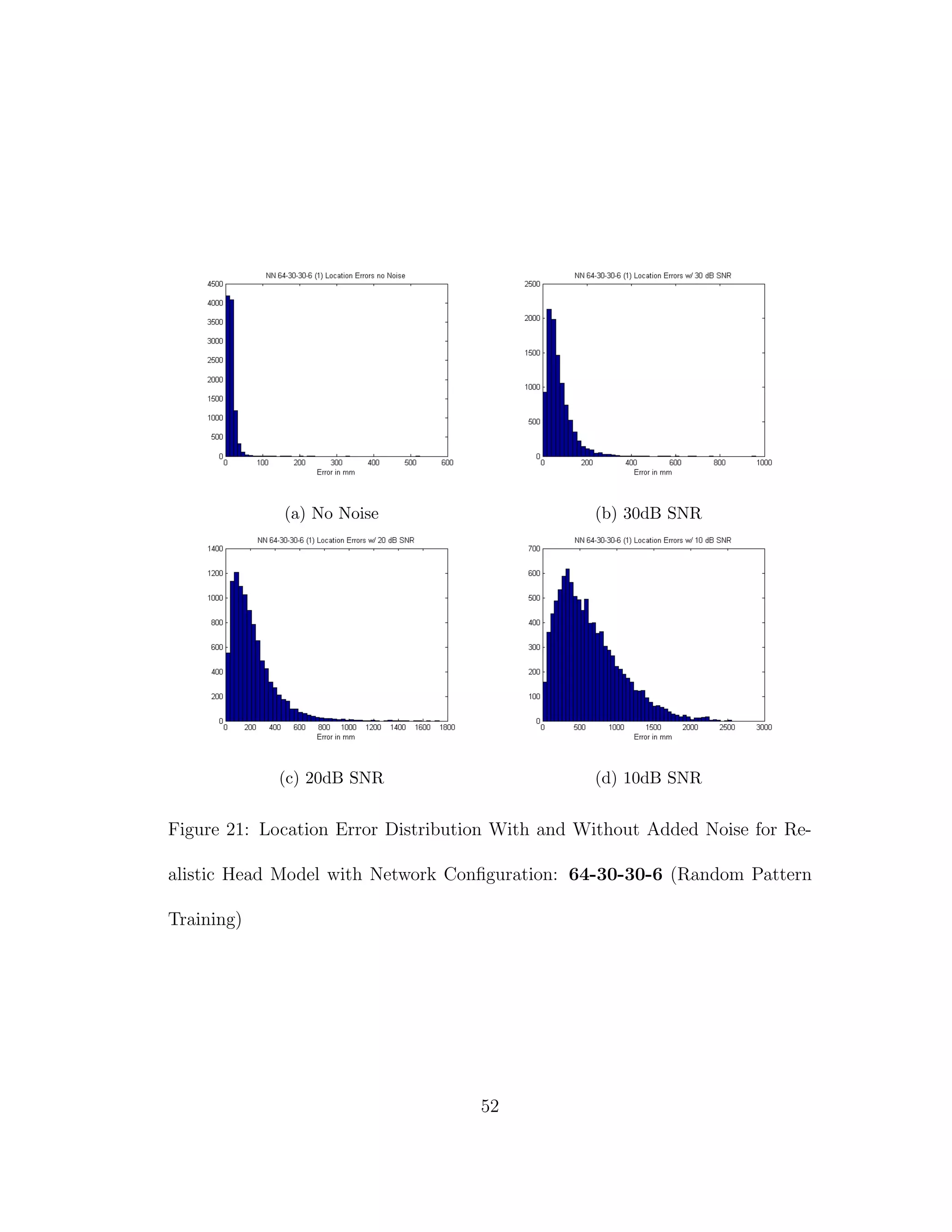

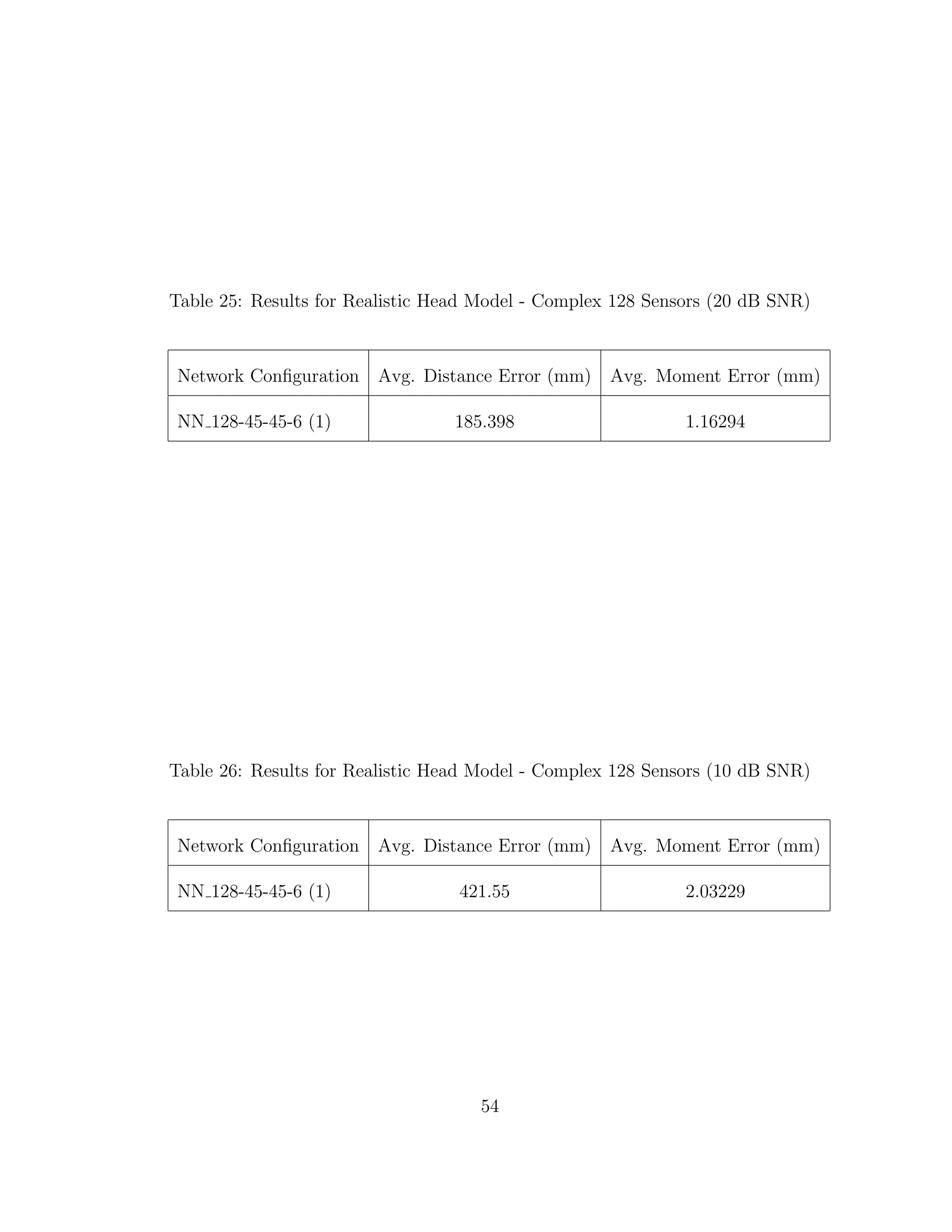

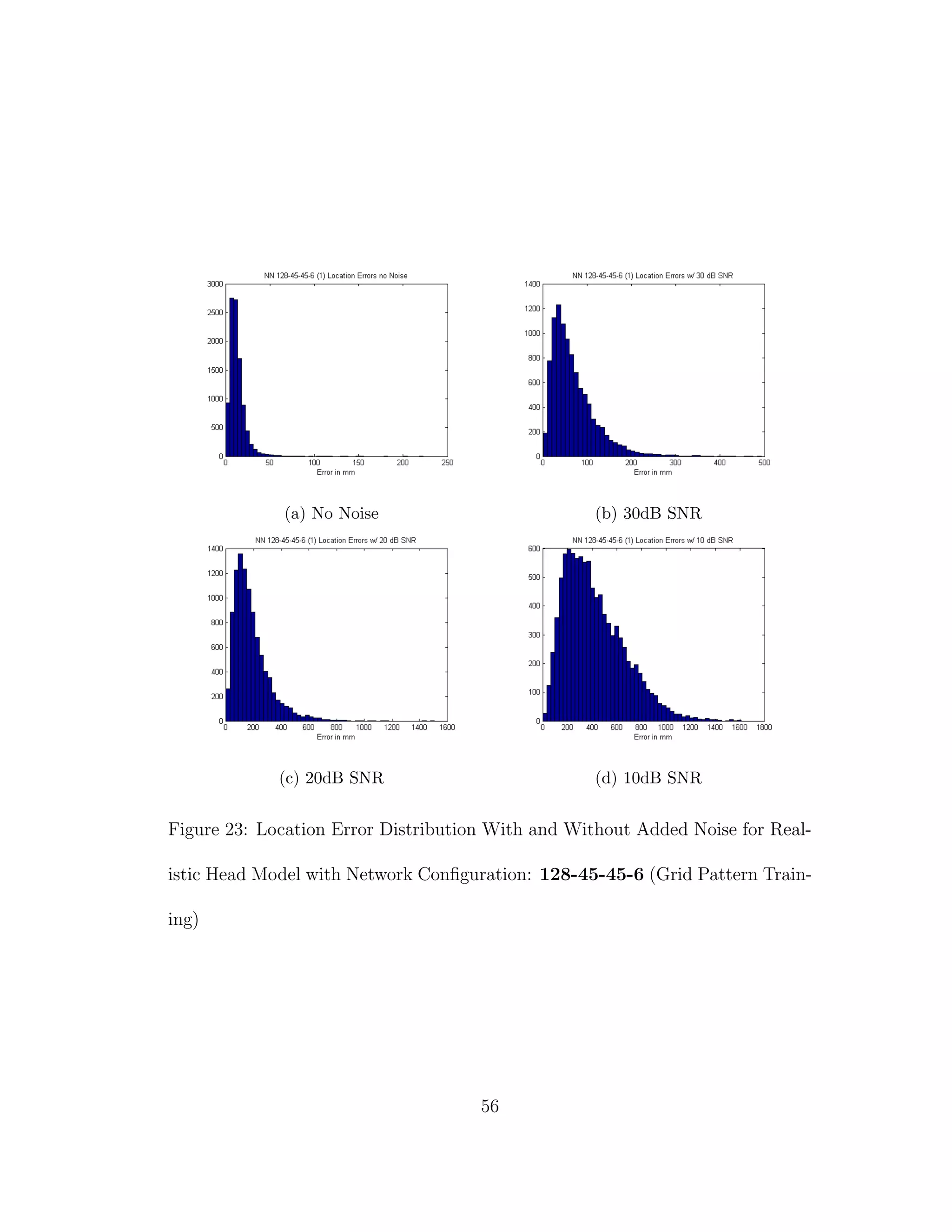

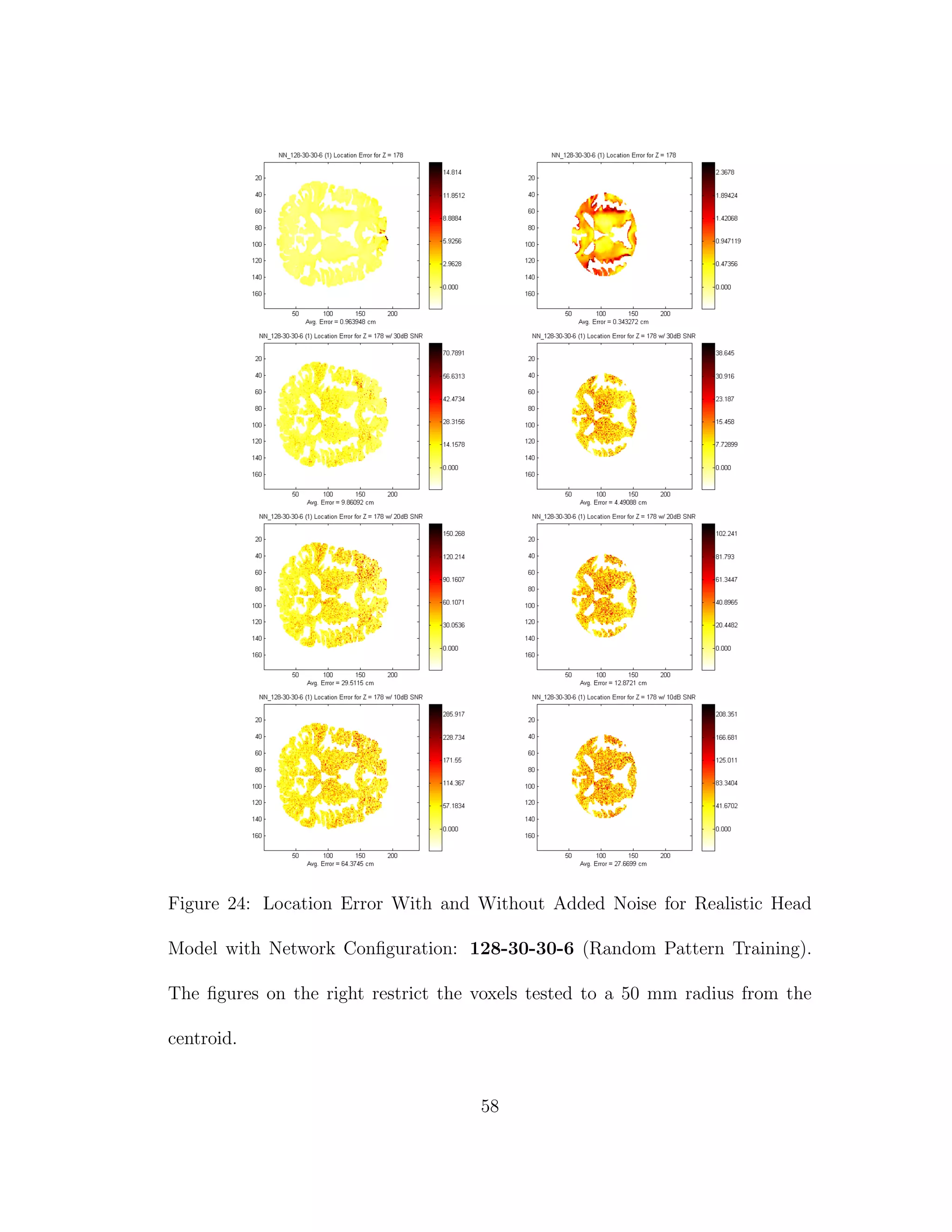
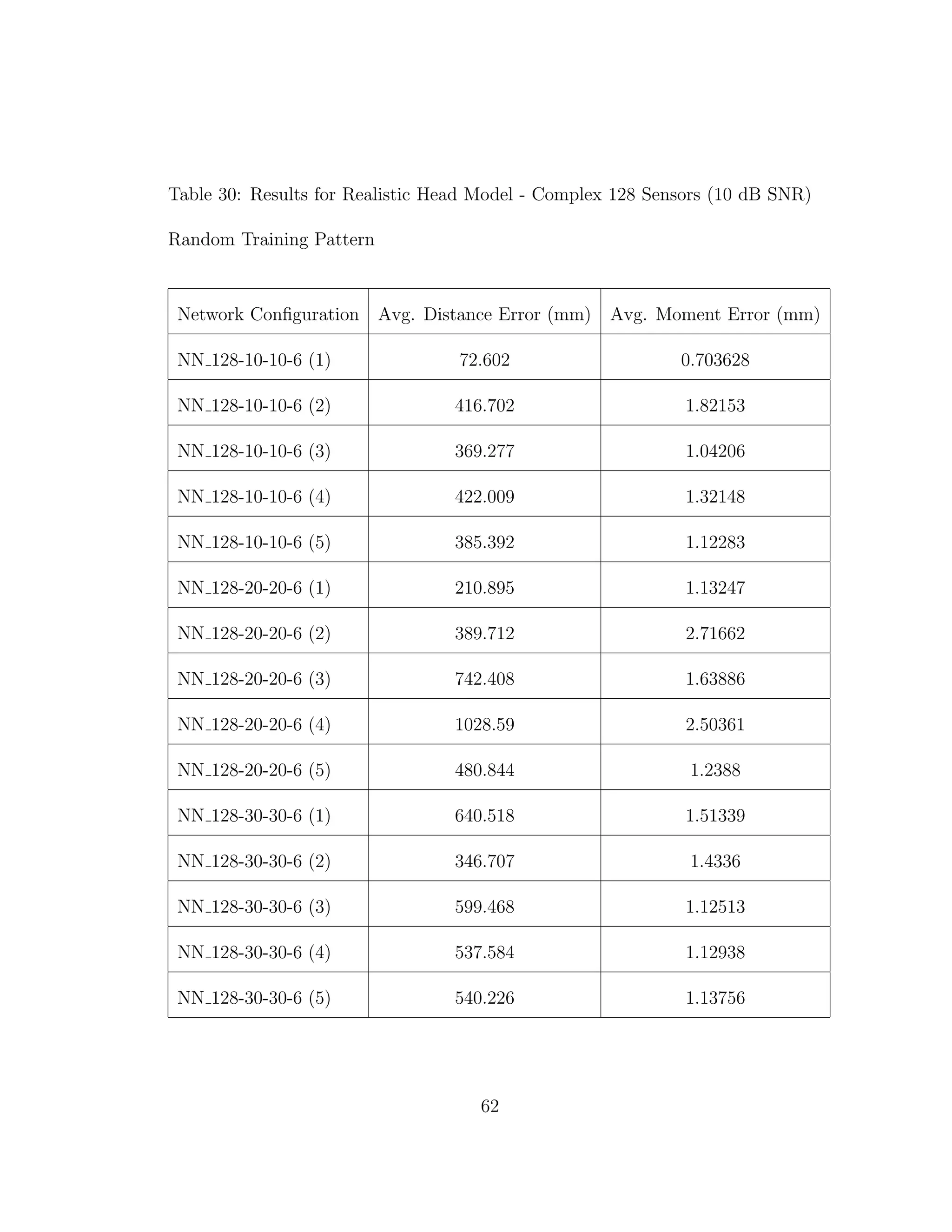
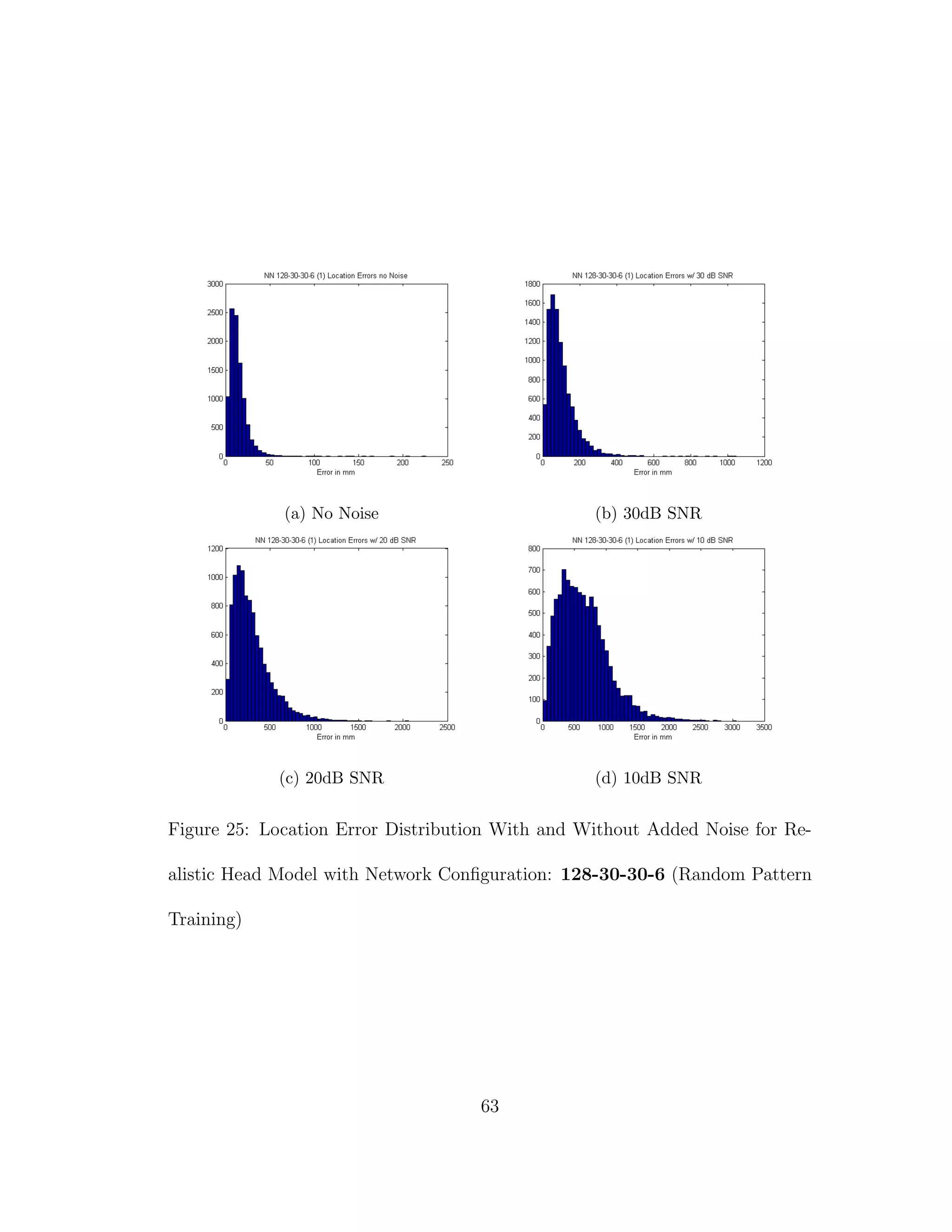
![5 DISCUSSION
To this researcher’s knowledge source localization using this high fidelity of a
head model has not been tried before. Realistic head shapes with realistic sensor
locations have been modelled and tested [10], however the resolution was not as
high as 1 mm × 1 mm × 1 mm, and the recognition of different conductivities in
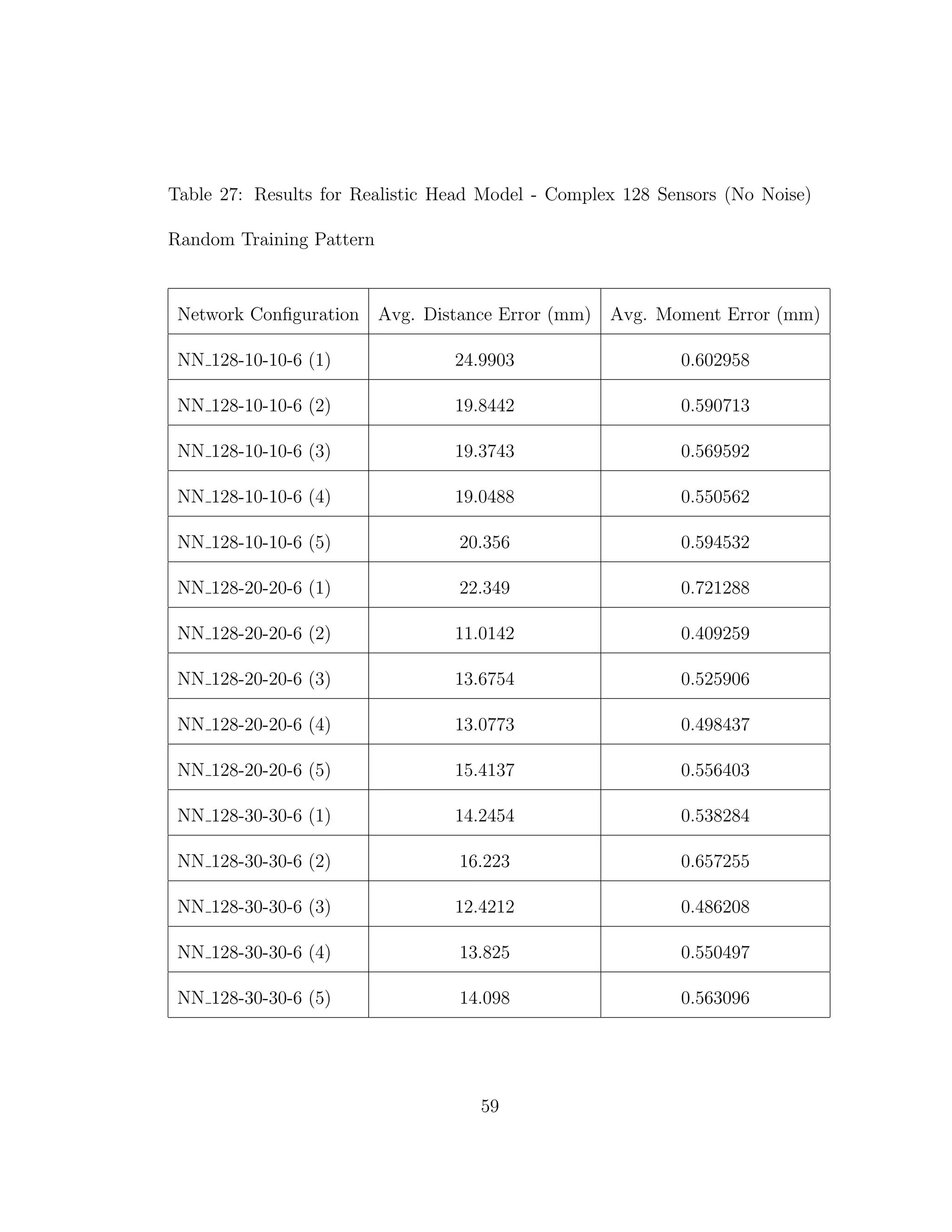
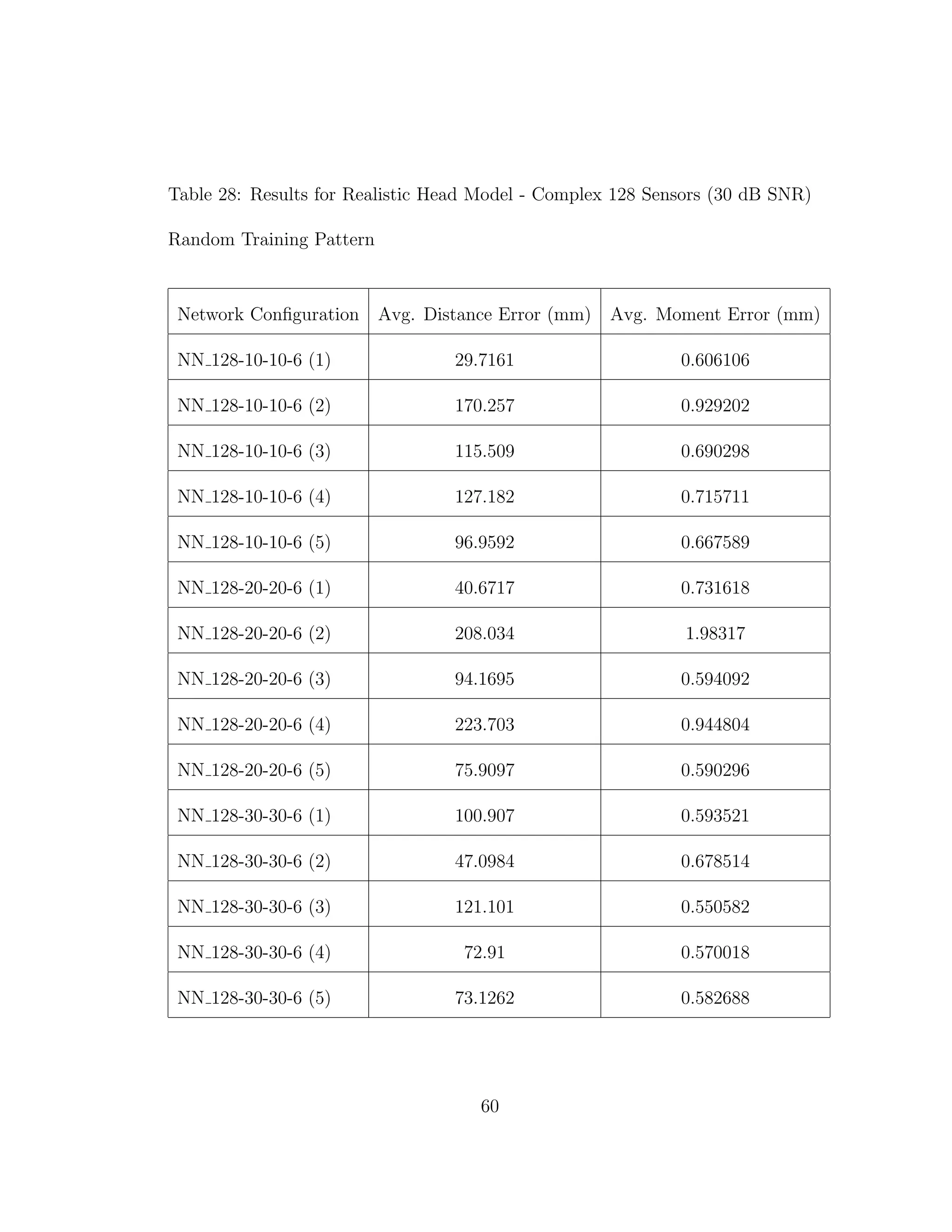
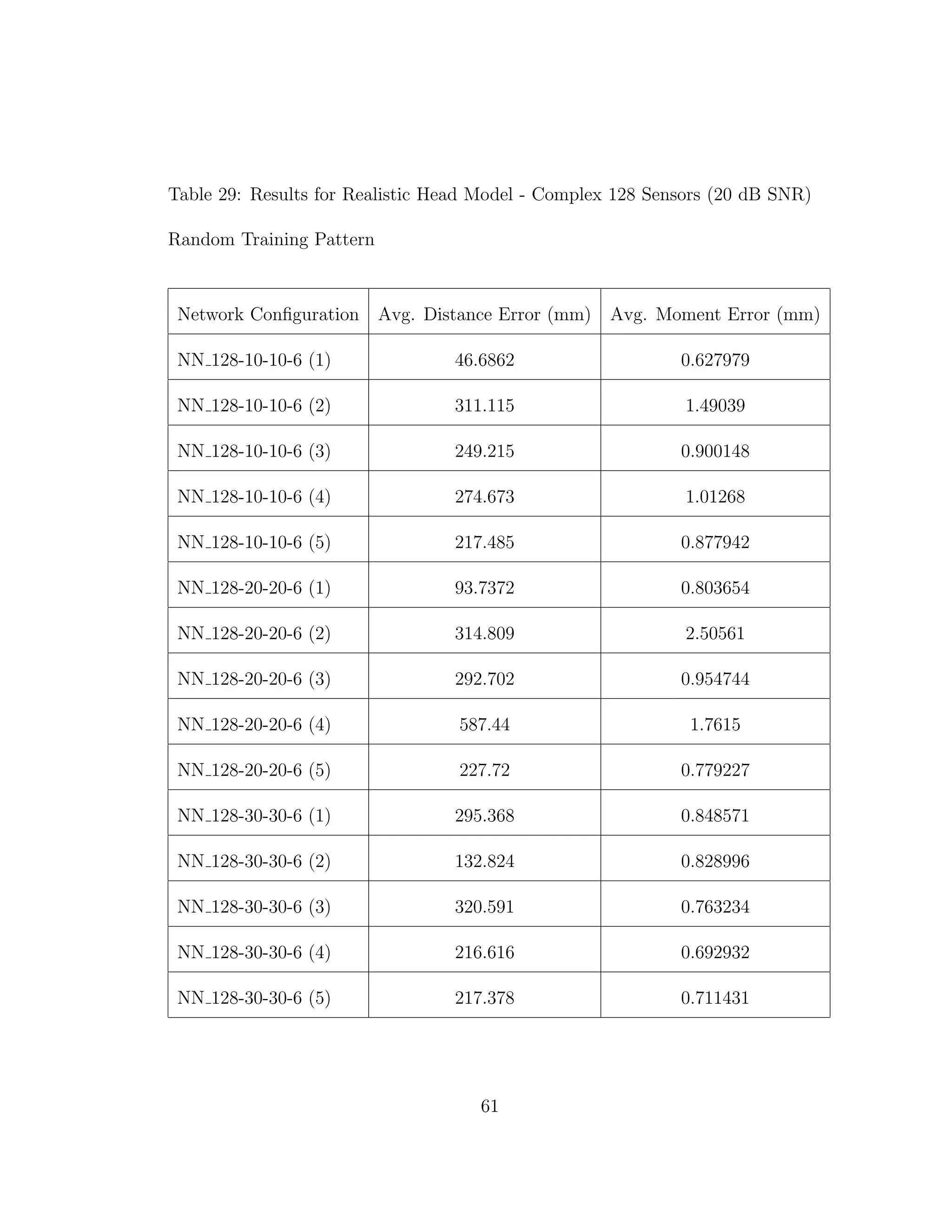
the grey and white matter tissues was not taken into account. In fact the results
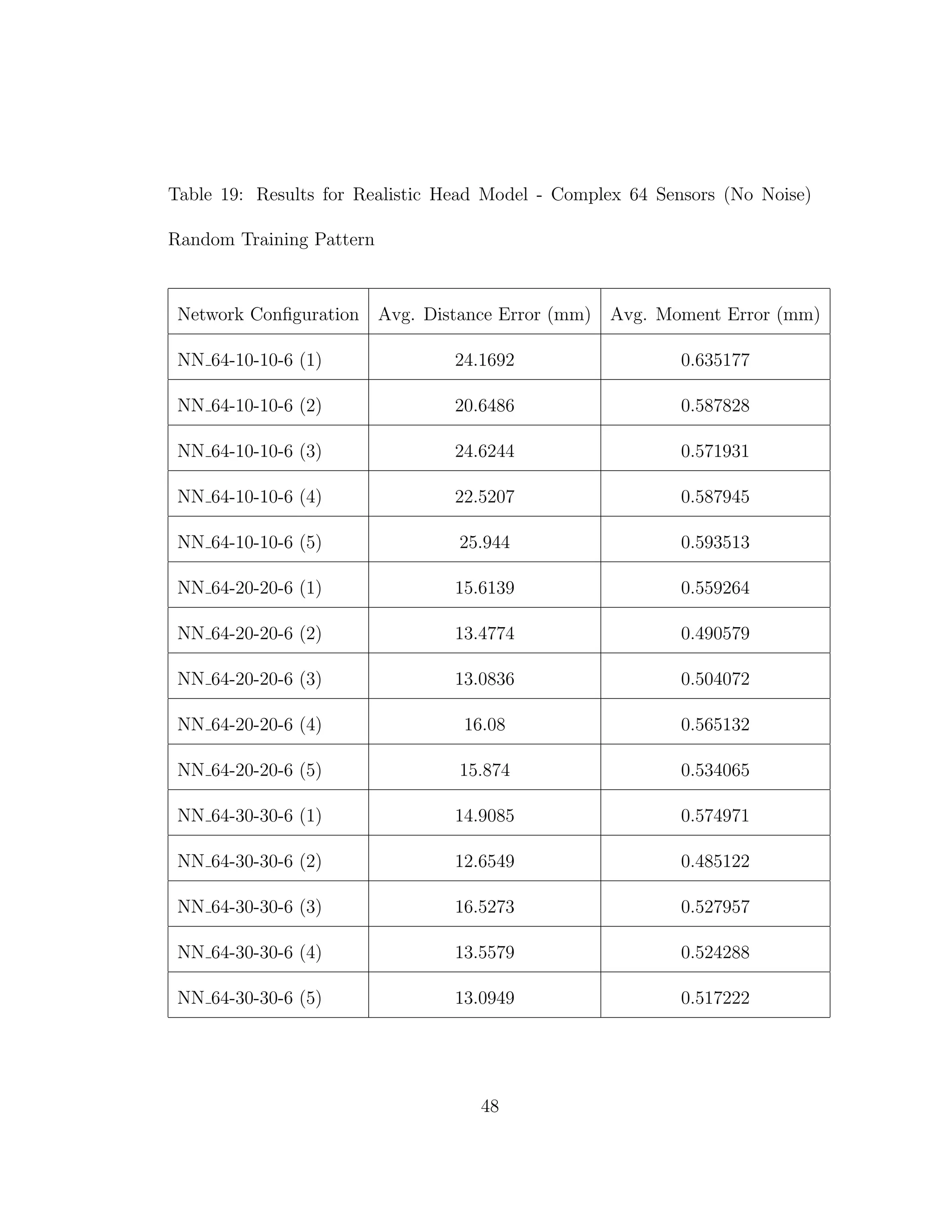
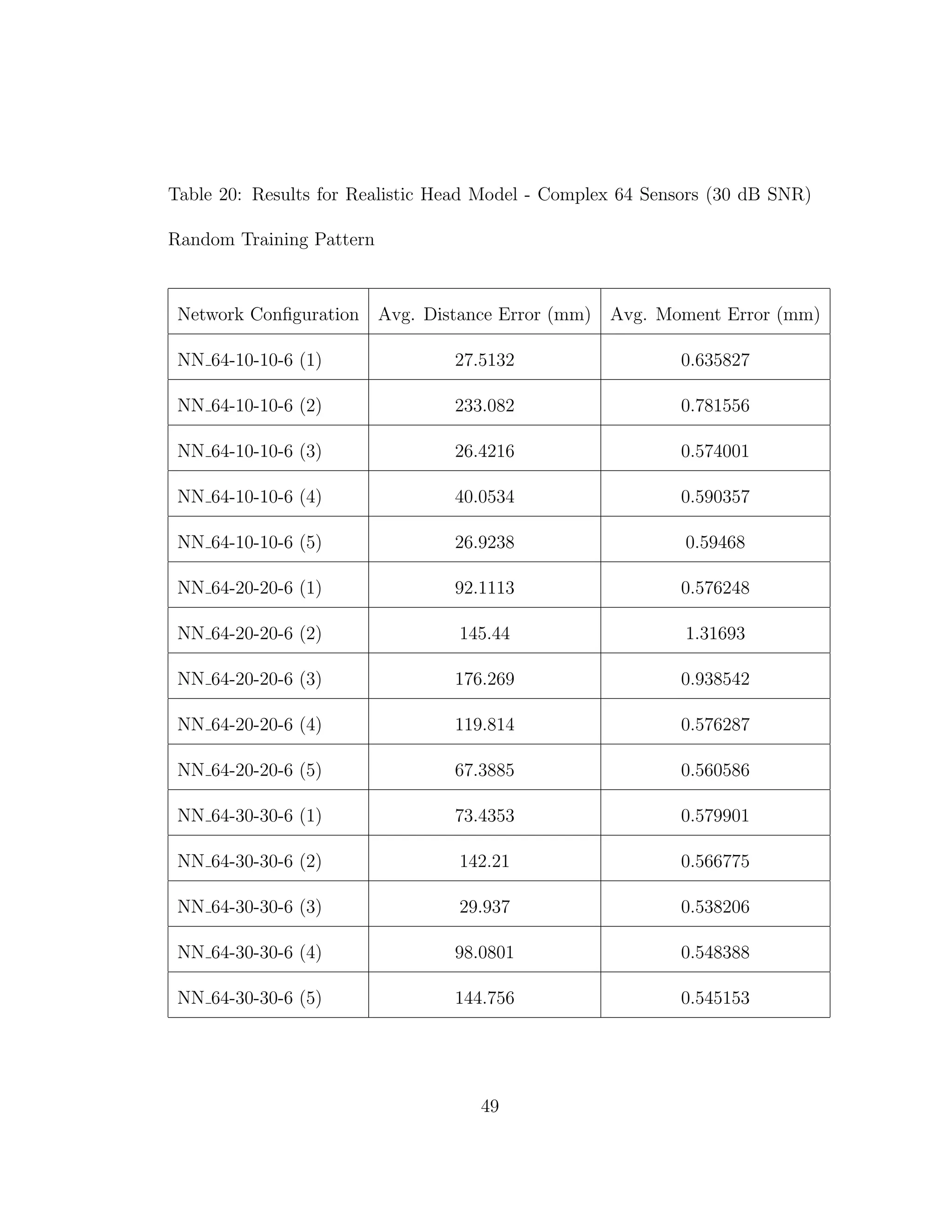
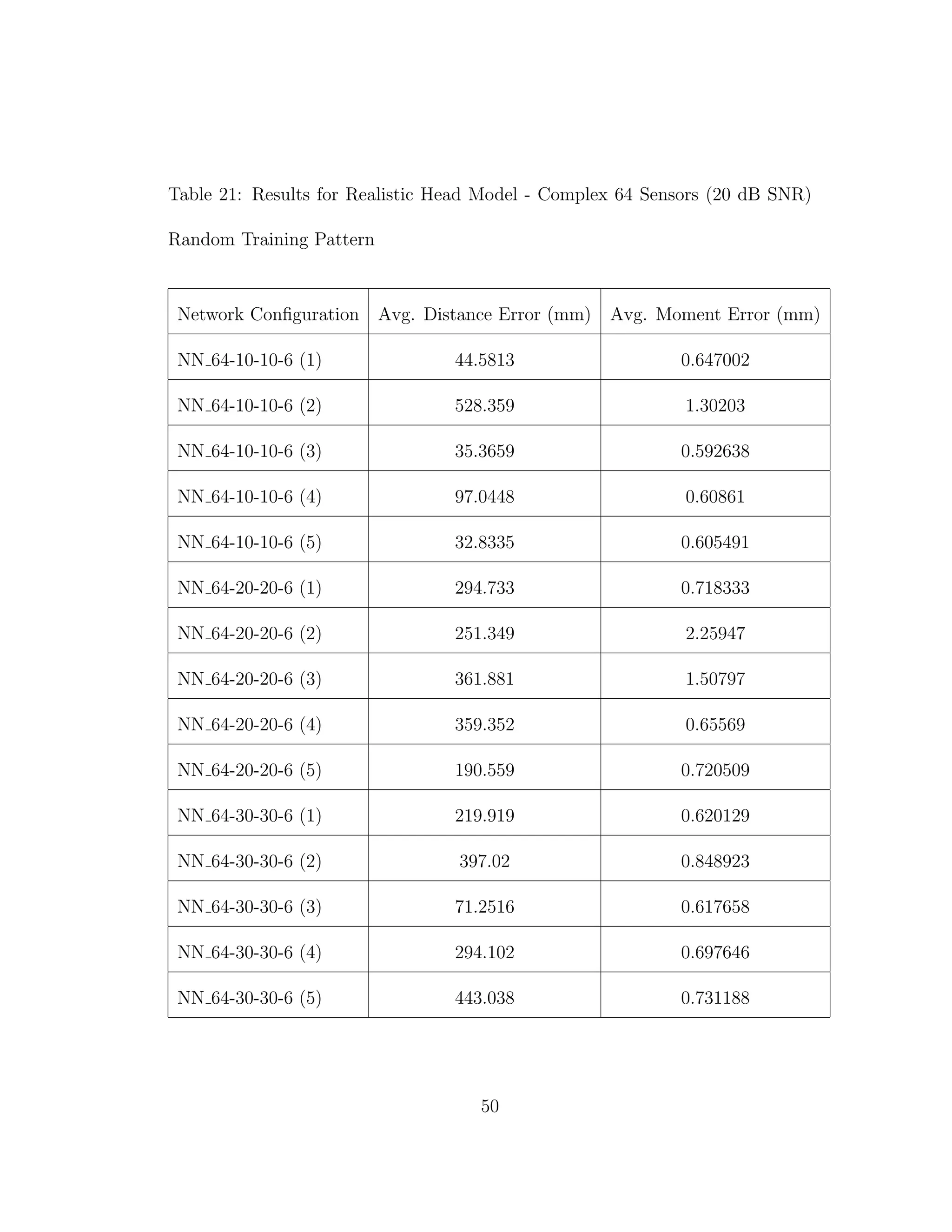
from Tables 3 through 6 confirm the results from previous experiments [10]. It is
of interest to note the differences in results when we do take into account different
conductivities in tissues.
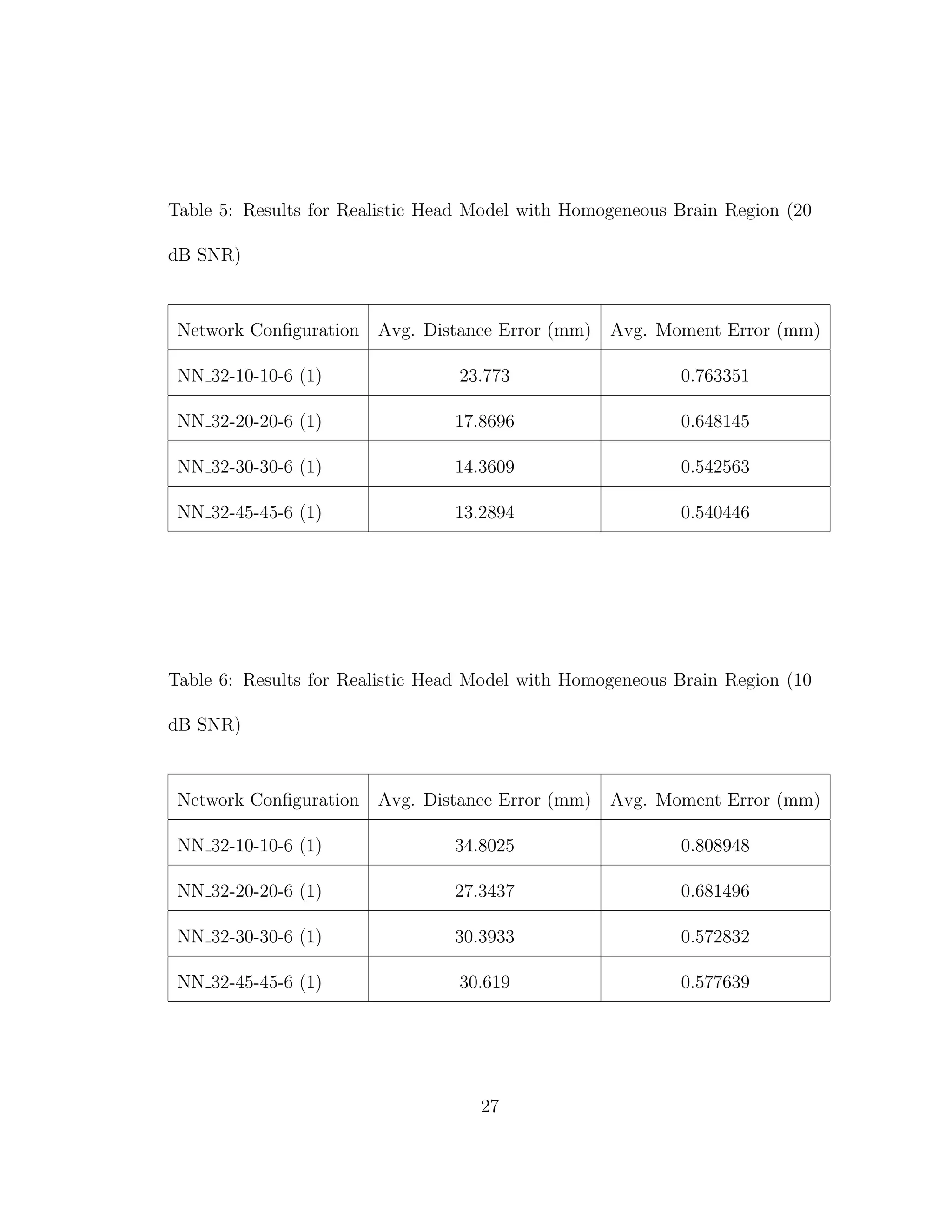
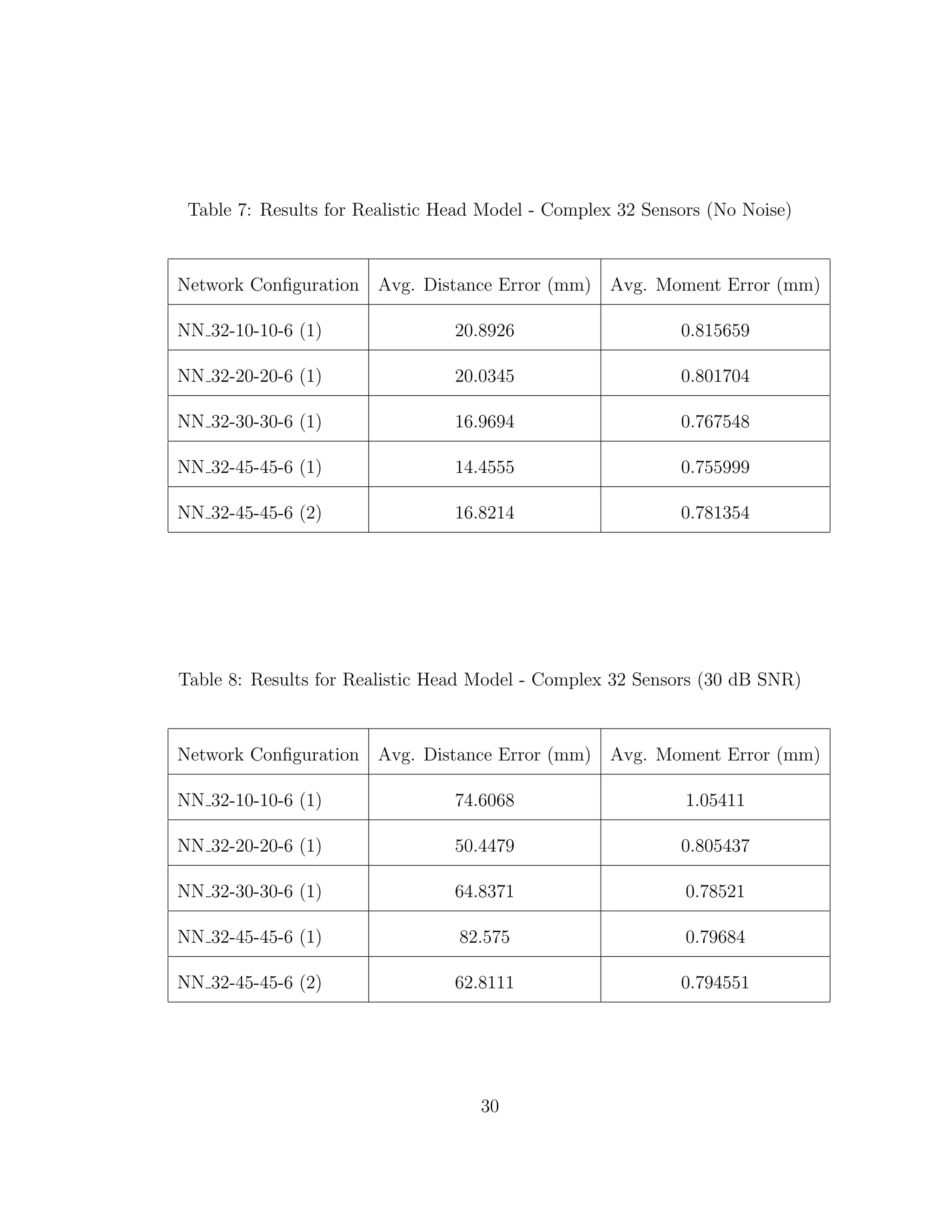
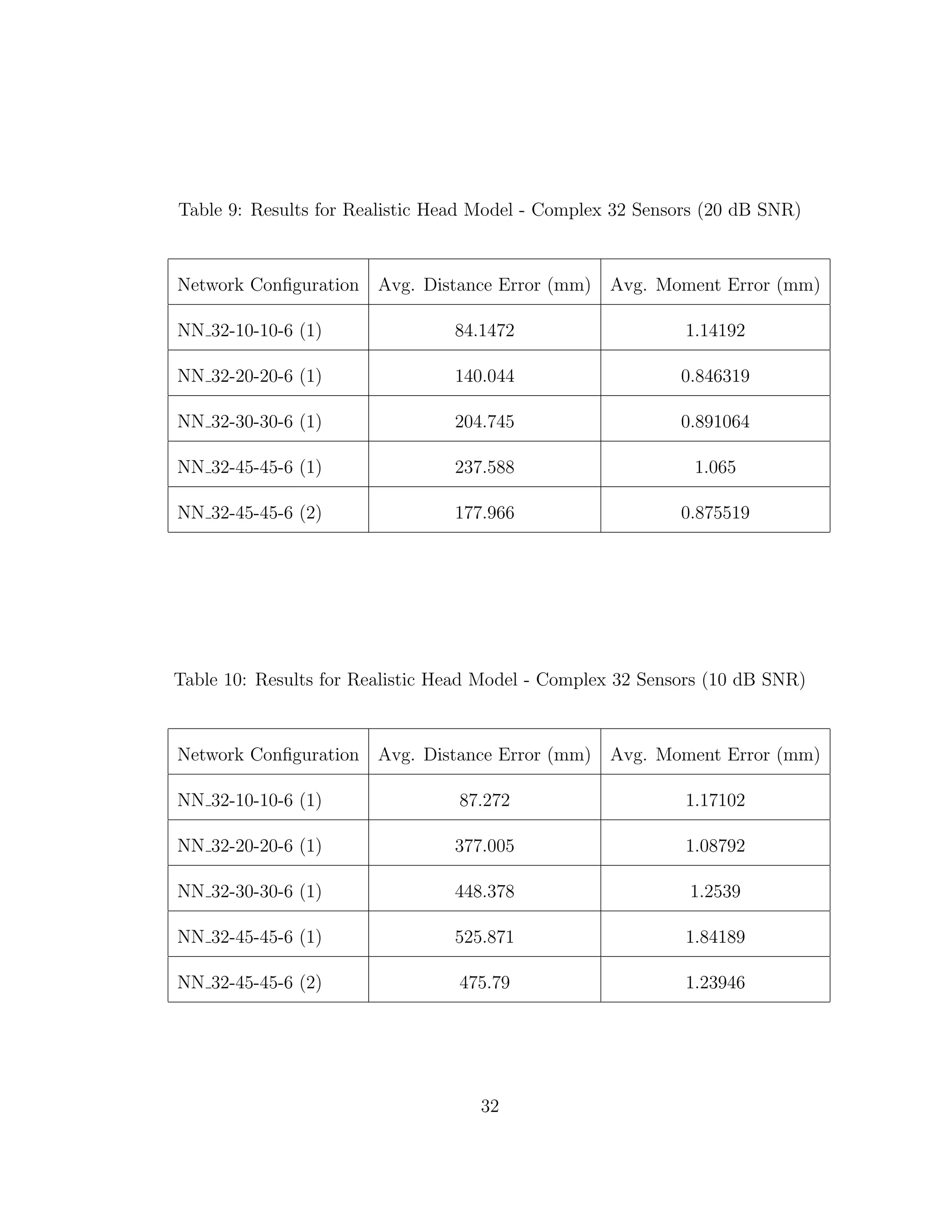
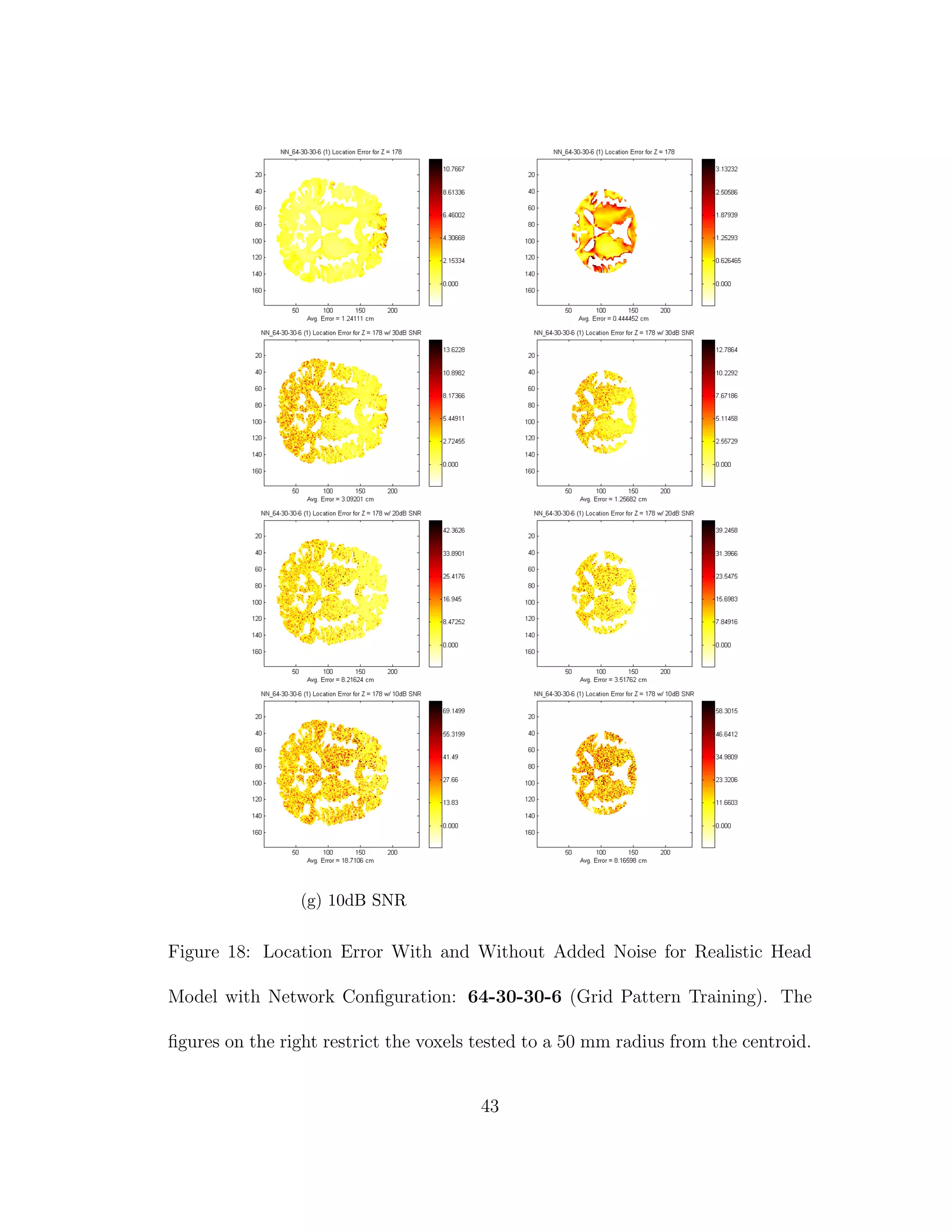
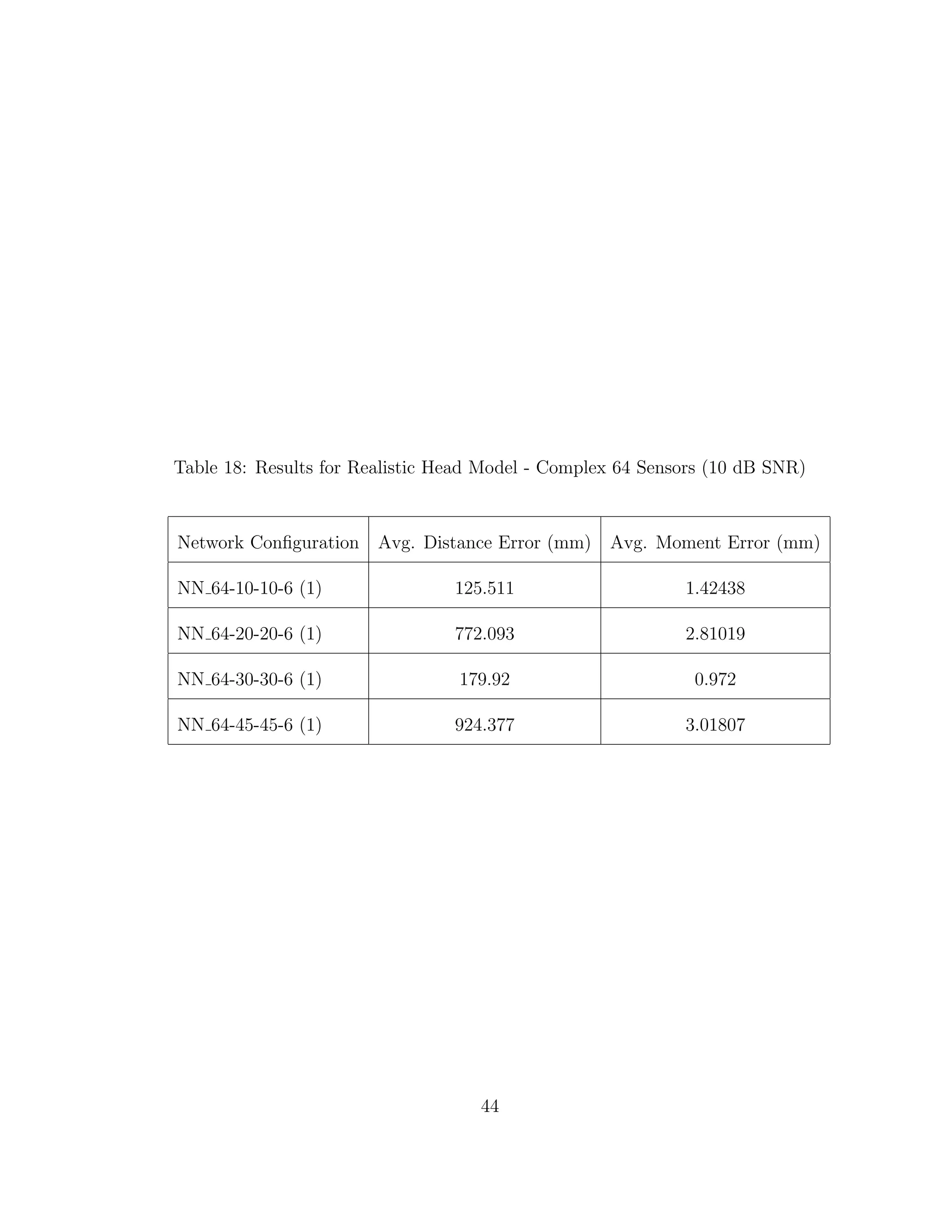
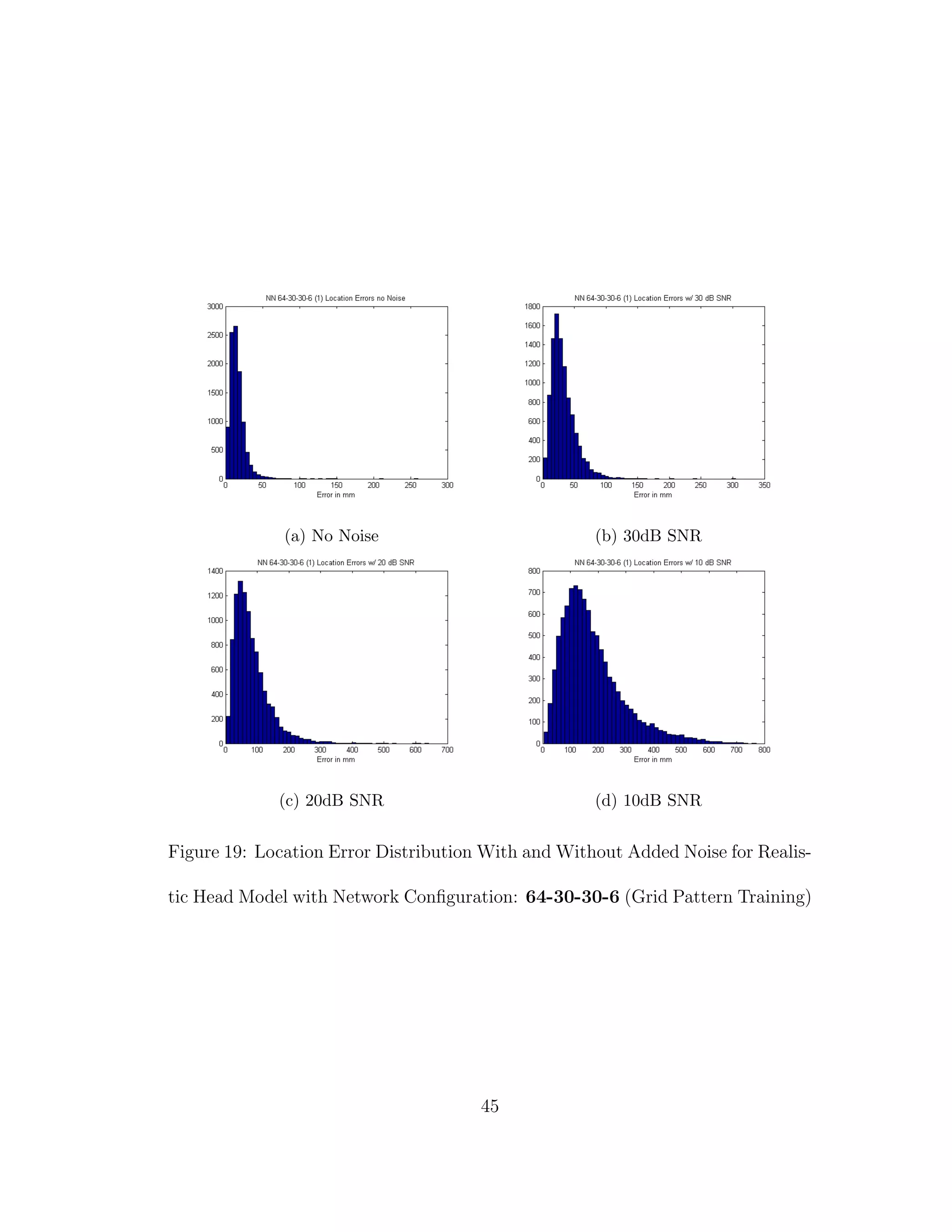
When we compare the results from Tables 3 through 6, the results from our
realistic head model with homogeneous brain area, to Tables 7 through 30, the
results from our more complex realistic head model, we can see a common theme.
For the homogeneous model when we add noise such that the SNR is equal to
30 dB, we only see a jump in average location error of at most 1 mm. This is
completely different in the more complex head model. When we add the same
amount of noise we see jumps in average location error of several centimeters, and
this only gets worse as we add more noise.
Why is this happening? I believe that the reason that a neural network can
source localize a homogeneous head model so well is because of the almost linear
relationship between the dipole and what gets picked up by the sensors on the
64](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-78-2048.jpg)





![REFERENCES
[1] Abeyratne, Udantha R., Yohsuke Kinouchi, Hideo Oki, Jun Okada, Fumio
Shichijo, and Keizo Matsumoto. ”Artificial Neural Networks for Source Lo-
calization in the Human Brain.” Brain Topography 4.1 (1991): 3-21. Print.
[2] Abeyratne, Uduntha R., G. Zhang, and P. Saratchandran. ”EEG Source Lo-
calization: A Comparative Study of Classical and Neural Network Methods.”
International Journal of Neural Systems 11.4 (2001): 349-59. Print.
[3] Dang, Hung V., and Kwong T. Ng. ”Finite Difference Neuroelectric Modeling
Software.” Journal of Neuroscience Methods 198.2 (2011): 359-63. Print.
[4] Dang, Hung V. ”Performance Analysis of Adaptive EEG Beamformers.” Diss.
New Mexico State University, 2007. Print.
[5] Hagan, Martin T., Howard B. Demuth, and Mark H. Beale. Neural Network
Design. Boulder, CO: Distributed by Campus Pub. Service, University of
Colorado Bookstore, 2002. Print.
[6] Jenkinson, M., CF Beckmann, TE Behrens, MW Woolrich, and SM Smith.
”FSL.” NeuroImage 62 (2012): 782-90. Print.
[7] Kamijo, Ken’ichi, Tomoharu Kiyuna, Yoko Takaki, Akihisa Kenmochi, Tet-
suji Tanigawa, and Toshimasa Yamazaki. ”Integrated Approach of an Artifi-
cial Neural Network and Numerical Analysis to Multiple Equivalent Current
Dipole Source Localization.” Frontiers of Medical & Biological Engineering
10.4 (2001): 285-301. Print.
[8] Lau, Clifford. Neural Networks: Theoretical Foundations and Analysis. New
York: IEEE, 1992. Print.
[9] Steinberg, Ben Zion, Mark J. Beran, Steven H. Chin, and James H. Howard,
Jr. ”A Neural Network Approach to Source Localization.” The Journal of the
Acoustical Society of America 90.4 (1991): 2081-090. Print.
[10] Van Hoey, Gert, Jeremy De Clercq, Bart Vanrumste, Rik Van De Walle,
Ignace Lemahieu, Michel D’Have, and Paul Boon. ”EEG Dipole Source Lo-
calization Using Artificial Neural Networks.” Physics in Medicine & Biology
45.4 (2000): 997-1011. IOPscience. Web. 22 May 2013.
[11] Vemuri, V. Rao. Artificial Neural Networks: Concepts and Control Applica-
tions. Los Alamitos, CA: IEEE Computer Society, 1992. Print.
70](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-84-2048.jpg)
![[12] Yuasa, Motohiro, Qinyu Zhang, Hirofumi Nagashino, and Yohsuke Kinouchi.
”EEG Source Localization for Two Dipoles by Neural Networks.” Proceedings
of the 20th Annual International Conference of the IEEE Engineering in
Medicine and Biology Society 20.4 (1998): 2190-192. Print.
[13] Yushkevich, Paul A., Joseph Piven, Heather Cody Hazlett, Rachel Gimpel
Smith, Sean Ho, James C. Gee, and Guido Gerig. ”User-guided 3D Active
Contour Segmentation of Anatomical Structures: Significantly Improved Ef-
ficiency and Reliability.” NeuroImage 31.3 (2006): 1116-128. Print.
[14] Zhang, Q., X. Bai, M. Akutagawa, H. Nagashino, Y. Kinouchi, F. Shichijo,
S. Nagahiro, and L. Ding. ”A Method for Two EEG Sources Localization
by Combining BP Neural Networks with Nonlinear Least Square Method.”
Control, Automation, Robotics and Vision, 2002. ICARCV 2002. 7th Inter-
national Conference 1 (2002): 536-41. Print.
[15] Zhang, Qinyu, Motohiro Yuasa, Hirofumi Nagashino, and Yohsuke Kinouchi.
”Single Dipole Source Localization From Conventional EEG Using BP Neural
Networks.” Engineering in Medicine and Biology Society, 1998. Proceedings
of the 20th Annual International Conference of the IEEE 4 (1998): 2163-166.
Print.
71](https://image.slidesharecdn.com/13fb5e4b-929d-47ad-8fa5-3e1e6f3e4f68-150920202341-lva1-app6892/75/Berard-Thesis-85-2048.jpg)




















































![[Research] Detection of MCI using EEG Relative Power + DNN](https://cdn.slidesharecdn.com/ss_thumbnails/20180619a-gisteegaddiagnosisdkimconference-180622113717-thumbnail.jpg?width=640&height=640&fit=bounds)





![EEG BASED MOTOR IMAGERY DECODING [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/eegbasedmotorimagerydecodingautosaved-251208043154-f4c6e54a-thumbnail.jpg?width=640&height=640&fit=bounds)




