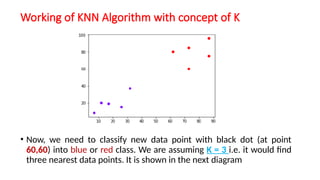
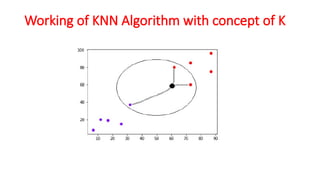
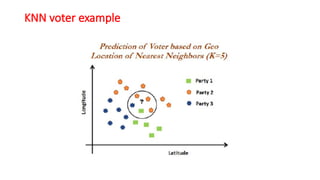
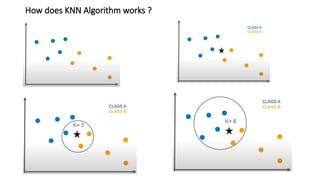
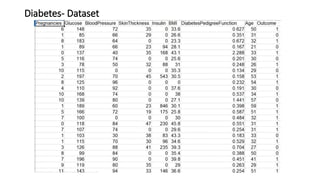
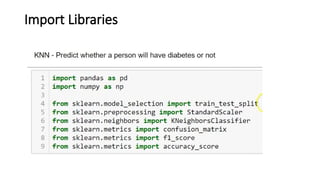
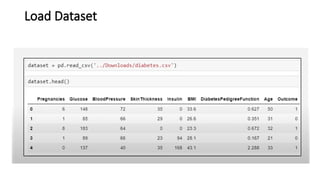
The document explains the k-nearest neighbors (KNN) algorithm, a supervised machine learning technique primarily used for classification, which relies on feature similarity. It highlights its properties such as lazy learning and non-parametric nature, along with a step-by-step working process, advantages, disadvantages, and various applications in fields like banking, politics, and healthcare. Additionally, the document covers related concepts such as the curse of dimensionality and introduces naive Bayes classification methods.















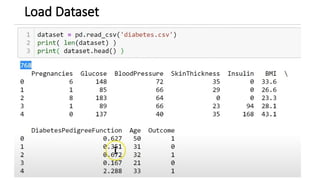
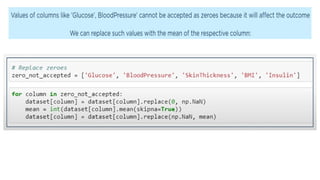
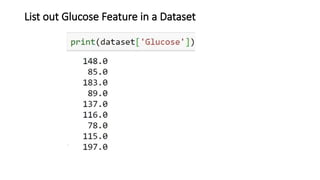
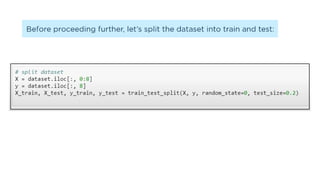
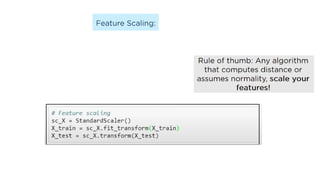

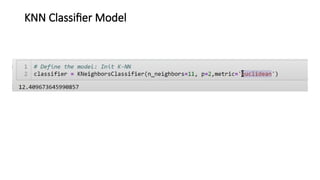
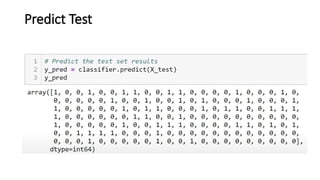

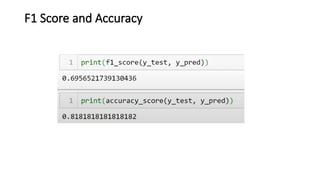



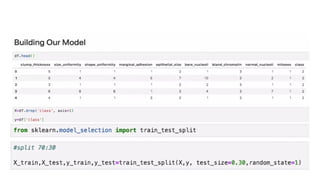
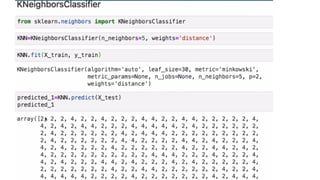
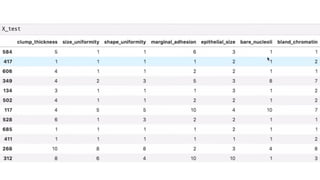
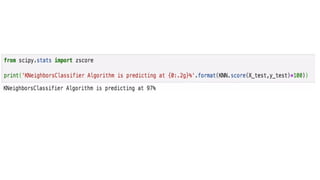
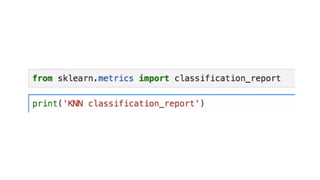
![KNN-Predictions
knnPredictions=pd.DataFrame(predicted_1)
df1=pd.([knnPredictions], axis =1)
df1](https://image.slidesharecdn.com/sml-unit-3-250102082127-f597d75e/85/Statistical-Machine-Learning-unit3-lecture-notes-48-320.jpg)









































![k-nearestneighborknn-231215171119-a5cfb915.pptx [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/k-nearestneighborknn-231215171119-a5cfb915-251010013925-09814a4b-thumbnail.jpg?width=640&height=640&fit=bounds)


































