Batch Normalization: Accelerating
DeepNetwork Training by Reducing
Internal Covariate Shift
A PAPER PRESENTATION ON -
P U B L I S H E D I N
I n t e r n a t i o n a l C o n f e r e n c e o n M a c h i n e
L e a r n i n g ( I C M L )
P U B L I S H E D O N
J u l y , 2 0 1 5
D A T E : 2 7 D E C , 2 0 2 4
2.
PRESENTED BY
MD. JAMILHASAN
ID: 212902029
Dept. of CSE
Green University of Bangladesh
MD. SAIFUL ISLAM RIMON
ID: 213002039
Dept. of CSE
Green University of Bangladesh
MAHJABIN RAHMAN
ID: 213002259
Dept. of CSE
Green University of Bangladesh
2
3.
DR. MUHAMMAD ABULHASAN
Chairperson
Dept. of ADS
Green University of Bangladesh
A SPECIAL THANKS TO,
3
Challenges in TrainingDeep Neural
Networks
the input distribution to a layer changes
during training as parameters of
preceding layers update.
Key issue: Internal Covariate Shift Impact on Training
•Requires careful initialization and small
learning rates.
•Nonlinearities (e.g., Sigmoid) saturate
gradients, slowing convergence.
•Amplified with increasing depth of
networks.
6
7.
•Here,
• is thelearning rate
•m is the mini-batch size
•F2 is the stand-alone network
•x is the input
Challenges in Training Deep Neural
Networks
• Where ...N is the training dataset,
and ℓ is the loss function.
Optimization Objective: Gradient Descent for sub-network
7
8.
. -
Problem?
Internal CovariateShift
What Causes Internal Covariate Shift?
• Layers need to adapt to changing
input distributions during training.
• Example: In a sub-network,
ℓ = ((u, ), ),
changes in shifts the distribution of
• Gradient ℓ vanish if inputs saturate
nonlinearities (e.g., Sigmoid
activation)
• This slows down training and
deepens optimization
challenges.
8
9.
Batch Normalization —A Solution to Internal
Covariate Shift
• Goal: Stabilize input distributions to accelerate training.
• Batch Normalization:
• Normalizes inputs across a mini-batch.
• Reduces dependency on careful initialization and mitigates
vanishing gradients.
Concept:
• Normalization fixes input mean and variance across batches, improving
gradient flow and optimization stability.
9
•Here,
x: Input tothe layer.
•E[x]: Mean of the mini-batch.
•Var[x]: Variance of the mini-batch.
•ϵ: Small constant added for numerical
stability.
Normalization via Mini-Batch Statistics
• Batch Normalization (BN)
normalizes layer inputs using
statistics from mini-batches.
11
12.
Training and Inferencewith Batch-
Normalized Networks
Normalization: Each layer's inputs are
normalized using mini-batch statistics.
Training Phase:
Inference Phase:
Uses running averages of μ and σ²
computed during training for consistent
performance on unseen data.
• Compute mini-batch mean μᵦand
variance σᵦ².
• Normalize the input: x
̄
• Scale and shift: y=BNγ,β
(x)=γx
̄ +β
• Where, γ and β are learnable
parameters.
Key Algorithm:
12
13.
. -
Impact onPerformance:
Integration with
Convolutional Layers:
Batch-Normalized Convolutional Networks
• BN can be applied after
convolutional layers to stabilize
feature distributions.
• Achieves higher accuracy with fewer
training steps.
• Facilitates training of deeper
architectures by mitigating
vanishing/exploding gradients.
Key Benefits:
• Reduces sensitivity to weight
initialization.
• Enhances performance of deep
networks.
13
14.
. -
Algorithm forTraining a Batch-Normalized
Network
Input:
● A network N with trainable
parameters Θ.
● A subset of activations
across layers.
Output:
● A batch-normalized network
for inference,
• Steps:
• Create a Training Version of the Network:
• Transform the network N into a batch-
normalized version
, by:
• Adding a normalization layer
to each layer's output xᵏ .
• Modifying all layers to use yᵏ as input
instead of xᵏ .
• Train the Network:
• Optimize the parameters Θ, along with the BN-
specific parameters γᵏ and βᵏ, to minimize the
loss function.
14
15.
. -
Algorithm forTraining a Batch-Normalized
Network
Input:
● A network N with trainable
parameters Θ.
● A subset of activations
across layers.
Output:
● A batch-normalized network
for inference,
• Prepare for Inference:
• Freeze the learned parameters γᵏ, βᵏ and
compute global statistics for normalization:
• Mean (E[x]): Averaged over all mini-batches.
• Variance (Var[x]): Adjusted using a factor
m/(m-1) to account for small sample bias.
• Replace Batch-Normalization in
:
• Use pre-computed global statistics during
inference:
15
16.
Batch Normalization andHigher Learning
Rates
BN allows larger learning rates without
divergence.
Higher Learning Rates: Resilience to Parameter Scale:
BN decouples parameter scale from
gradient propagation, allowing
aggressive optimization.
BN(Wu)=BN((aW)u)
• Where:
• W: Layer parameters.
• u: Input to the layer.
• a: Scalar that scales the parameters
The Equation:
Overall Benefits:
Accelerates convergence and reduces
the need for other regularization
techniques (e.g., Dropout).
16
17.
Batch Normalization Experiments
andConclusion
04 & 05
Batch Normalization: Accelerating Deep
Network Training by Reducing
Internal Covariate Shift
SECTION
17
18.
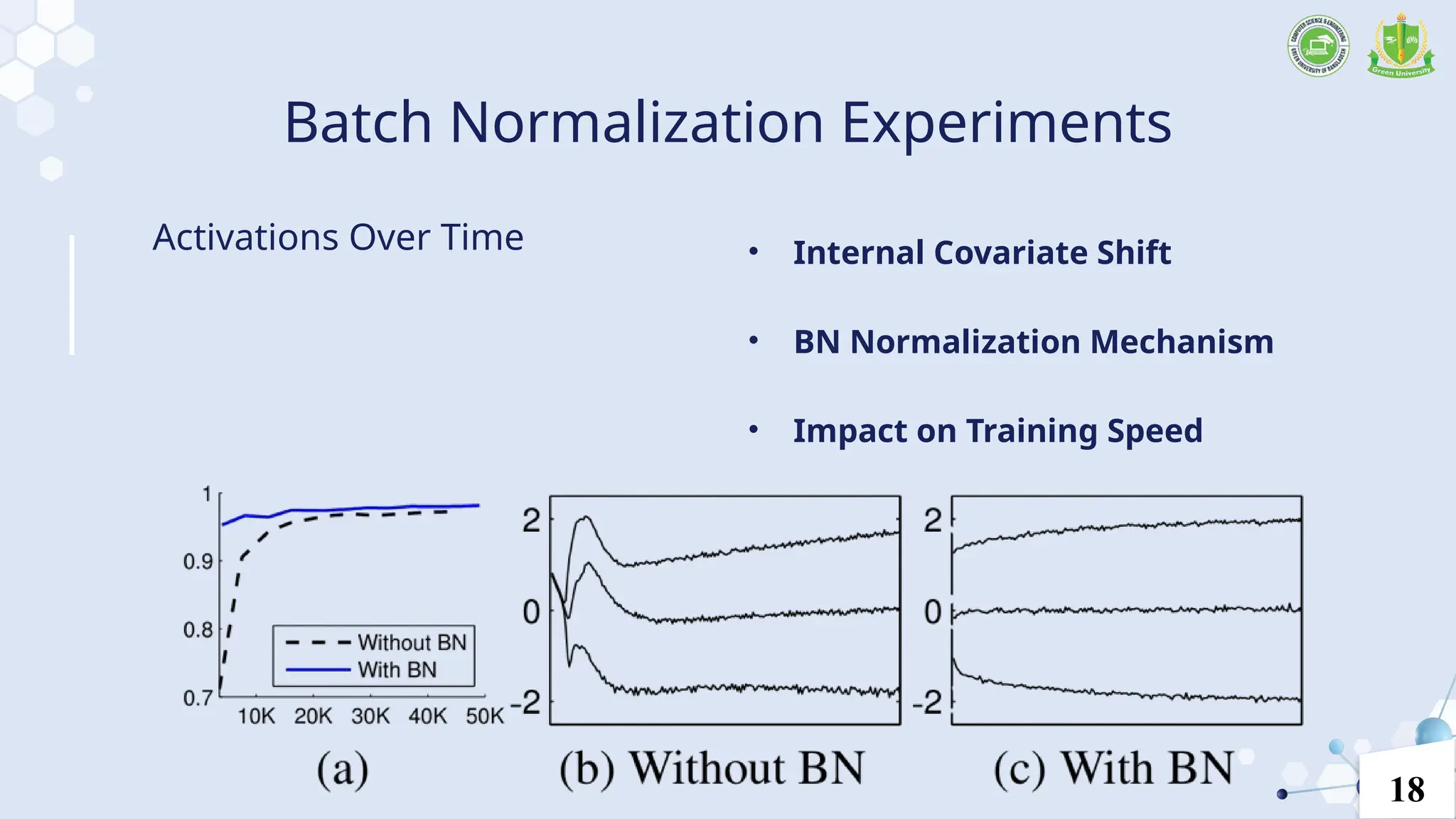
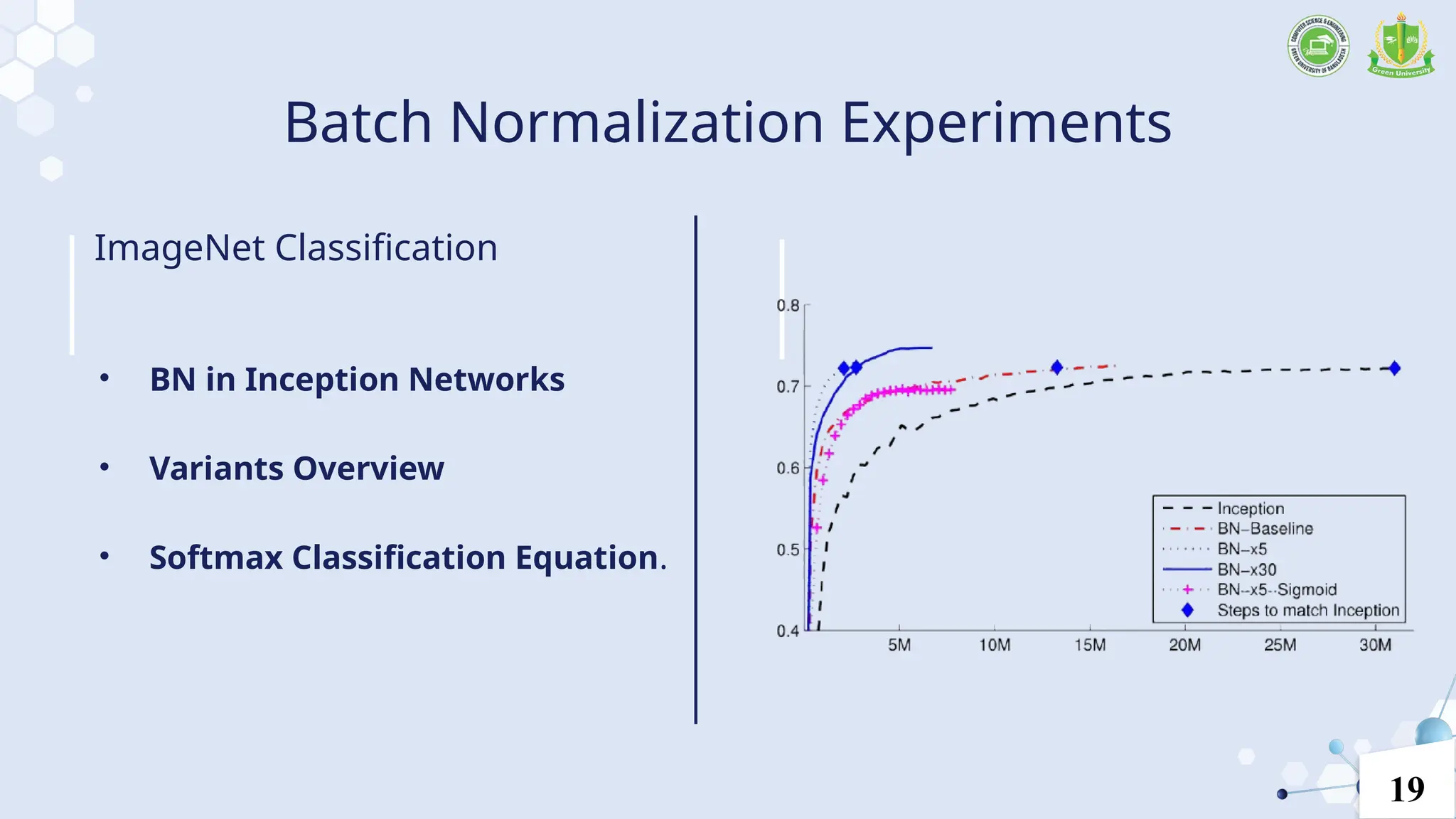
Batch Normalization Experiments
•Internal Covariate Shift
• BN Normalization Mechanism
• Impact on Training Speed
Activations Over Time
18
#5 Today, I’ll discuss a key challenge in training deep neural networks — Internal Covariate Shift — and the solution proposed in the paper: Batch Normalization. Let’s dive in.
#6 Slide 1 highlights the main problem. During training, the input distribution to each layer changes as parameters of previous layers are updated. This is known as Internal Covariate Shift. Why is this a problem? It slows down training by requiring small learning rates and careful initialization. Nonlinearities, like the sigmoid activation, saturate gradients when inputs are large, making training even slower
#7 Mathematically, the network optimizes parameters Θ\ThetaΘ to minimize the loss function: /////////////////
However, changing inputs make gradient updates unstable, slowing convergence.
For example, in gradient descent, the sub-network optimization can be expressed as: /////////////////////
#8 Now, let’s understand why Internal Covariate Shift happens. Consider a sub-network where the loss is defined as: ////////////
Here, F1 and F2 are transformations, and Theta_1, Theta_2 are the parameters to be optimized. The output x=F1(u,Θ1) acts as the input to F2. When Θ1 changes, the input x to the second layer, F2, also changes.
The challenge is that if the input x shifts too much during training, the gradients become unstable. This is further amplified when using activation functions like the sigmoid, which saturates for large inputs. The gradient of sigmoid activation is:////////////
As x→∞, the gradient g′(x) approaches zero, leading to vanishing gradients and slowing down training.”
#9 To address the issue of Internal Covariate Shift, the authors propose a solution called Batch Normalization. The goal of Batch Normalization is to stabilize the input distributions to each layer during training.
………………..










![•Here,
x: Input to the layer.
•E[x]: Mean of the mini-batch.
•Var[x]: Variance of the mini-batch.
•ϵ: Small constant added for numerical
stability.
Normalization via Mini-Batch Statistics
• Batch Normalization (BN)
normalizes layer inputs using
statistics from mini-batches.
11](https://image.slidesharecdn.com/mlpres-250513181906-130e9fd4/75/machine_learning-_presentation_on_paperpptx-11-2048.jpg)



![. -
Algorithm for Training a Batch-Normalized
Network
Input:
● A network N with trainable
parameters Θ.
● A subset of activations
across layers.
Output:
● A batch-normalized network
for inference,
• Prepare for Inference:
• Freeze the learned parameters γᵏ, βᵏ and
compute global statistics for normalization:
• Mean (E[x]): Averaged over all mini-batches.
• Variance (Var[x]): Adjusted using a factor
m/(m-1) to account for small sample bias.
• Replace Batch-Normalization in
:
• Use pre-computed global statistics during
inference:
15](https://image.slidesharecdn.com/mlpres-250513181906-130e9fd4/75/machine_learning-_presentation_on_paperpptx-15-2048.jpg)