Download as PDF, PPTX











![DEA(v1.0), logical enhancement
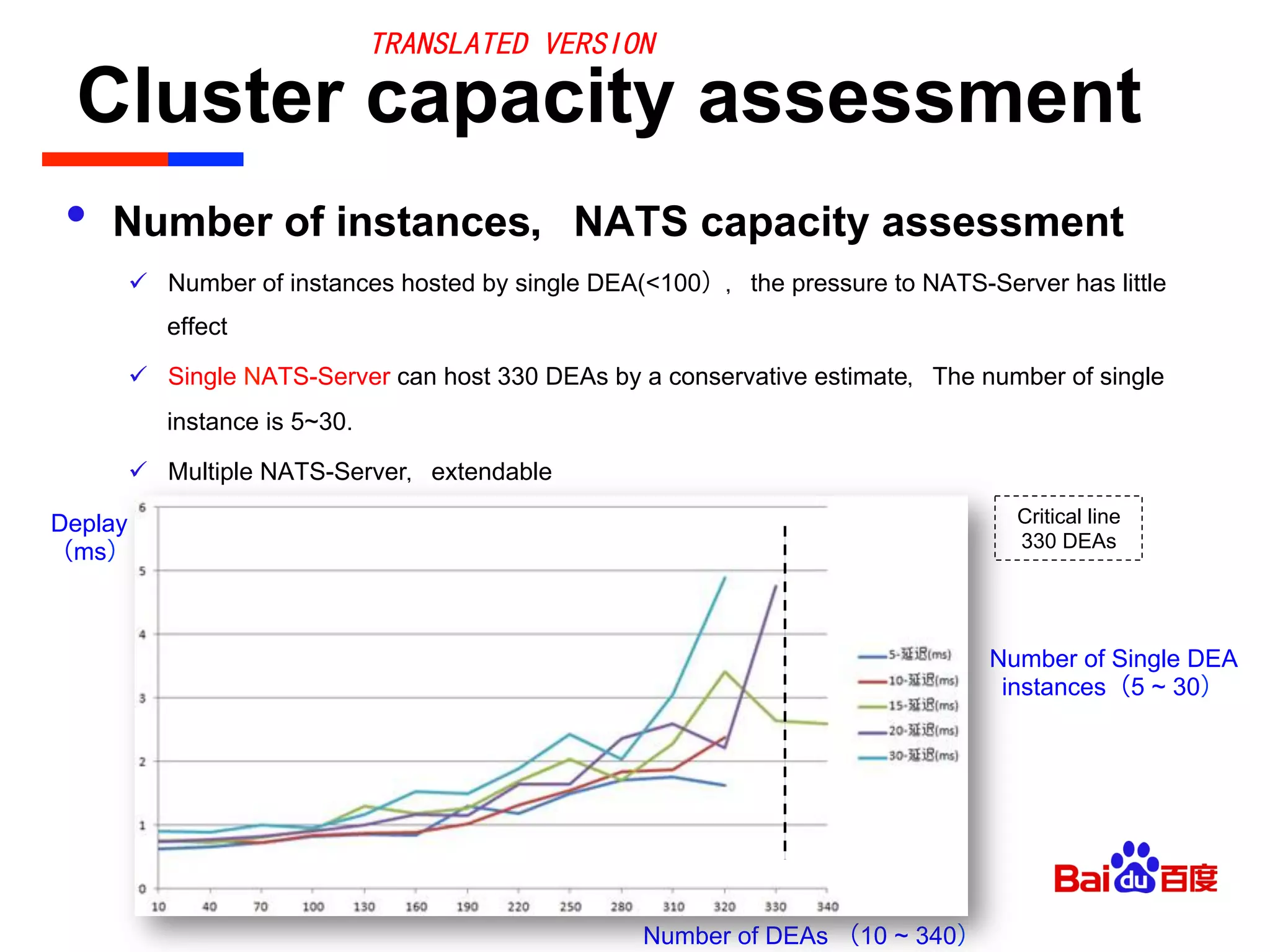
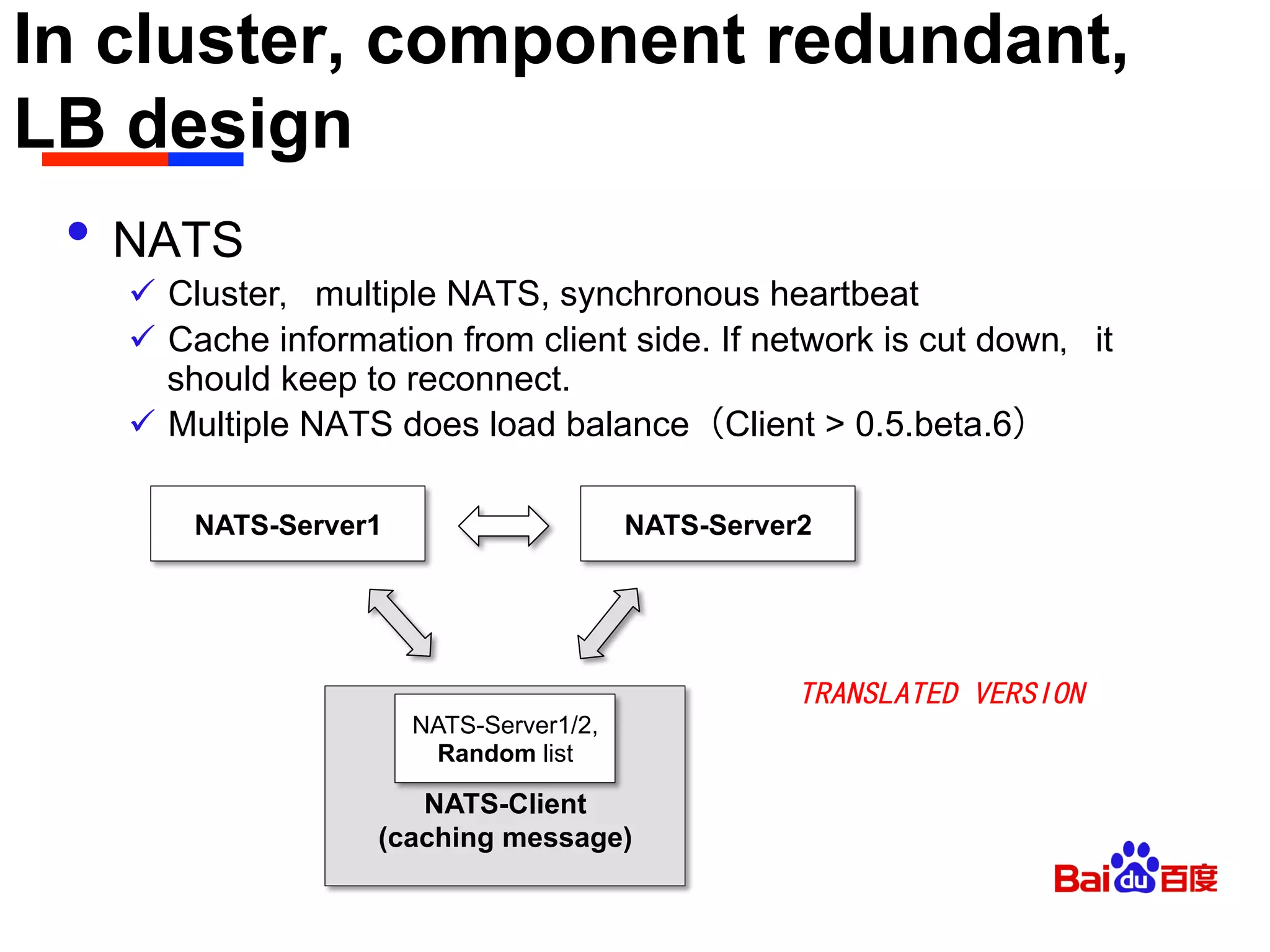
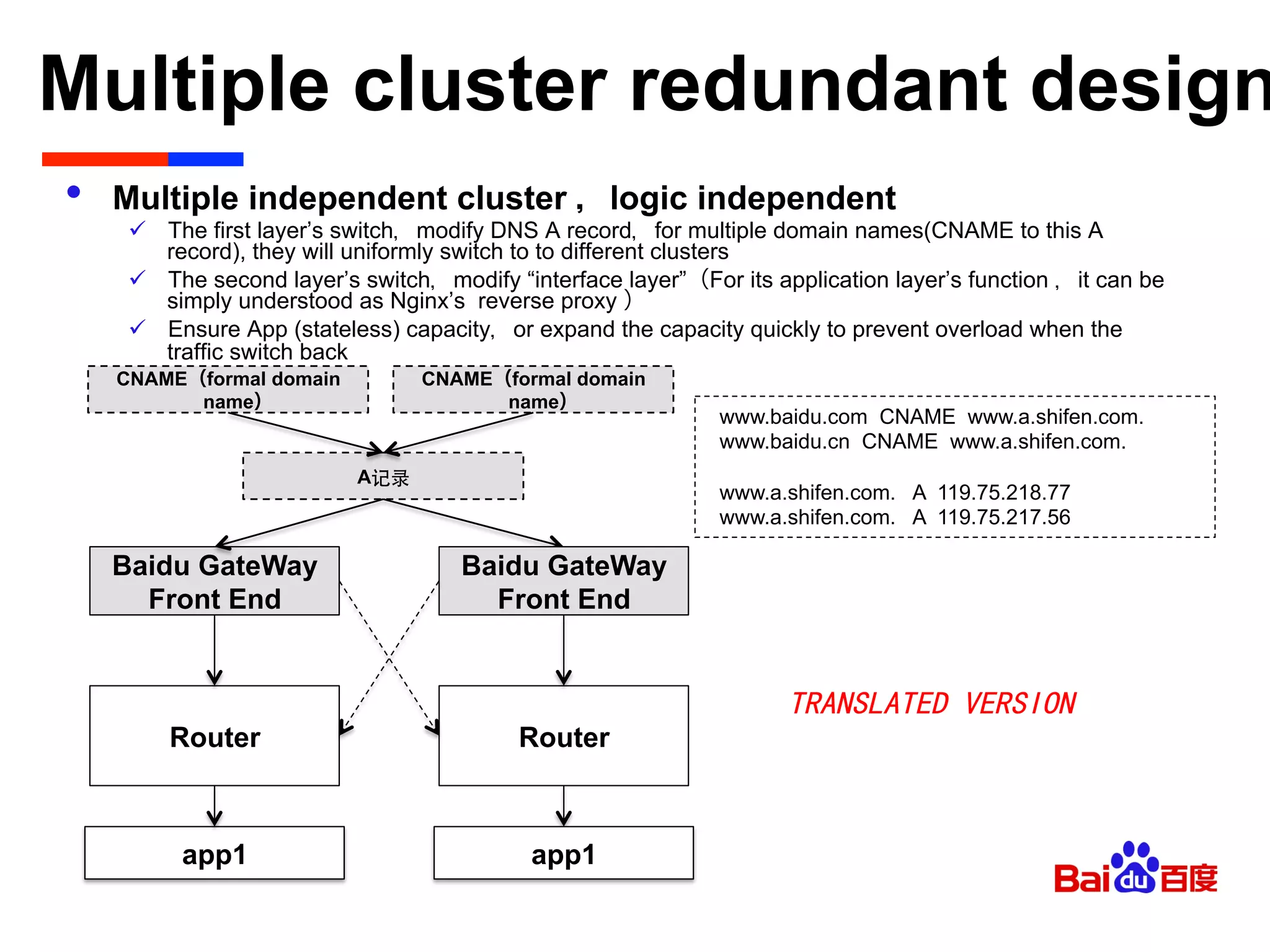
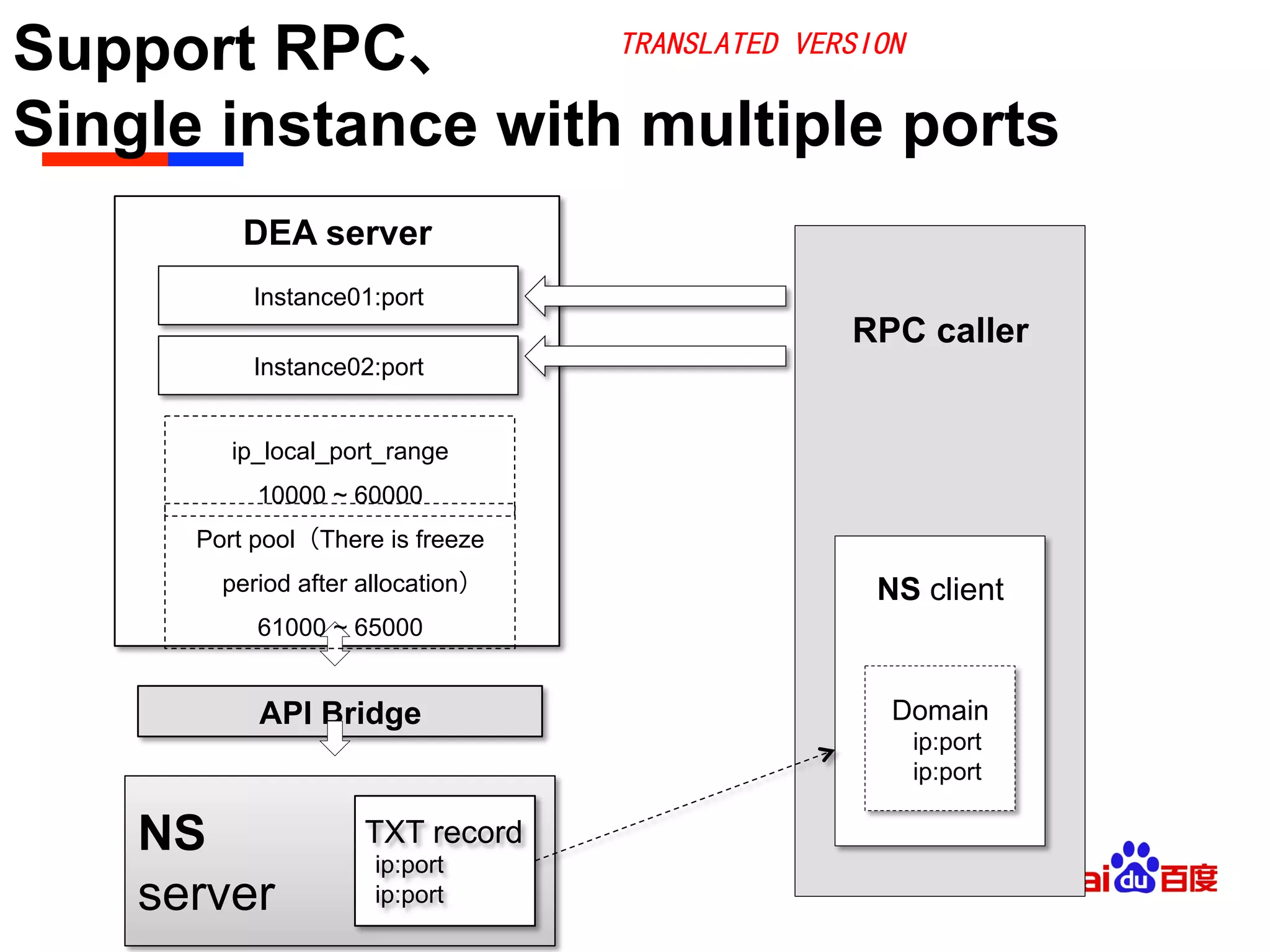
• Ports Management
ü Description
⁺ Single DEA, multiple instance,parallel to assign and start the port,there is no
critical line,but there is the port competition issue
ü Solution
⁺ Reference DEA(v2.0)’s logic(Notes: it’s DEA_NG, not compatible with CF1.0)
⁺ Define ip_local_port_range as 10000~61000,it is dynamic ports’ range
⁺ Make 61001~65000 as DEA scheduling assigned ports
⁺ For assigned port,add “[release time、port num]” data structure
⁺ It resolve the port competition by delaying to release the port
ü Note
⁺ CF2.0 has resolved this problem by the same method above.
TRANSLATED VERSION](https://image.slidesharecdn.com/baiducloudfoundryenglish-130725134121-phpapp01/75/Baidu-cloudfoundry-english-22-2048.jpg)







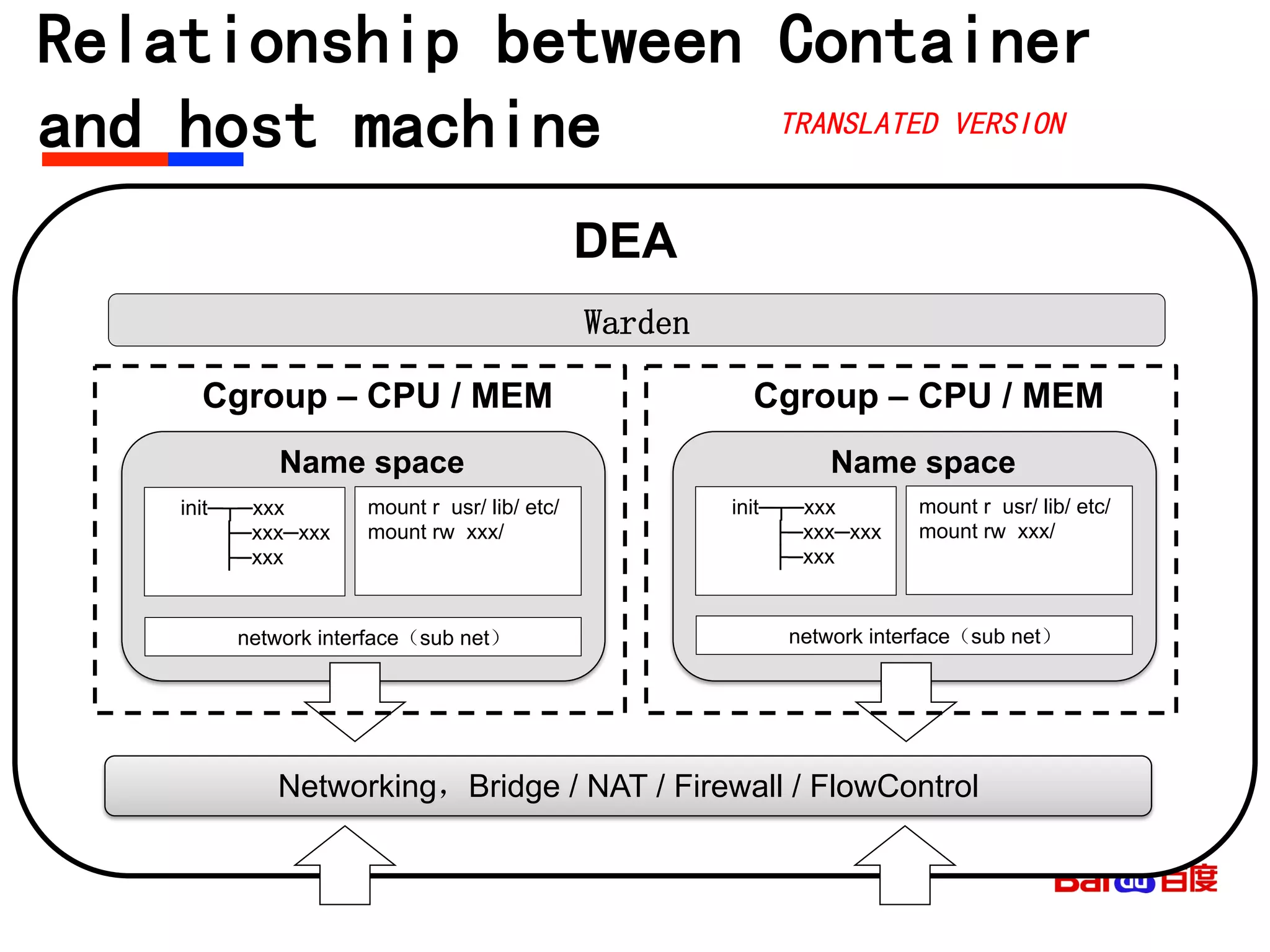

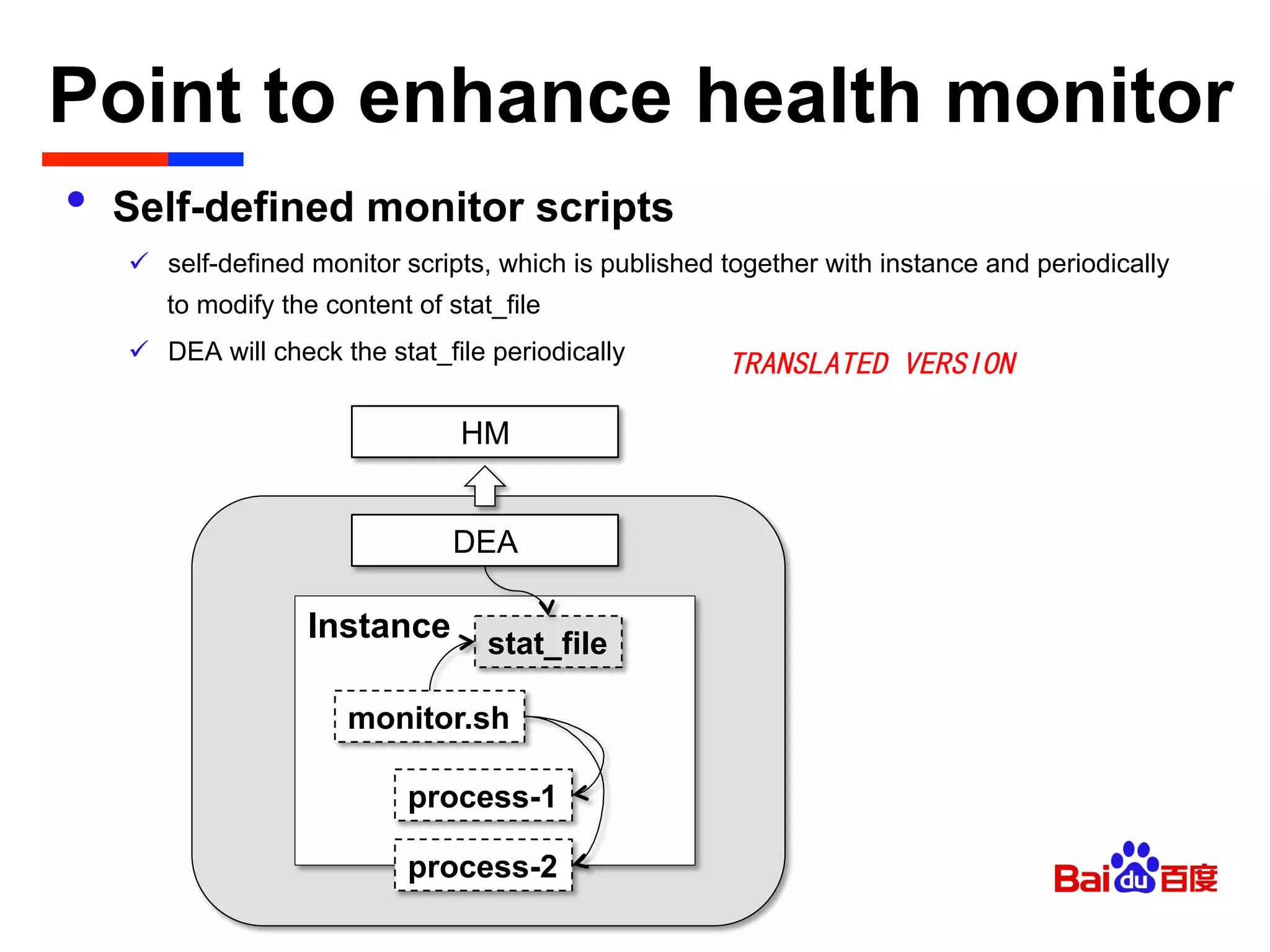

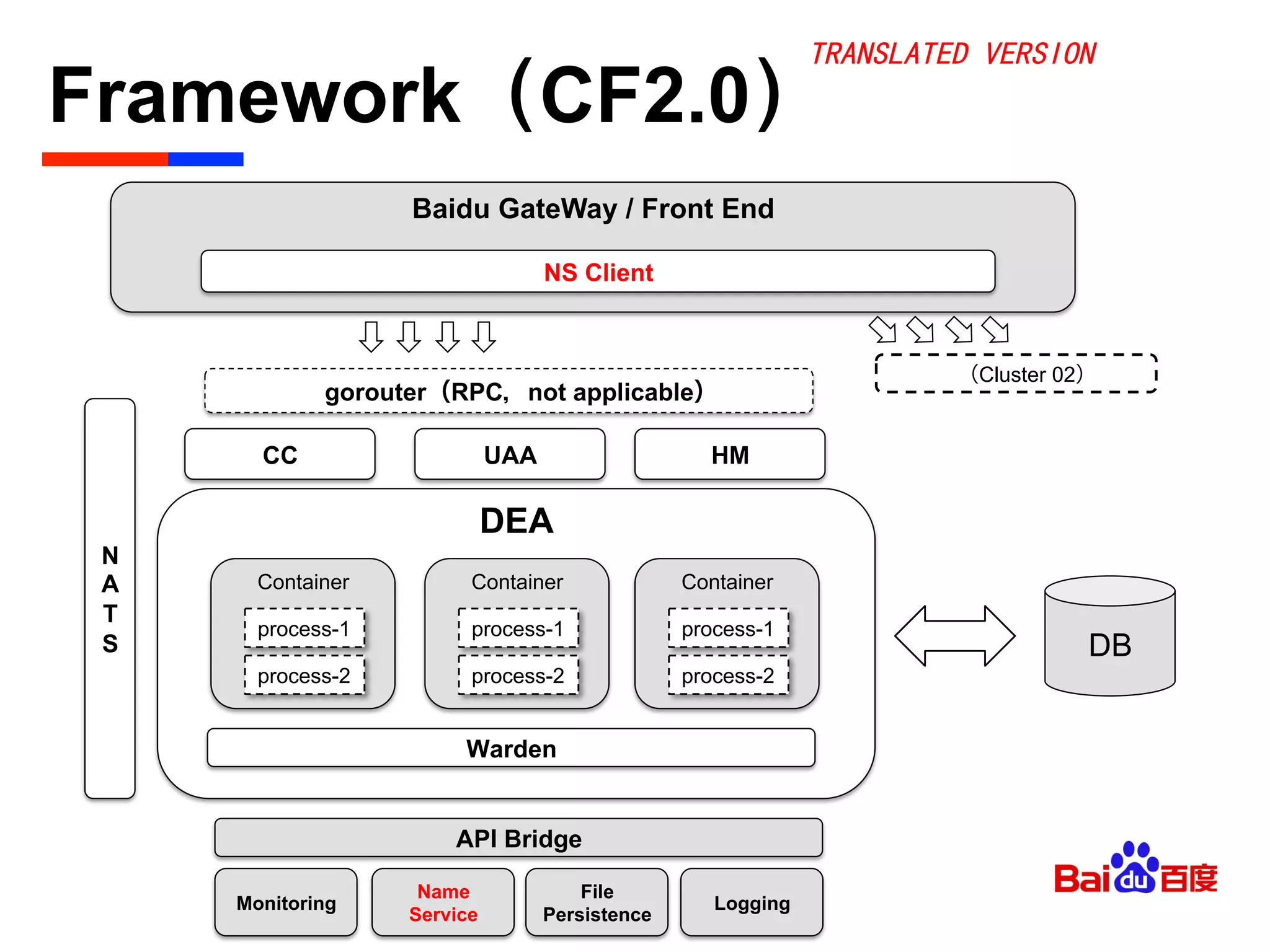


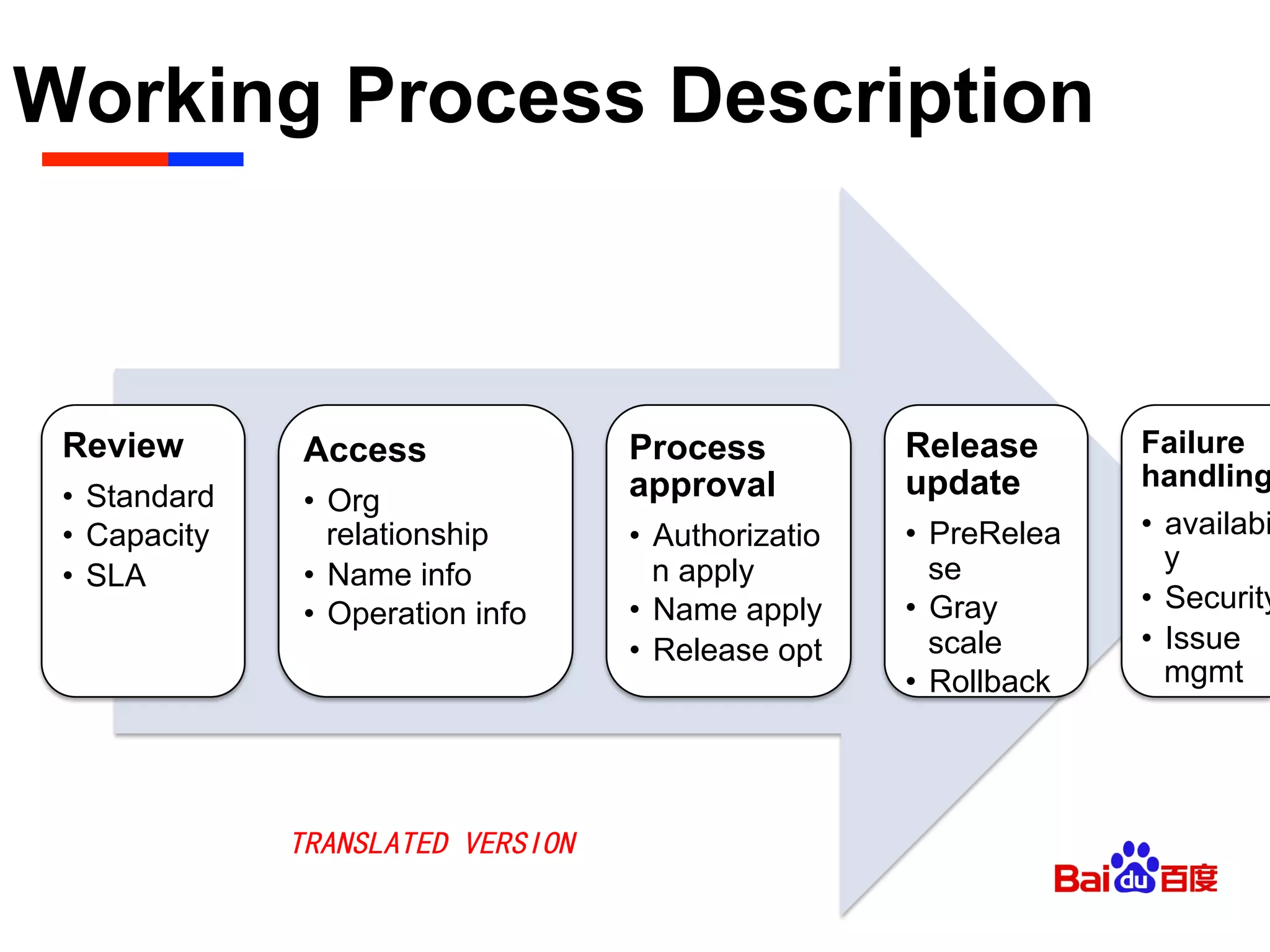


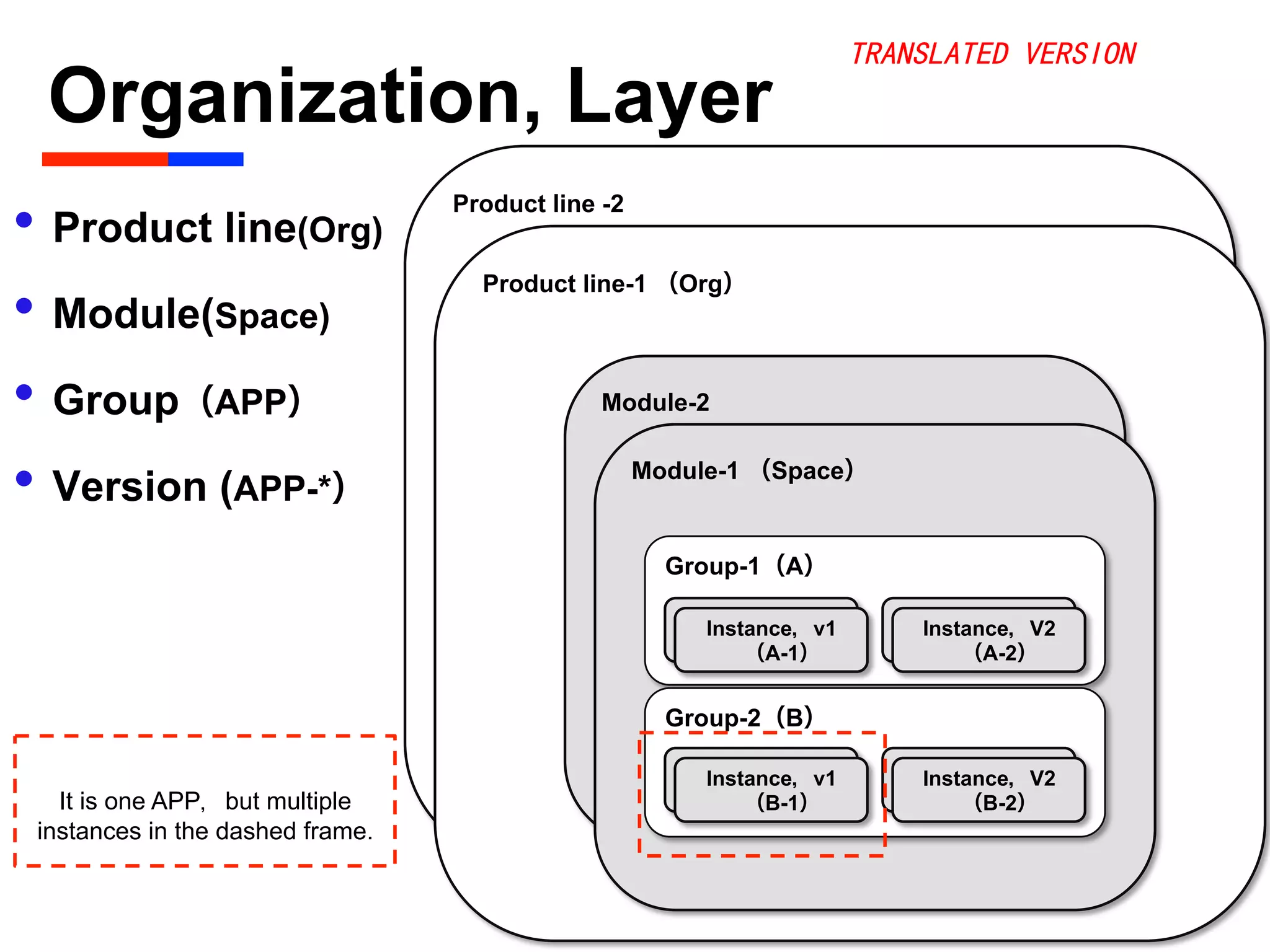




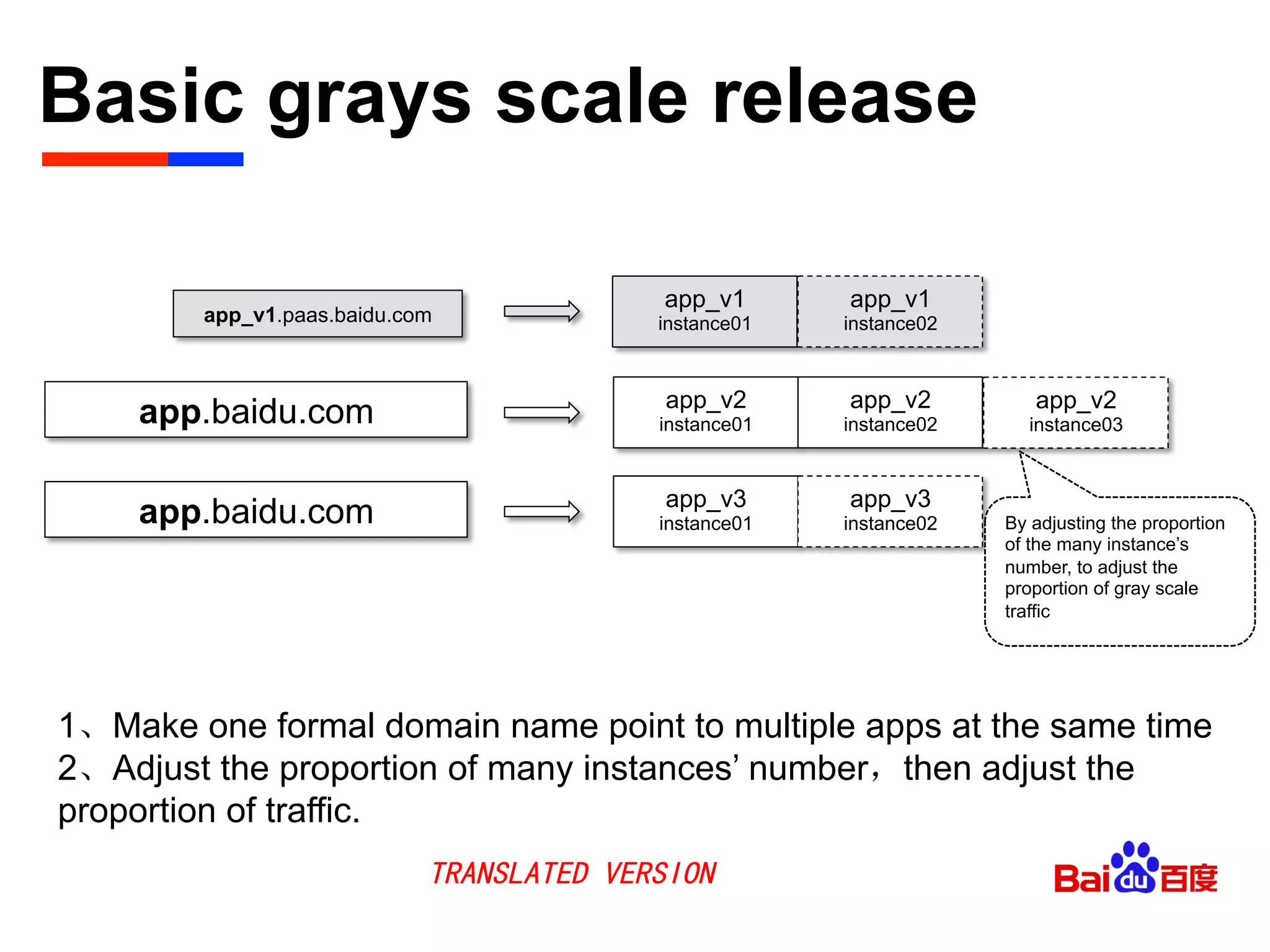




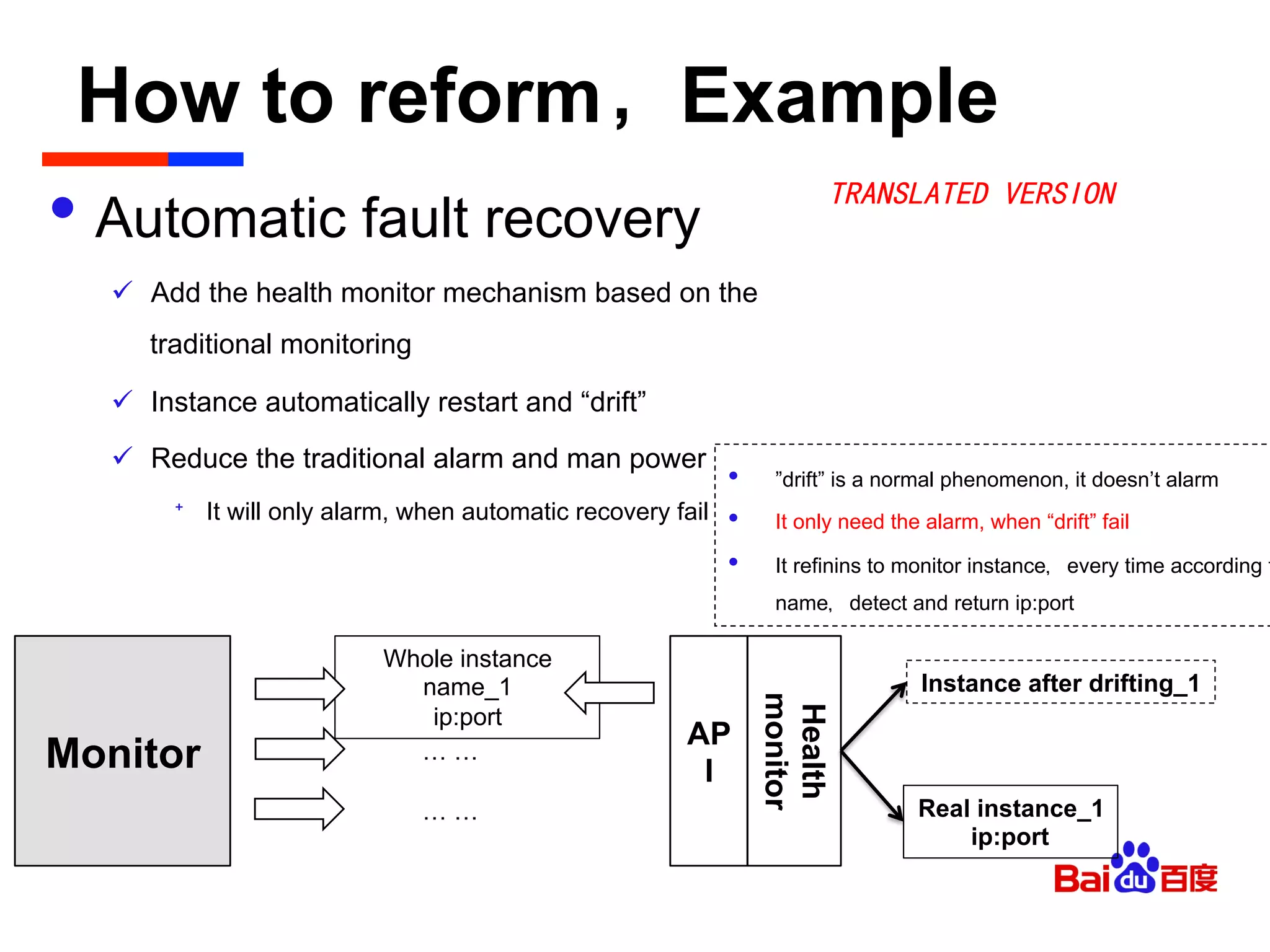





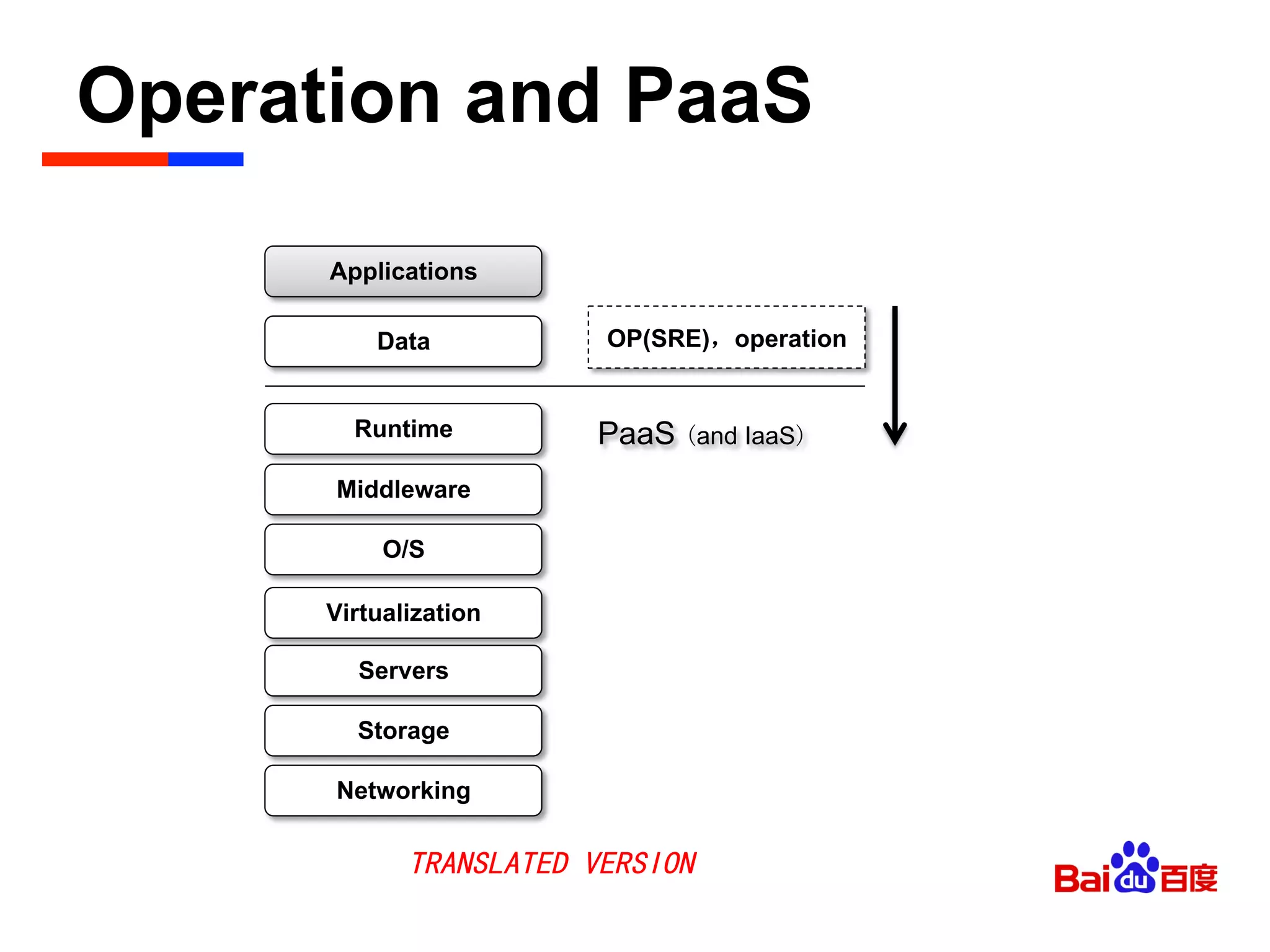
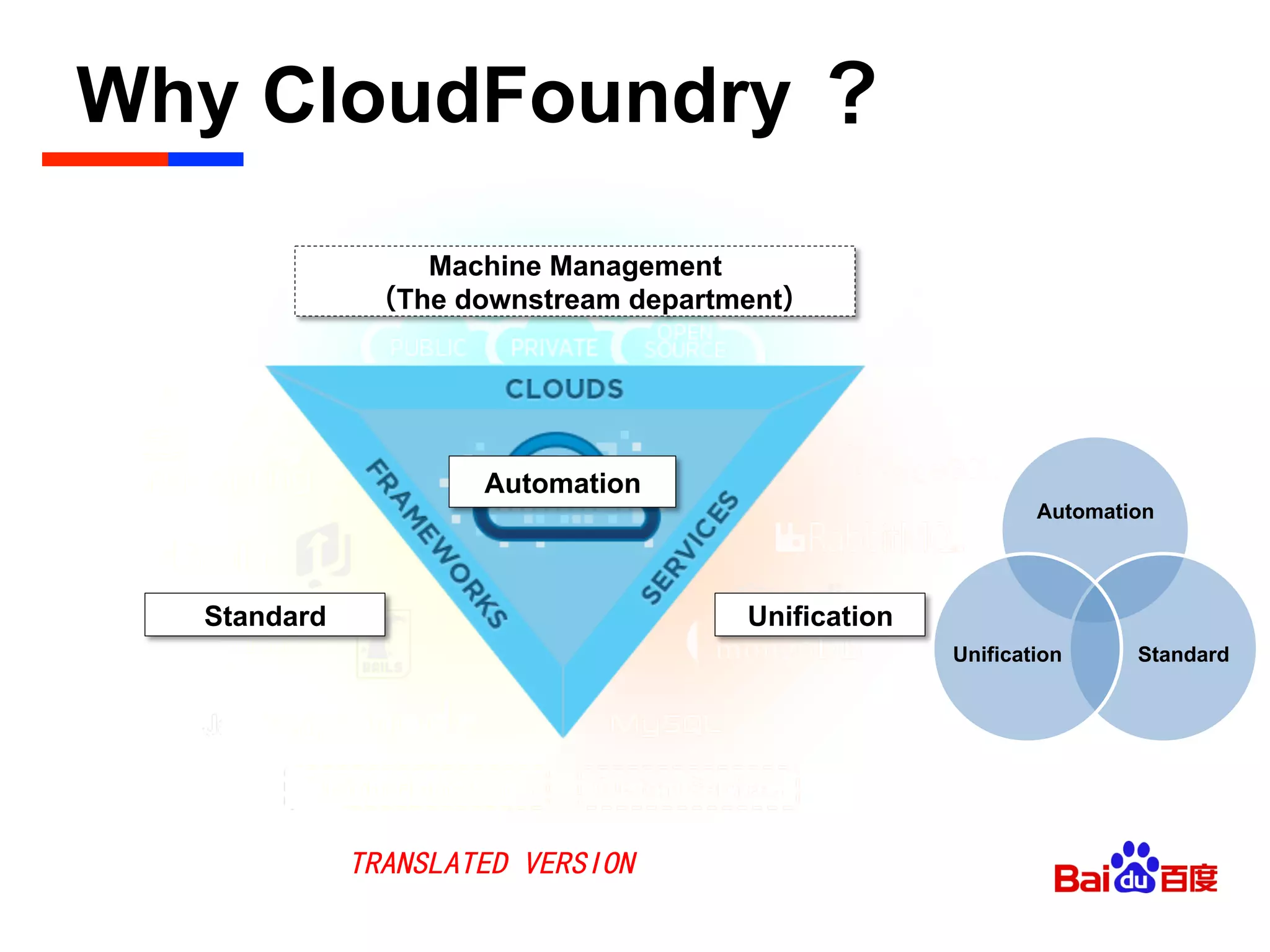
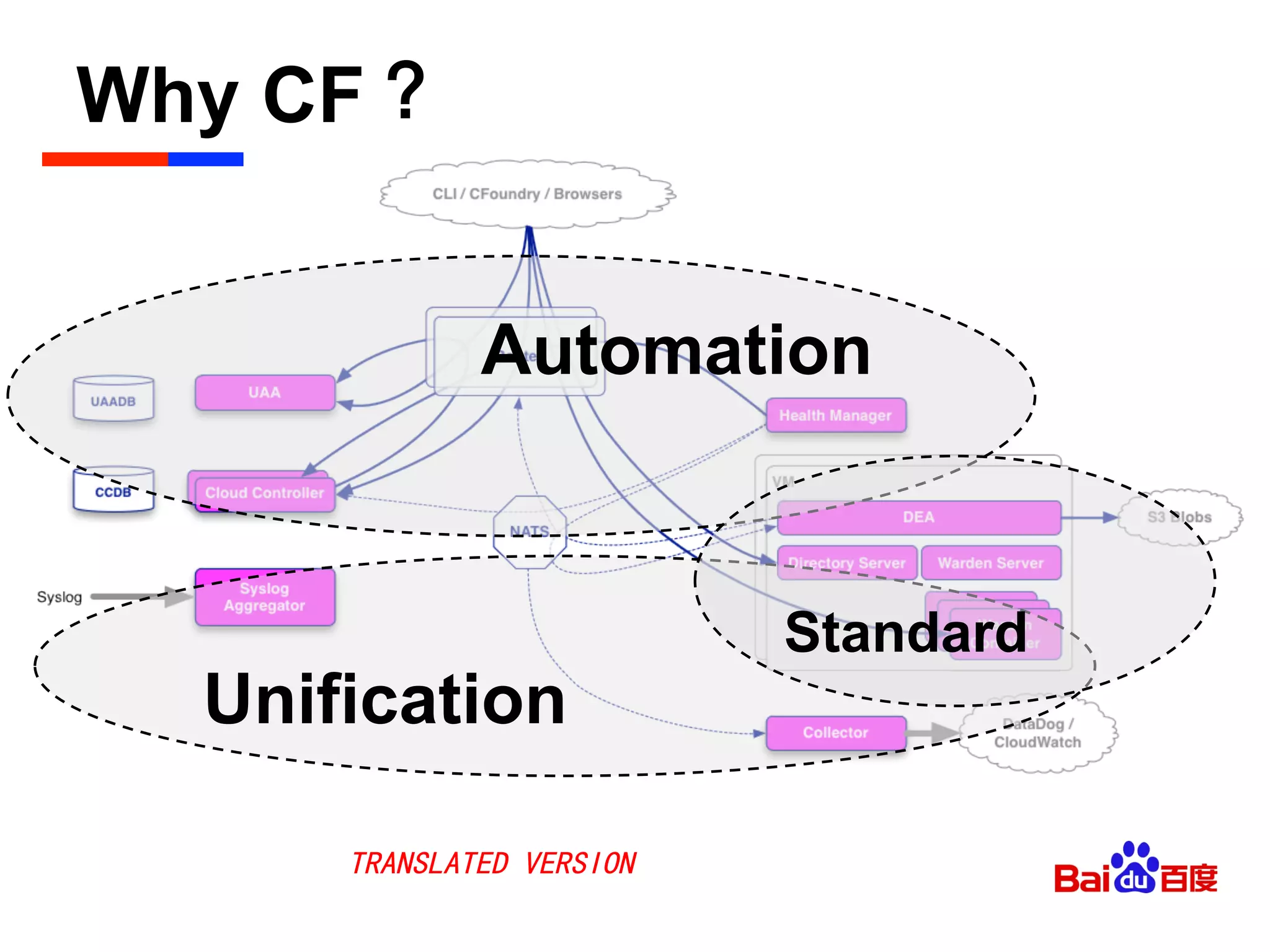
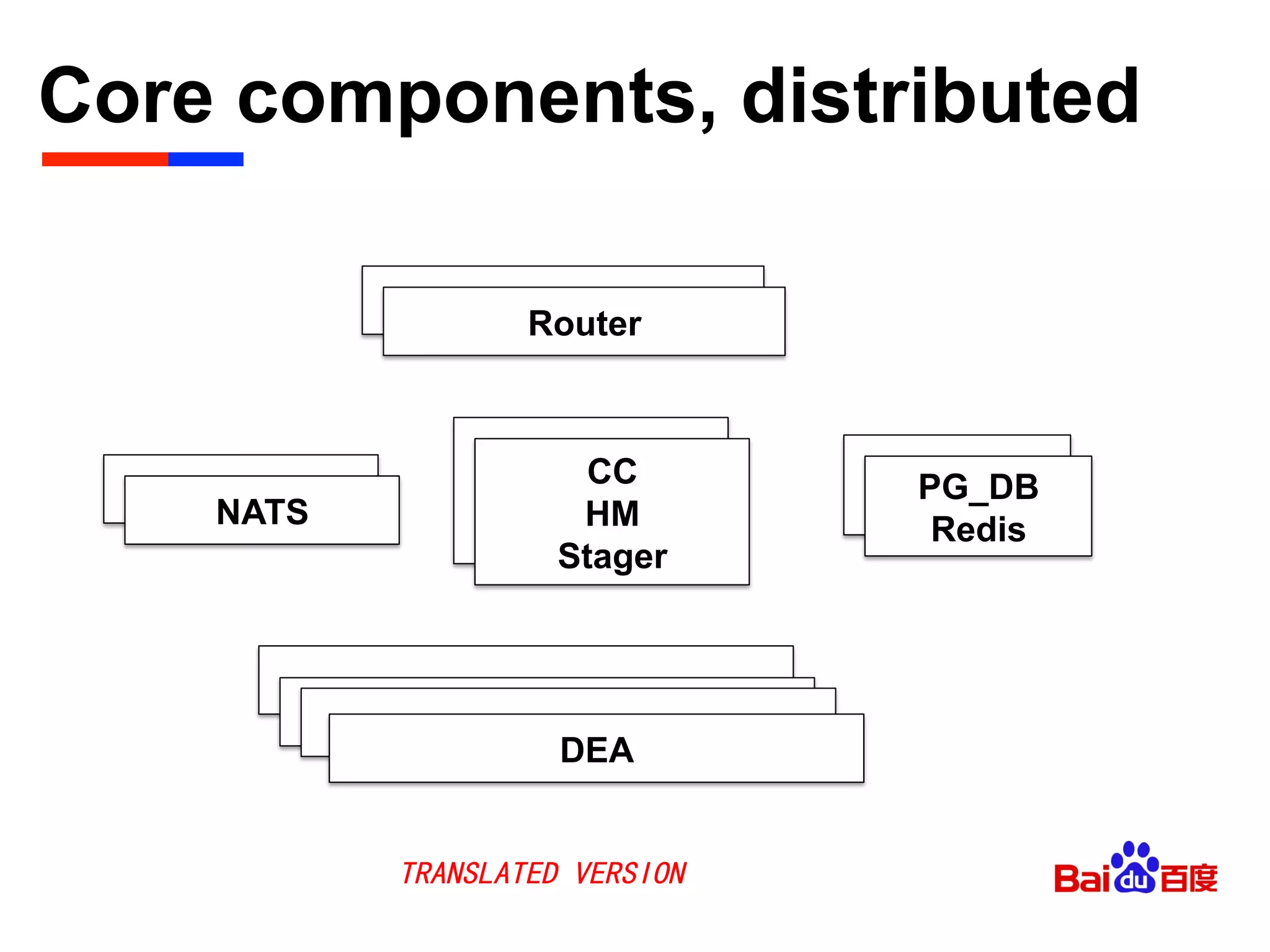
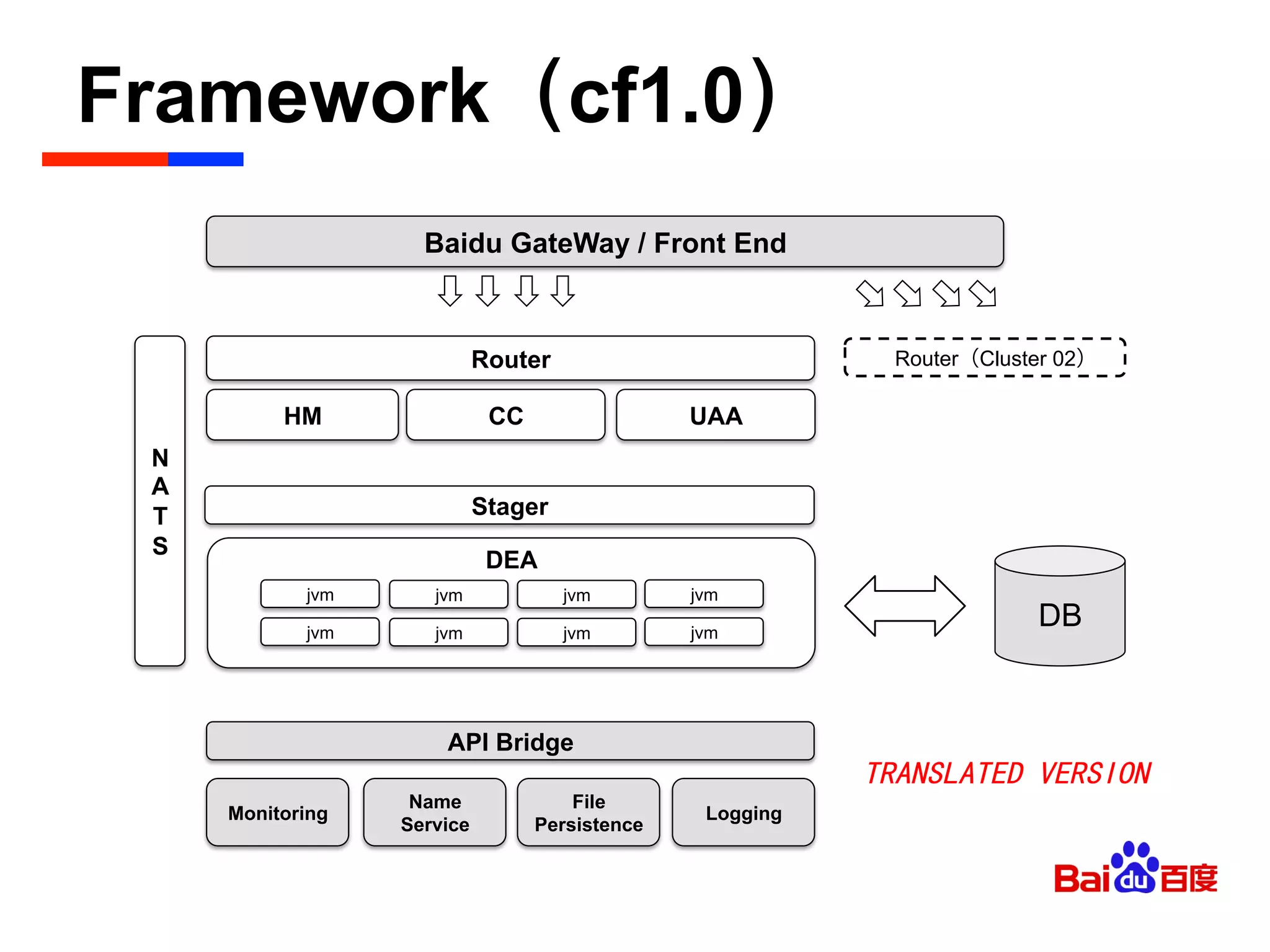
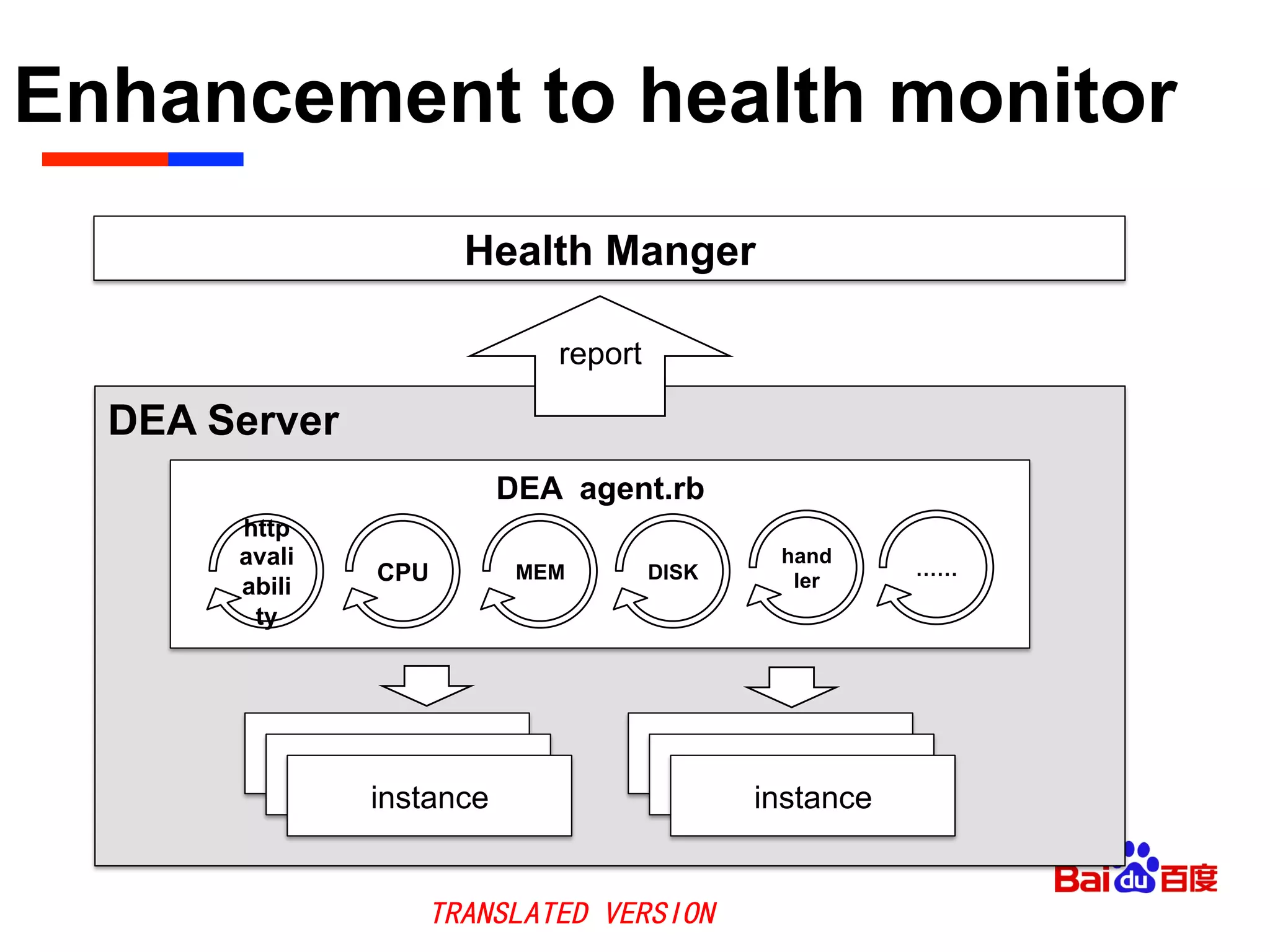
The document discusses Baidu's implementation of a private cloud platform based on CloudFoundry, including reforms made to support Java and C/C++ applications, standardizing processes, and future plans. It describes practices around automating operations, unifying standards, and linking the platform to other systems through components like file persistence and monitoring. Key reforms involved adapting CloudFoundry to CentOS, enhancing health monitoring, and supporting features like RPC and JMX access.























































![[WSO2Con Asia 2018] Architecting for Container-native Environments](https://cdn.slidesharecdn.com/ss_thumbnails/v2-wso2con2018-architectingforcontainernativeenvironments-180810085834-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Srijan Wednesday Webinars] How to Build a Cloud Native Platform for Enterpri...](https://cdn.slidesharecdn.com/ss_thumbnails/srijanwwcloudnativeplatformfordrupal-181213101558-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















