Downloaded 145 times




















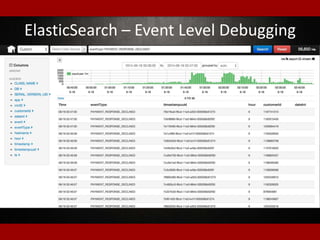


















![States Are Nice
transition_space = MoneytreeTransitionsSpace.build_cross_product(
entity=me,
gateways=ALL_GATEWAYS,
plans=[Pro100, Pro200, Pro500, DfB, DfBTrial],
schedules=[Monthly, Yearly],
currencies=ALL_CURRENCIES,
features=ALL_FEATURES,
tax_profile=[NoTax, SimpleTax, ComplexTax],
)
# …
If transition_space.supports(FEATURE_PACKRAT):
# …](https://image.slidesharecdn.com/billing-payments-meetup-140701014401-phpapp01/85/6-18-14-Billing-Payments-Engineering-Meetup-I-47-320.jpg)



























![Lumos Labs, Inc.
class SanityCheck
Methods = [:subscriber?, :transaction_count] # etc.
def initialize(record)
@record = record
@before_values = SanityCheck.values(record)
end
def self.values(record)
Methods.map { |m| [m, record.send(m)] }.to_h
end
end
enter the
sanity check](https://image.slidesharecdn.com/billing-payments-meetup-140701014401-phpapp01/85/6-18-14-Billing-Payments-Engineering-Meetup-I-75-320.jpg)
![Lumos Labs, Inc.
class SanityCheck
...
def check
@after_values = SanityCheck.values(record)
@diff = diff(@before_values, @after_values)
end
def diff(a, b)
a.delete_if { |k, v| b[k] == v }
.merge!(b.dup.delete_if { |k, v| a.has_key?(k) })
end
end
enter the
sanity check](https://image.slidesharecdn.com/billing-payments-meetup-140701014401-phpapp01/85/6-18-14-Billing-Payments-Engineering-Meetup-I-76-320.jpg)



























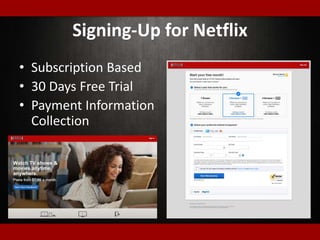
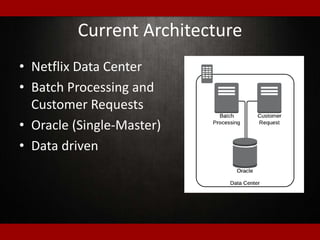
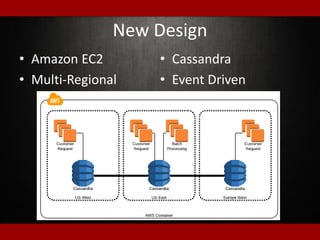
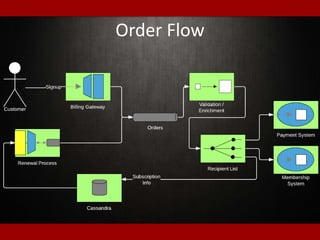
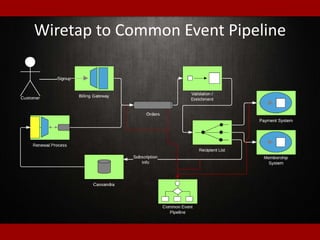
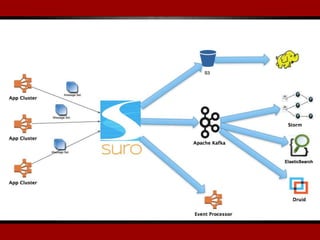
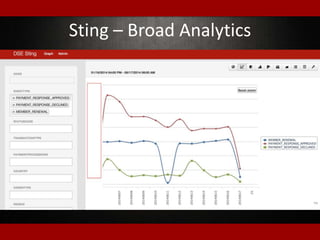
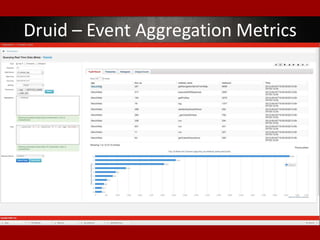
The document outlines presentations from a meetup on billing and payments engineering, highlighting challenges and strategies from various companies like Netflix, Dropbox, and SurveyMonkey. Key topics include validating payment information, flexible billing integrations, handling payment migrations, and optimizing global billing. Insights on building effective payment systems, managing data integrity, and the importance of dynamic feedback loops are also discussed.











































































