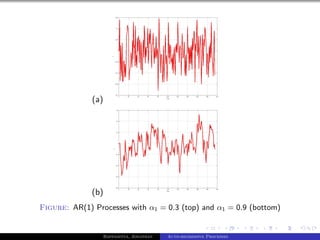
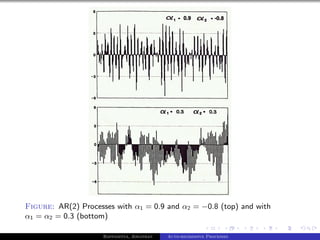
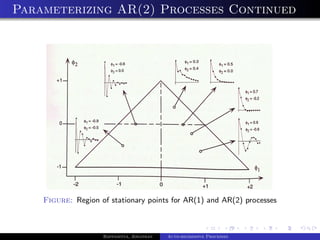
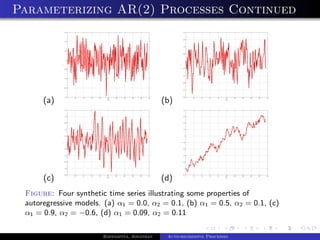
The document outlines auto-regressive (AR) processes of order p. It begins by introducing AR(p) processes formally and discussing white noise. It then derives the first and second moments of an AR(p) process. Specific details are provided about AR(1) and AR(2) processes, including equations for their variance as a function of the noise variance and AR coefficients. Examples of simulated AR(1) processes are shown for different coefficient values.












![AR(1) Processes Continued
Substituting for k = 1, in eqn. (8), yields
ε(Xt Xt−1 )
ρ1 = (19)
Var (Xt )
Hence ρ1 = α1
Using this we can write eqn. (13) for an AR(1) process as
Var(Zt )
Var(Xt ) = p
1− k=1 αk ρk
2
σz
= 2 (20)
1 − α1
This result shows that the variance of the random variable Xt is a linear
2
function of the variance of the white noise σZ . This also shows that the
variance is also a nonlinear function of α1 .
If α1 ≈ 0, then the Var (Xt ) ≈ Var (Zt ). For α1 ∈ [0, 1], we see that
Var (Xt ) > Var (Zt ). As α1 approaches 1, the Var (Xt ) approaches ∞.
Bappaditya, Jonathan Auto-regressive Processes](https://image.slidesharecdn.com/autoregression-130311154235-phpapp01/85/Autoregression-14-320.jpg)