Downloaded 131 times












![AS
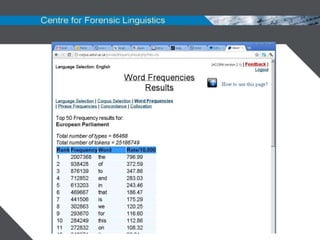
Function Examples
Start of time adjunct clause As we approached the small hut;
as I followed the masses
Fixed Phrase as [adj/adv] as As easily as; as soon as, as well as
AS + Noun Phrase as a museum; as the red-light district
AS at the start of a manner adjunct as you can imagine; as the locals do
AS could be replaced with because big push for the Chinese people to learn English, as
they have now made it mandatory in their schools
AS is used for comparison as if they knew we were on their turf;
still as a board;
the same as fall back in Chicago;](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-14-320.jpg)
![IT
Function Examples
IT serves as s dummy subject
IT + [to be] + predicament + infinitive It's hard to enjoy a festival the same way
IT + [to be] or other verb phrase (+ It turns out I'll be going to at least four
adj/noun phrase) + relative clause (that, if
etc.)
IT + [to be] + time reference it's time for Pendulum](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-15-320.jpg)
![IT (cont.)
Function Examples
IT + seem/feel/any other perception verb it stops feeling like Hannover
IT + [to be] + noun phrase it would have been a great day
IT refers to something mentioned before We woke up early to catch the ferry and it
couldn't have been easier.
IT is a part of a fixed phrase We made it to Macau in less than 2 hours](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-16-320.jpg)


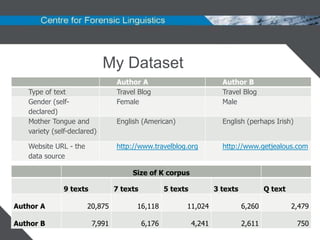




![T-Test: Success
Beyond Reasonable Doubt: 95% or more
Functi Function Clustering Discrimi
on nating
Word
A B
AS Start of time adjunct clause FAIL YES BRD NO BRD
Fixed Phrase as [adj/adv] as BRD FAIL FAIL YES BRD
AS + Noun Phrase FAIL BRD YES YES NO
AS at the start of a manner FAIL YES BRD N/A NO
adjunct
AS could be replaced with BRD BRD N/A N/A N/A
because
AS is used for comparison YES BRD BRD FAIL NO](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-24-320.jpg)





![References
NB: The references are from the original paper; some authors present in this
list may not have been cited in the presentation
Books and Journals
Argamon, S. & Levitan, S. (2005) Measuring the Usefulness of Function Words for Authorship
Attribution [Online]. Available at:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.71.6935&rep=rep1&type=pdf [Accessed
12 September 2010]
Burrows, J. (2003). Questions of Authorship: Attribution and Beyond. Computers and Humanities
[Online] 37, pp. 5-23. Available from: http://www.springerlink.com/content/nv46t75125472350/
[Accessed 1 August 2010].
Chaski, C. E. (1997). Who Wrote It? Steps Towards a Science of Authorship Identification. National
Institute of Justice Journal. (September Issue) [Online]. Available from:
http://www.ncjrs.gov/pdffiles/jr000233.pdf [Accessed 31 January 2010].
Chaski, C. E. (2001). Empirical evaluations of language-based author identification techniques. The
International Journal of Speech, Language and the Law [Online] 8 (1), pp. 1-65. Available from:
http://www.equinoxjournals.com/ojs/index.php/IJSLL/article/view/1690/1151 [Accessed 12 June
2008].
Chaski, C. E. (2005). Who‟s at the Keyboard? Authorship Attribution in Digital Evidence
Investigations. International Journal of Digital Evidence [Online] 4 (1), pp. 1-14. Available from:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.75.3852&rep=rep1&type=pdf [Accessed
31 January 2010].](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-31-320.jpg)
![Coulthard, M. (1998). Identifying the Author. Cahiers de Linguistique Française [Online] 20, pp. 139-
161. Available at: http://clf.unige.ch/display.php?idFichier=168 [Accessed 28 January 2010].
Coulthard, M. (2004). Author Identification, Idiolect and Linguistic Uniqueness. Applied Linguistics
[Online] 25 (4), pp. 431-447. Available at: http://www.business-
english.ch/downloads/Malcolm%20Coulthard/AppLing.art.final.pdf [Accessed 27 January 2010].
Coulthard, M. & Johnson, A. (2007). An Introduction to Forensic Linguistics: Language in Evidence.
Abingdon: Routledge.
De Vel, O. (2001). Multi-Topic E-mail Authorship Attribution Forensics. In: ACM Conference on
Computer Security – Workshop on data mining for security applications. November 8,
2001.Phildelphia, PA [Online]. Available at:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.19.9951&rep=rep1&type=pdf [Accessed
31 August 2010].
Grant, T. (2007). Quantifying Evidence in Forensic Authorship Analysis. The international Journal of
Speech, Language and the Law [Online] 14 (1), pp. 1-25. Available at:
http://www.equinoxjournals.com/IJSLL/article/view/3955/2428 [Accessed 12 July 2010].
Grant, T. (2008). Dr Tim Grant: How text-messaging slips can help catch murderers. The
Independent [Online]. (Last updated 9 September 2009). Available at:
http://www.independent.co.uk/opinion/commentators/dr-tim-grant-how-textmessaging-slips-can-
help-catch-murderers-923503.html [Accessed 11 September 2010].
Grant, T. D. (2010). Txt 4n6: idiolect free authorship analysis? In: Roultledge Handbook of Forensic
Lingusitics. Abingdon: Routledge
De Vel, O. (2001). Multi-Topic E-mail Authorship Attribution Forensics. In: ACM Conference on
Computer Security – Workshop on data mining for security applications. November 8,
2001.Phildelphia, PA [Online]. Available at:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.19.9951&rep=rep1&type=pdf [Accessed
31 August 2010].](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-32-320.jpg)
![De Vel, O. (2001). Multi-Topic E-mail Authorship Attribution Forensics. In: ACM Conference on
Computer Security – Workshop on data mining for security applications. November 8,
2001.Phildelphia, PA [Online]. Available at:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.19.9951&rep=rep1&type=pdf [Accessed
31 August 2010].
Grant, T. (2007). Quantifying Evidence in Forensic Authorship Analysis. The international Journal of
Speech, Language and the Law [Online] 14 (1), pp. 1-25. Available at:
http://www.equinoxjournals.com/IJSLL/article/view/3955/2428 [Accessed 12 July 2010].
Grant, T. (2008). Dr Tim Grant: How text-messaging slips can help catch murderers. The
Independent [Online]. (Last updated 9 September 2009). Available at:
http://www.independent.co.uk/opinion/commentators/dr-tim-grant-how-textmessaging-slips-can-
help-catch-murderers-923503.html [Accessed 11 September 2010].
Grant, T. D. (2010). Txt 4n6: idiolect free authorship analysis? In: Roultledge Handbook of Forensic
Lingusitics. Abingdon: Routledge
Grant, T. & Baker, K. (2001). Identifying reliable, valid markers of authorship: a response to Chaski.
The International Journal of Speech, Language and the Law [Online] 8 (1), pp. 66-79. Available at:
http://www.equinoxjournals.com/ojs/index.php/IJSLL/article/view/1691/1150 [Accessed 12 June
2008].
Holmes, D. I. & Forsyth, R. S. (1995). The Federalist Revisited: New Directions in Authorship
Attribution. Literary and Linguistic Computing [Online] 10 (2), pp. 111-127. Available from:
http://llc.oxfordjournals.org/cgi/reprint/10/2/111 [Accessed 1 August 2010] .
Hunston, C. (2002). Corpora in Applied Linguistics. Cambridge: Cambridge University Press.
Mitchell, E. (2008). The Case for Forensic Linguisitcs. BBC News [Online]. (Last updates 8
September 2008). Available at: http://news.bbc.co.uk/1/hi/sci/tech/7600769.stm [Accessed 11
September 2010]](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-33-320.jpg)
![Rudman, J. (1998). The State of Authorship Attribution Studies: Some Problems and Solutions. Computers and
the Humanities [Online] 31, pp. 351–365. Available from:
http://www.springerlink.com/content/l023q7047388133x/fulltext.pdf
[Accessed 2 August 2010].
Websites:
Textstat
http://neon.niederlandistik.fu-berlin.de/textstat/
T-test Calculator
http://www.graphpad.com/quickcalcs/OneSampleT1.cfm
T-Tables
http://www.statsoft.com/textbook/distribution-tables/#t](https://image.slidesharecdn.com/authorshipanalysisusingfunctionwordsforensiclinguistics-111123044353-phpapp01/85/Authorship-analysis-using-function-words-forensic-linguistics-34-320.jpg)

This document summarizes a research paper on using statistical analysis of function words to analyze authorship in forensic linguistics. It discusses using t-tests to cluster texts by the same author and discriminate between authors based on frequency of words like "as", "it", "that", and "there". The summary found that t-tests were better at discrimination than clustering and that analysis broke down with shorter texts. It concludes that function word analysis may be a useful forensic linguistics tool but has limitations like being better for longer texts and requiring further analysis for shorter texts.























































































