



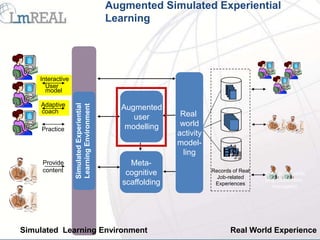
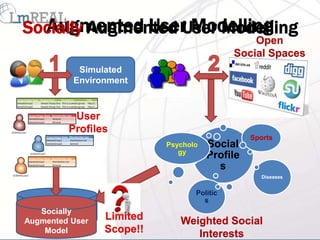

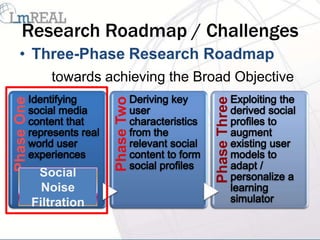
![YouTube Video Selection
• Selected as part of a research study by
[Despotakis, Lau & Dimitrova, 2011]
• Four Job Interview-related categories are
manually identified from video content
– Guides / Best Practices
– Interviewee’s Stories
– Interviewer’s Stories
– Interview Mock Examples
• Videos from all categories are selected to
retrieve the comment set for ML training](https://image.slidesharecdn.com/aumworkshoppaperpresentation-111109074502-phpapp02/85/Aum-workshop-paper_presentation-10-320.jpg)
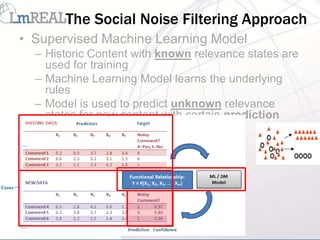
![Semantically Enriched Job Interview
Bag of Words
• A Semantically Enriched Job Interview Bag of Words (JIBoW)
used as Novel Means to Score and Label Training YouTube
Comment Set
• Collection of Textual Comments on Job Interview Videos [*]
– Experimentally controlled
– Closed social space
• Text and Semantic Pre-Processing Phases
• Semantically Expanded by the WordNet Lexicon and DISCO
with Word Synonyms, Antonyms, Derivations, and
semantically similar words
[*] Despotakis, Lau, Dimitrova (2011): A Semantic
Approach to Extract Individual Viewpoints from User
Comments on An Activity, AUM Workshop, UMAP
2011, Girona, Spain](https://image.slidesharecdn.com/aumworkshoppaperpresentation-111109074502-phpapp02/85/Aum-workshop-paper_presentation-12-320.jpg)









The document describes a machine learning approach to filter YouTube comments for socially augmented user models. It presents a semantically enriched machine learning method that uses a job interview bag of words to score and label training comments from YouTube videos about job interviews. The trained classifiers are then used to predict whether new comments are relevant or noise. Experimental results show the classifiers perform well, and a human evaluation finds the service effectively identifies comments showing awareness or interest in job interviews.





![Teaching and learning_strategies_rev2[1]](https://cdn.slidesharecdn.com/ss_thumbnails/teachingandlearningstrategiesrev21-100529231403-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































































