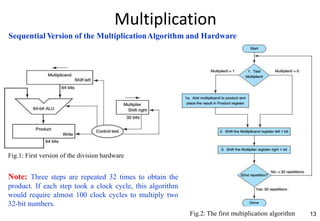
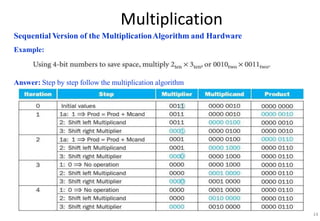
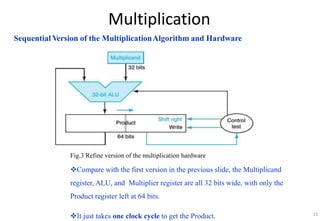
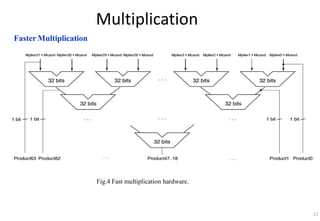
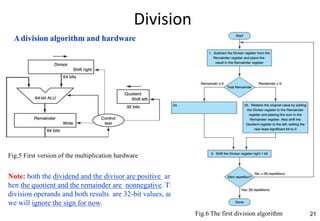
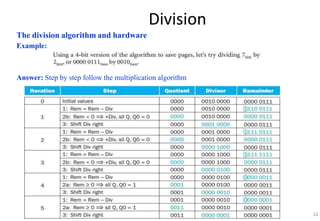
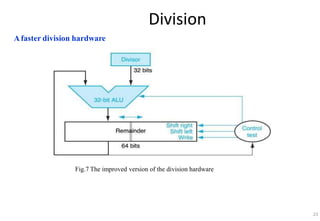
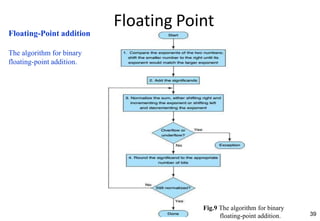
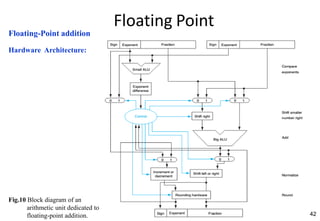
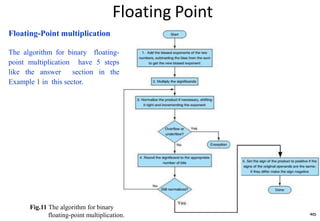
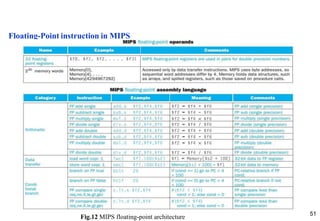
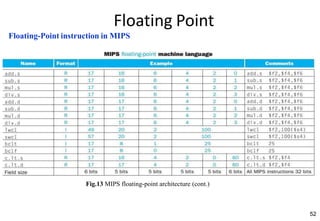
This document provides an overview of computer arithmetic concepts including addition, subtraction, multiplication, division, and floating point numbers. It discusses how each operation is performed at the bit level in computer hardware and presents algorithms and examples. Key topics covered include binary addition and subtraction, detecting overflow, sequential and optimized multiplication algorithms, division algorithms, and single and double precision floating point number formats and representations specified by the IEEE 754 standard.