Downloaded 19 times



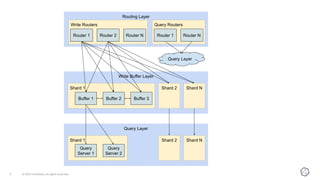
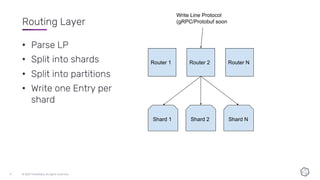
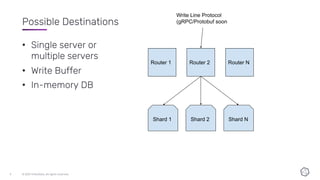

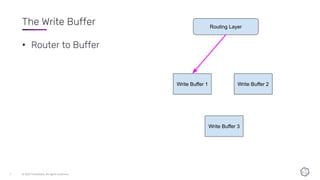
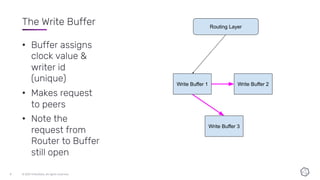
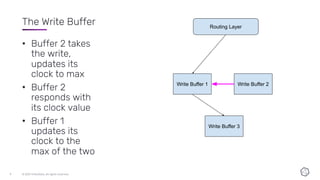
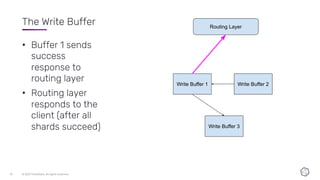
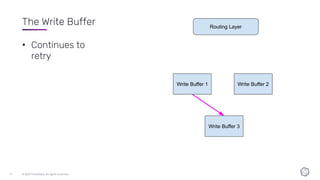
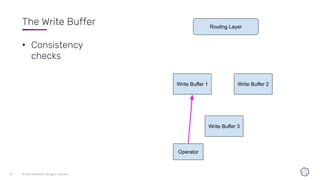
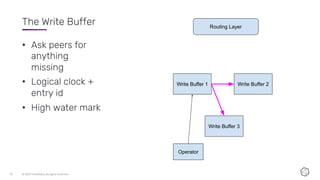
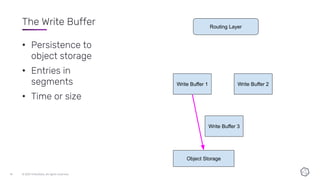
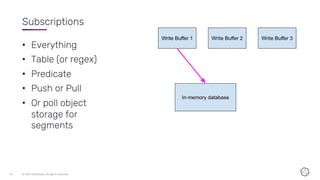
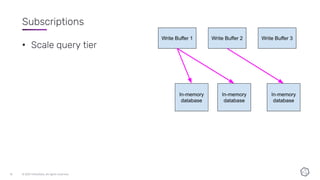
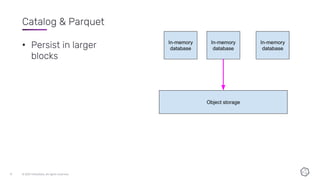
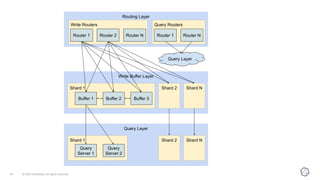


This document discusses the components and architecture of InfluxDB IOx for replication, durability, and subscriptions. It describes the write buffer, how writes are routed and distributed across shards, replication between buffers to ensure durability, and how subscriptions are handled for querying data.




























![Paul Dix [InfluxData] | InfluxDays Opening Keynote | InfluxDays EMEA 2021](https://cdn.slidesharecdn.com/ss_thumbnails/pauldixslides-final-210517163701-thumbnail.jpg?width=640&height=640&fit=bounds)
![Phil Bracikowski [InfluxData] | InfluxDB Cloud Durability Walkthrough | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/dem12storagedemodemophilbracikowski-221020205735-181435a9-thumbnail.jpg?width=640&height=640&fit=bounds)
![Paul Dix [InfluxData] | InfluxDays Opening Keynote | InfluxDays Virtual Exper...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-11-10influxdays-introducinginfluxdbiox-201110182839-thumbnail.jpg?width=640&height=640&fit=bounds)




![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)
![Brian Gilmore [InfluxData] | InfluxDB Storage Overview | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/dem15storageoverviewbriangilmorereviewed-221020210243-9f3d5a6e-thumbnail.jpg?width=640&height=640&fit=bounds)














![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)
![Jay Clifford [InfluxData] | Tips & Tricks for Analyzing IIoT in Real-Time | I...](https://cdn.slidesharecdn.com/ss_thumbnails/newdem21tipsandtricksforanalyzingiiotinrealtimejayclifford-221020213303-a3258e00-thumbnail.jpg?width=640&height=640&fit=bounds)



















