Downloaded 35 times


















![22© Cloudera, Inc. All rights reserved.
ETL with Table API
• Read the dirty JSON
• SQL style queries (SQL coming in Flink 1.1)
val env = ExecutionEnvironment.getExecutionEnvironment
val transactions = env.readTextFile(json).map(new FlinkTransaction(_))
val table = transactions.map(toCaseClass(_)).toTable
val storeTransactionCount = table.groupBy('storeId)
.select('storeId, 'storeName, 'storeId.count as 'count)
val bestStores = table.groupBy('storeId)
.select('storeId.max as 'max)
.join(storeTransactionCount)
.where(”count = max”)
.select('storeId, 'storeName, 'storeId.count as 'count)
.toDataSet[StoreCount]](https://image.slidesharecdn.com/flinkbigtop-160720165915/85/The-Flink-Apache-Bigtop-integration-22-320.jpg)
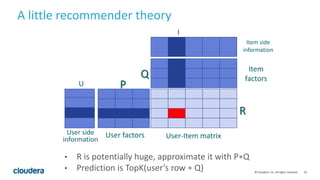

.map(pair => (pair._1, pair._2, 1.0))
val model = ALS()
.setNumfactors(numFactors)
.setIterations(iterations)
.setLambda(lambda)
model.fit(input)
val (p, q) = model.factorsOption.get
p.writeAsText(pOut)
q.writeAsText(qOut)](https://image.slidesharecdn.com/flinkbigtop-160720165915/85/The-Flink-Apache-Bigtop-integration-24-320.jpg)



![29© Cloudera, Inc. All rights reserved.
Next steps – Flink operations
• Flink does not offer a HistoryServer yet
Running on YARN is inconvenient like this
Follow [FLINK-4136] for resulotion
• The stand-alone cluster mode runs multiple jobs in the JVM
In practice users fire up clusters per job
Alibaba has a multitenant fork, aim is to contribute
https://www.youtube.com/watch?v=_Nw8NTdIq9A](https://image.slidesharecdn.com/flinkbigtop-160720165915/85/The-Flink-Apache-Bigtop-integration-29-320.jpg)







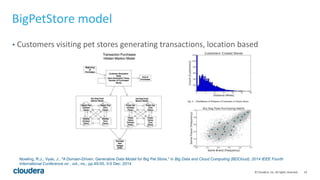
The document discusses integrating Apache Flink with Apache Bigtop to provide packaged Flink binaries. It describes Bigtop's role in standardizing packaging of big data components, and how it builds Flink from source and creates Linux packages. An example application called BigPetStore is implemented using Flink APIs and packaged with Bigtop. Finally, it outlines converting the Bigtop packages to Cloudera parcels for management by Cloudera Manager.















![[OpenStack Day in Korea 2015] Track 3-1 - OpenStack Storage Infrastructure & ...](https://cdn.slidesharecdn.com/ss_thumbnails/31-150213065505-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[OpenStack Day in Korea] Keynote#2 - Bringing OpenStack to the Enterprise Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/koreaopenstackdubuque20140218r7-140218091223-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































