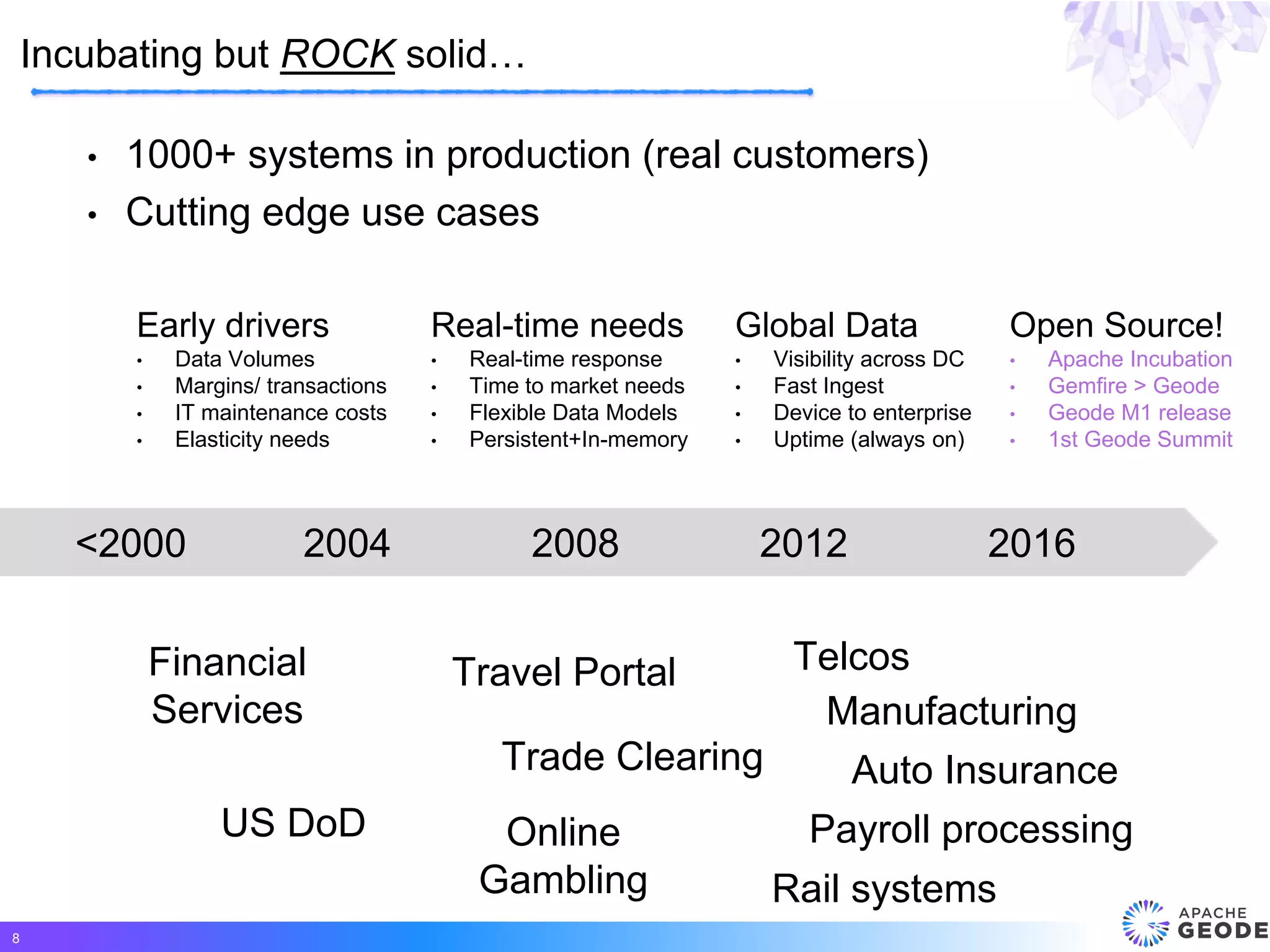
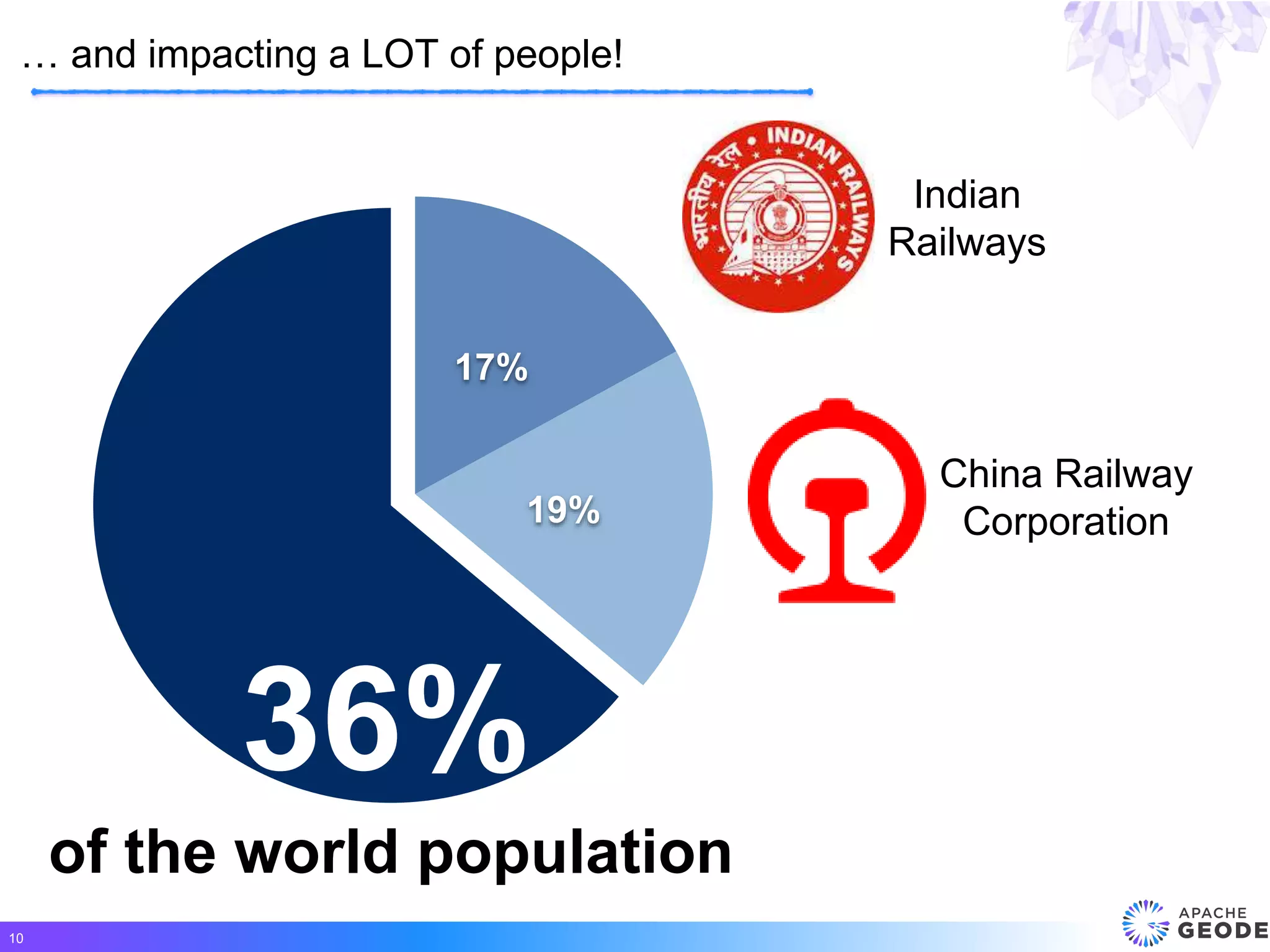
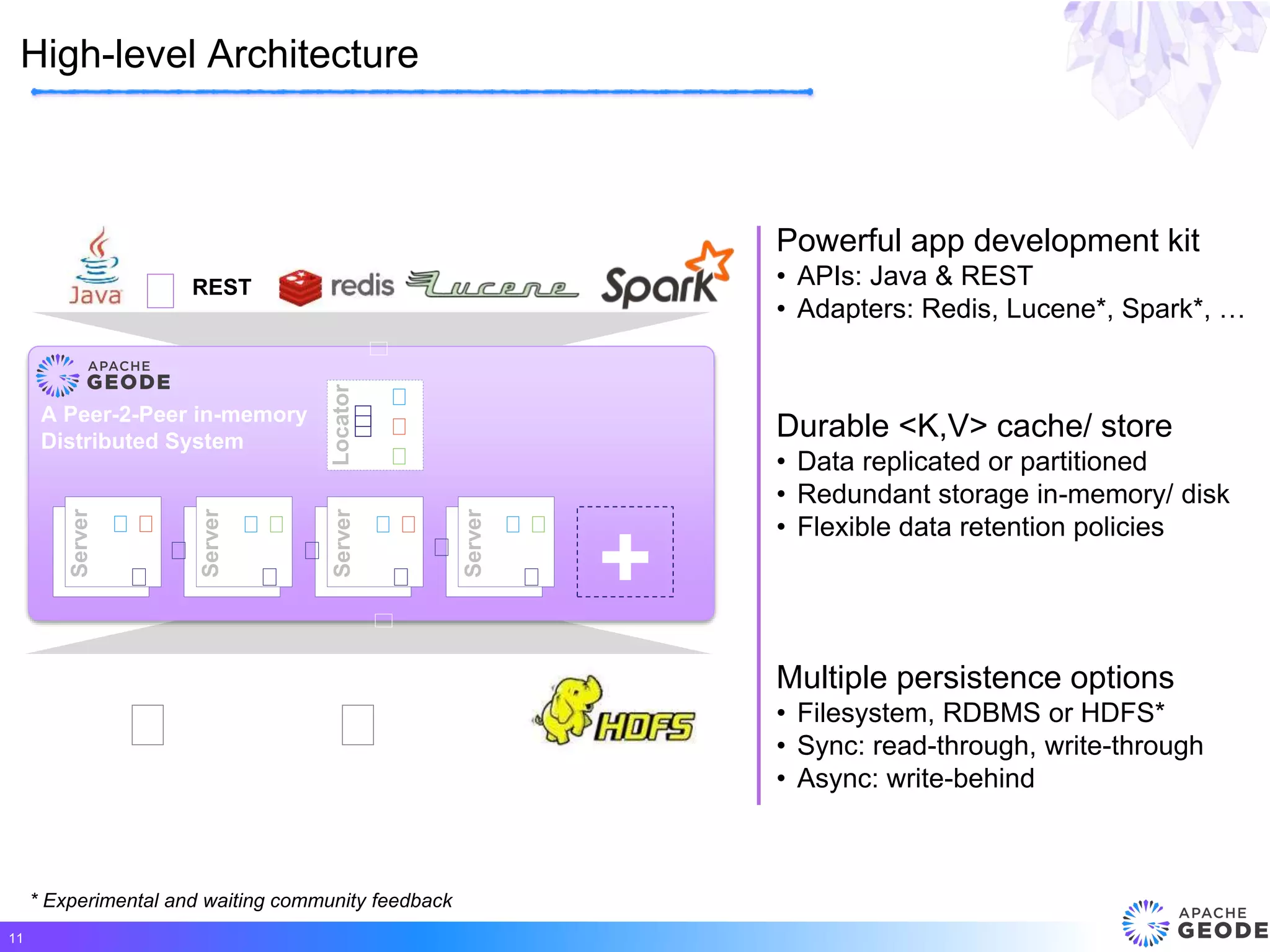
Apache Geode is a distributed, memory-based data management platform that provides high performance, scalability, resiliency and continuous availability for data-oriented applications. It originated from Pivotal's open sourcing of Gemfire in 2015. Some key features of Geode include fast access to critical datasets, location-aware distributed data processing, and an event-driven data architecture. It has been used in many large-scale production systems and sees adoption rates increasing.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















