Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
MY
Uploaded by
Masaki Yamakawa
PDF, PPTX
3,892 views
超高速処理とスケーラビリティを両立するApache GEODE
Apache GEODE Meetup Tokyo #1 の資料です。
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 32
2
/ 32
3
/ 32
4
/ 32
5
/ 32
6
/ 32
7
/ 32
8
/ 32
9
/ 32
10
/ 32
11
/ 32
12
/ 32
13
/ 32
14
/ 32
15
/ 32
16
/ 32
17
/ 32
18
/ 32
19
/ 32
20
/ 32
21
/ 32
22
/ 32
23
/ 32
24
/ 32
25
/ 32
26
/ 32
27
/ 32
28
/ 32
29
/ 32
30
/ 32
31
/ 32
32
/ 32
More Related Content
PDF
インメモリーで超高速処理を実現する場合のカギ
by
Masaki Yamakawa
PDF
「スキルなし・実績なし」 32歳窓際エンジニアがシリコンバレーで働くようになるまで
by
Shuichi Tsutsumi
PDF
How to run P4 BMv2
by
Kentaro Ebisawa
PDF
Zabbix最新情報 ~Zabbix 6.0に向けて~ @OSC2021 Online/Fall
by
Atsushi Tanaka
PDF
まずやっとくPostgreSQLチューニング
by
Kosuke Kida
PDF
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
PDF
ネットワークOS野郎 ~ インフラ野郎Night 20160414
by
Kentaro Ebisawa
PPTX
Redisの特徴と活用方法について
by
Yuji Otani
インメモリーで超高速処理を実現する場合のカギ
by
Masaki Yamakawa
「スキルなし・実績なし」 32歳窓際エンジニアがシリコンバレーで働くようになるまで
by
Shuichi Tsutsumi
How to run P4 BMv2
by
Kentaro Ebisawa
Zabbix最新情報 ~Zabbix 6.0に向けて~ @OSC2021 Online/Fall
by
Atsushi Tanaka
まずやっとくPostgreSQLチューニング
by
Kosuke Kida
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
ネットワークOS野郎 ~ インフラ野郎Night 20160414
by
Kentaro Ebisawa
Redisの特徴と活用方法について
by
Yuji Otani
What's hot
PDF
GKE に飛んでくるトラフィックを 自由自在に操る力 | 第 10 回 Google Cloud INSIDE Games & Apps Online
by
Google Cloud Platform - Japan
PDF
Vacuum徹底解説
by
Masahiko Sawada
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
PDF
無料で仮想Junos環境を手元に作ろう
by
akira6592
PDF
OpenLineage による Airflow のデータ来歴の収集と可視化(Airflow Meetup Tokyo #3 発表資料)
by
NTT DATA Technology & Innovation
PPTX
〜Apache Geode 入門 gfsh によるクラスター構築・管理
by
Akihiro Kitada
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PDF
Ingressの概要とLoadBalancerとの比較
by
Mei Nakamura
PDF
MySQL 5.7にやられないためにおぼえておいてほしいこと
by
yoku0825
PPTX
DockerコンテナでGitを使う
by
Kazuhiro Suga
PDF
マスターデータの キャッシュシステムの改善の話
by
natsumi_ishizaka
PPTX
DXとかDevOpsとかのなんかいい感じのやつ 富士通TechLive
by
Tokoroten Nakayama
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PDF
Mavenの真実とウソ
by
Yoshitaka Kawashima
PDF
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
PDF
"SRv6の現状と展望" ENOG53@上越
by
Kentaro Ebisawa
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PDF
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
GKE に飛んでくるトラフィックを 自由自在に操る力 | 第 10 回 Google Cloud INSIDE Games & Apps Online
by
Google Cloud Platform - Japan
Vacuum徹底解説
by
Masahiko Sawada
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
無料で仮想Junos環境を手元に作ろう
by
akira6592
OpenLineage による Airflow のデータ来歴の収集と可視化(Airflow Meetup Tokyo #3 発表資料)
by
NTT DATA Technology & Innovation
〜Apache Geode 入門 gfsh によるクラスター構築・管理
by
Akihiro Kitada
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
Ingressの概要とLoadBalancerとの比較
by
Mei Nakamura
MySQL 5.7にやられないためにおぼえておいてほしいこと
by
yoku0825
DockerコンテナでGitを使う
by
Kazuhiro Suga
マスターデータの キャッシュシステムの改善の話
by
natsumi_ishizaka
DXとかDevOpsとかのなんかいい感じのやつ 富士通TechLive
by
Tokoroten Nakayama
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
分散システムについて語らせてくれ
by
Kumazaki Hiroki
Mavenの真実とウソ
by
Yoshitaka Kawashima
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
"SRv6の現状と展望" ENOG53@上越
by
Kentaro Ebisawa
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
Viewers also liked
PPTX
Apache Geode で始める Spring Data Gemfire
by
Akihiro Kitada
PDF
インメモリーデータグリッドの選択肢
by
Masaki Yamakawa
PDF
Geode hands-on
by
Masaki Yamakawa
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PPTX
Coherenceを利用するときに気をつけること #OracleCoherence
by
Toshiaki Maki
PDF
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
PDF
Geode meetup 20160609
by
Tomohiro Ichimura
PDF
Infinispan - Open Source Data Grid
by
nekop
PDF
SnappyData Overview Slidedeck for Big Data Bellevue
by
SnappyData
PPTX
GemFire In Memory Data Grid
by
Dmitry Buzdin
PDF
Spark Summit EU 2015: SparkUI visualization: a lens into your application
by
Databricks
PPTX
Advanced Visualization of Spark jobs
by
DataWorks Summit/Hadoop Summit
PDF
Riak: 本物の高可用性を実現する仕組みとは?
by
Takahiko Sato
PDF
The future of data by Doug Cutting #hcj2014
by
Cloudera Japan
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
OLAP with Cassandra and Spark
by
Evan Chan
PDF
週刊Azureなう Igniteキャッチアップ編
by
Naoki (Neo) SATO
PDF
[D35] インメモリーデータベース徹底比較 by Komori
by
Insight Technology, Inc.
PPTX
SnappyData, the Spark Database. A unified cluster for streaming, transactions...
by
SnappyData
PDF
因果推論の基礎
by
Hatsuru Morita
Apache Geode で始める Spring Data Gemfire
by
Akihiro Kitada
インメモリーデータグリッドの選択肢
by
Masaki Yamakawa
Geode hands-on
by
Masaki Yamakawa
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
Coherenceを利用するときに気をつけること #OracleCoherence
by
Toshiaki Maki
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
Geode meetup 20160609
by
Tomohiro Ichimura
Infinispan - Open Source Data Grid
by
nekop
SnappyData Overview Slidedeck for Big Data Bellevue
by
SnappyData
GemFire In Memory Data Grid
by
Dmitry Buzdin
Spark Summit EU 2015: SparkUI visualization: a lens into your application
by
Databricks
Advanced Visualization of Spark jobs
by
DataWorks Summit/Hadoop Summit
Riak: 本物の高可用性を実現する仕組みとは?
by
Takahiko Sato
The future of data by Doug Cutting #hcj2014
by
Cloudera Japan
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
OLAP with Cassandra and Spark
by
Evan Chan
週刊Azureなう Igniteキャッチアップ編
by
Naoki (Neo) SATO
[D35] インメモリーデータベース徹底比較 by Komori
by
Insight Technology, Inc.
SnappyData, the Spark Database. A unified cluster for streaming, transactions...
by
SnappyData
因果推論の基礎
by
Hatsuru Morita
Similar to 超高速処理とスケーラビリティを両立するApache GEODE
PPTX
Graph DB のユニークさについて考えてみた
by
Yuki Tagami
PPTX
Graph DB のユニークさについて考えてみた
by
Yuki Tagami
PDF
【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]
by
Hideo Takagi
PDF
MapReduce解説
by
Shunsuke Aihara
PDF
Guide to Cassandra for Production Deployments
by
smdkk
PDF
オンライン広告入札システムとZGC ( JJUG CCC 2021 Spring )
by
Hironobu Isoda
PPTX
Geode+Alpakka+Akka Streamsでリアルタイムデータ処理
by
Shogo Ajina
PDF
Azure Antenna はじめての Azure Data Lake
by
Hideo Takagi
PPTX
Pgxユーザー勉強会#5 パスクエリを使ったトラバース
by
Yuki Tagami
PDF
Tohnaka Giri Ninjo Programmer Tohnaka at AgileJpan 2011
by
Akiko Kosaka
PDF
Tohnaka Giri Ninjo Programmer Tohnaka at AgileJpan 2011
by
Kenji Hiranabe
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
PDF
PostgreSQLではじめるOSS開発@OSC 2014 Hiroshima
by
Shigeru Hanada
PDF
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
PDF
InfluxDB の概要 - sonots #tokyoinfluxdb
by
Naotoshi Seo
PPT
Transactional Information Systems入門
by
nobu_k
PDF
アナリティクスをPostgreSQLで始めるべき10の理由@第6回 関西DB勉強会
by
Satoshi Nagayasu
PPT
S4
by
あしたのオープンソース研究所
PDF
20110517 okuyama ソーシャルメディアが育てた技術勉強会
by
Takahiro Iwase
PDF
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
Graph DB のユニークさについて考えてみた
by
Yuki Tagami
Graph DB のユニークさについて考えてみた
by
Yuki Tagami
【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]
by
Hideo Takagi
MapReduce解説
by
Shunsuke Aihara
Guide to Cassandra for Production Deployments
by
smdkk
オンライン広告入札システムとZGC ( JJUG CCC 2021 Spring )
by
Hironobu Isoda
Geode+Alpakka+Akka Streamsでリアルタイムデータ処理
by
Shogo Ajina
Azure Antenna はじめての Azure Data Lake
by
Hideo Takagi
Pgxユーザー勉強会#5 パスクエリを使ったトラバース
by
Yuki Tagami
Tohnaka Giri Ninjo Programmer Tohnaka at AgileJpan 2011
by
Akiko Kosaka
Tohnaka Giri Ninjo Programmer Tohnaka at AgileJpan 2011
by
Kenji Hiranabe
Facebookのリアルタイム Big Data 処理
by
maruyama097
PostgreSQLではじめるOSS開発@OSC 2014 Hiroshima
by
Shigeru Hanada
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
InfluxDB の概要 - sonots #tokyoinfluxdb
by
Naotoshi Seo
Transactional Information Systems入門
by
nobu_k
アナリティクスをPostgreSQLで始めるべき10の理由@第6回 関西DB勉強会
by
Satoshi Nagayasu
S4
by
あしたのオープンソース研究所
20110517 okuyama ソーシャルメディアが育てた技術勉強会
by
Takahiro Iwase
あなたが知らない リレーショナルモデル
by
Mikiya Okuno
More from Masaki Yamakawa
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
20250826_Devinで切り拓く沖縄ITの未来_AI駆動開発勉強会 沖縄支部 第2回
by
Masaki Yamakawa
PDF
20250729_Devin-for-Enterprise
by
Masaki Yamakawa
PDF
20250726_Devinで変えるエンプラシステム開発の未来
by
Masaki Yamakawa
PDF
20250717_Devin×GitHubCopilotで10人分の仕事は出来るのか?
by
Masaki Yamakawa
PDF
20250710_Devinで切り拓くDB革命_〜価値創出に集中せよ〜
by
Masaki Yamakawa
PDF
20250611_話題のDevin、エンプラ開発で〇人分の仕事はできるのか !?
by
Masaki Yamakawa
PDF
20231111_YugabyteDB-on-k8s.pdf
by
Masaki Yamakawa
PDF
20221117_クラウドネイティブ向けYugabyteDB活用シナリオ
by
Masaki Yamakawa
PDF
20220331_DSSA_MigrationToYugabyteDB
by
Masaki Yamakawa
PDF
20211118 dbts2021 マイクロサービスにおけるApache Geodeの効果的な使い方
by
Masaki Yamakawa
PDF
20190523 IMC meetup-IMDG&DS
by
Masaki Yamakawa
PDF
20181031 springfest spring data geode
by
Masaki Yamakawa
PDF
Apache geode at-s1p
by
Masaki Yamakawa
PDF
20180217 hackertackle geode
by
Masaki Yamakawa
PDF
20171125 springfest snappydata
by
Masaki Yamakawa
PDF
20171118 jjug snappydata
by
Masaki Yamakawa
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
20250826_Devinで切り拓く沖縄ITの未来_AI駆動開発勉強会 沖縄支部 第2回
by
Masaki Yamakawa
20250729_Devin-for-Enterprise
by
Masaki Yamakawa
20250726_Devinで変えるエンプラシステム開発の未来
by
Masaki Yamakawa
20250717_Devin×GitHubCopilotで10人分の仕事は出来るのか?
by
Masaki Yamakawa
20250710_Devinで切り拓くDB革命_〜価値創出に集中せよ〜
by
Masaki Yamakawa
20250611_話題のDevin、エンプラ開発で〇人分の仕事はできるのか !?
by
Masaki Yamakawa
20231111_YugabyteDB-on-k8s.pdf
by
Masaki Yamakawa
20221117_クラウドネイティブ向けYugabyteDB活用シナリオ
by
Masaki Yamakawa
20220331_DSSA_MigrationToYugabyteDB
by
Masaki Yamakawa
20211118 dbts2021 マイクロサービスにおけるApache Geodeの効果的な使い方
by
Masaki Yamakawa
20190523 IMC meetup-IMDG&DS
by
Masaki Yamakawa
20181031 springfest spring data geode
by
Masaki Yamakawa
Apache geode at-s1p
by
Masaki Yamakawa
20180217 hackertackle geode
by
Masaki Yamakawa
20171125 springfest snappydata
by
Masaki Yamakawa
20171118 jjug snappydata
by
Masaki Yamakawa
超高速処理とスケーラビリティを両立するApache GEODE
1.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by Apache GEODE Meetup Tokyo #1 超高速処理とスケーラビリティを両立するApache GEODE 2016/6/9 ウルシステムズ株式会社 http://www.ulsystems.co.jp mailto:info@ulsystems.co.jp Tel: 03-6220-1420 Fax: 03-6220-1402
2.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 1 About Me 山河 征紀 Business Private • GEODE歴:9年(Since 2008) • GEODEバグ報告数:nnn 件 • ランナー • 横浜マラソン2016:4h17m • 目標は今年中のサブ4 • アルピニスト • 目標はココ
3.
ULS 2 Copyright ©
2011-2013 UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 超高速処理とスケーラビリティを 両立するApache GEODE
4.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 3 Apache GEODEとは ざっくりいうとインメモリーの分散KVS –データを各マシンのメモリーに分散配置 –大量トランザクションに対する高速処理 –動的なスケーラビリティ –ミッションクリティカルでの利用 採用実績 –欧米の金融機関 –政府、防衛
5.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 4 近年様々なデータストアが誕生 選択肢は多種多様に NoSQL In-Memory DataGrid In-Memory Cache Traditional Database Columnar Database
6.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 5 日本はRDB命
7.
ULS Copyright © 2011-2016
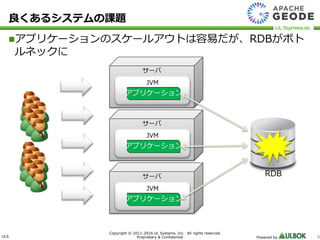
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 6 サーバ サーバ サーバ アプリケーションのスケールアウトは容易だが、RDBがボト ルネックに 良くあるシステムの課題 JVM JVM JVM アプリケーション アプリケーション アプリケーション RDB
8.
ULS Copyright © 2011-2016
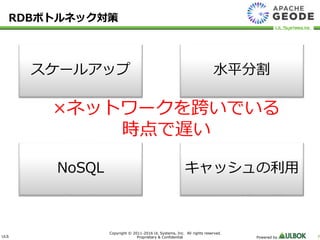
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 7 RDBボトルネック対策 スケールアップ 水平分割 NoSQL キャッシュの利用 ×ネットワークを跨いでいる 時点で遅い
9.
ULS Copyright © 2011-2016
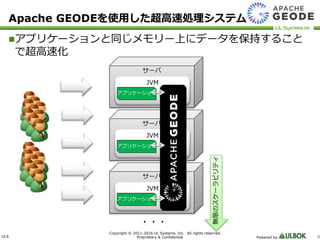
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 8 アプリケーションと同じメモリー上にデータを保持すること で超高速化 Apache GEODEを使用した超高速処理システム サーバ サーバ サーバ JVM JVM JVM アプリケーション アプリケーション アプリケーション ・・・ 無限のスケーラビリティ
10.
ULS Copyright © 2011-2016
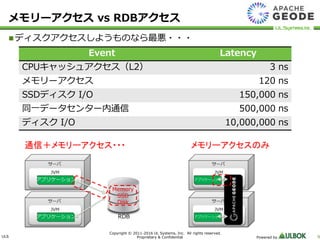
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 9 メモリーアクセス vs RDBアクセス ディスクアクセスしようものなら最悪・・・ Event Latency CPUキャッシュアクセス(L2) 3 ns メモリーアクセス 120 ns SSDディスク I/O 150,000 ns 同一データセンター内通信 500,000 ns ディスク I/O 10,000,000 ns メモリーアクセスのみ通信+メモリーアクセス・・・ Memory SSD Disk
11.
ULS Copyright © 2011-2016
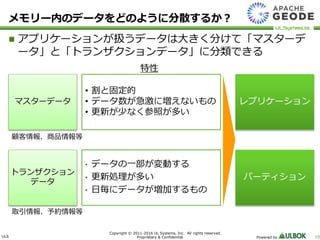
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 10 メモリー内のデータをどのように分散するか? アプリケーションが扱うデータは大きく分けて「マスターデ ータ」と「トランザクションデータ」に分類できる マスターデータ トランザクション データ • 割と固定的 • データ数が急激に増えないもの • 更新が少なく参照が多い • データの一部が変動する • 更新処理が多い • 日毎にデータが増加するもの 特性 顧客情報、商品情報等 取引情報、予約情報等 レプリケーション パーティション
12.
ULS Copyright © 2011-2016
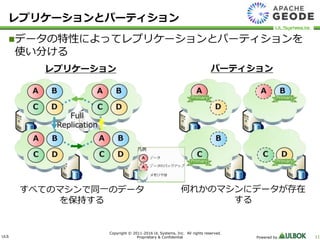
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 11 レプリケーションとパーティション データの特性によってレプリケーションとパーティションを 使い分ける パーティションレプリケーション すべてのマシンで同一のデータ を保持する 何れかのマシンにデータが存在 する
13.
ULS Copyright © 2011-2016
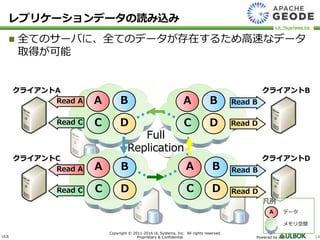
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 14 全てのサーバに、全てのデータが存在するため高速なデータ 取得が可能 レプリケーションデータの読み込み Full Replication クライアントA クライアントC クライアントB クライアントD A B C A B D A C D B C D Read A Read C Read A Read C Read B Read D Read B Read D D C B A 凡例 A データ メモリ空間
14.
ULS Copyright © 2011-2016
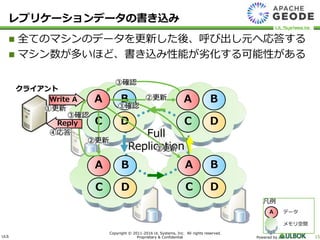
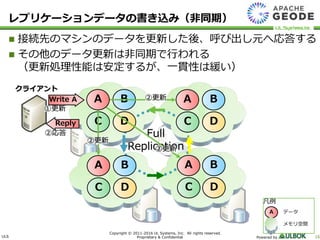
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 15 全てのマシンのデータを更新した後、呼び出し元へ応答する マシン数が多いほど、書き込み性能が劣化する可能性がある Full Replication クライアント A B C A B D A C D B C D Write A D C B A ②更新 ①更新 ②更新 ②更新 ③確認 ③確認 ③確認 Reply ④応答 レプリケーションデータの書き込み 凡例 A データ メモリ空間
15.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 16 接続先のマシンのデータを更新した後、呼び出し元へ応答する その他のデータ更新は非同期で行われる (更新処理性能は安定するが、一貫性は緩い) Full Replication クライアント A B C A B D A C D B C D Write A D C B A ②更新 ①更新 ②更新 ②更新 Reply ②応答 レプリケーションデータの書き込み(非同期) 凡例 A データ メモリ空間
16.
ULS Copyright © 2011-2016
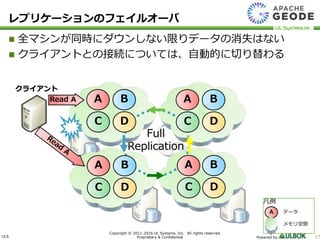
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 17 全マシンが同時にダウンしない限りデータの消失はない クライアントとの接続については、自動的に切り替わる Full Replication クライアント A B C A B D A C D B C D Read A D C B A レプリケーションのフェイルオーバ 凡例 A データ メモリ空間
17.
ULS Copyright © 2011-2016
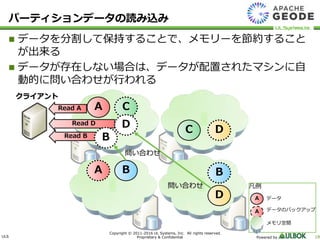
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 18 データを分割して保持することで、メモリーを節約すること が出来る データが存在しない場合は、データが配置されたマシンに自 動的に問い合わせが行われる クライアント A C B Read A D Read B B C A D パーティションデータの読み込み 凡例 A A データ データのバックアップ メモリ空間 Read D B D 問い合わせ 問い合わせ
18.
ULS Copyright © 2011-2016
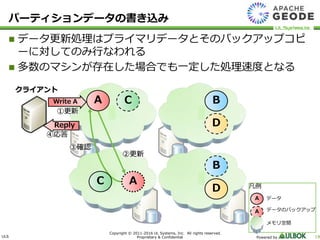
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 19 データ更新処理はプライマリデータとそのバックアップコピ ーに対してのみ行なわれる 多数のマシンが存在した場合でも一定した処理速度となる クライアント AWrite A ②更新 A ①更新 ③確認 Reply ④応答 B C D D B C パーティションデータの書き込み 凡例 A A データ データのバックアップ メモリ空間
19.
ULS Copyright © 2011-2016
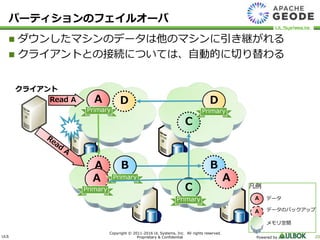
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 20 ダウンしたマシンのデータは他のマシンに引き継がれる クライアントとの接続については、自動的に切り替わる クライアント D A B C Read A C B DA A Primary Primary Primary Primary Primary A パーティションのフェイルオーバ 凡例 A A データ データのバックアップ メモリ空間
20.
ULS Copyright © 2011-2016
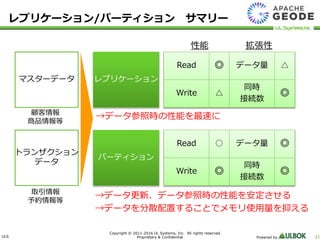
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 21 レプリケーション/パーティション サマリー マスターデータ トランザクション データ レプリケーション パーティション 顧客情報 商品情報等 取引情報 予約情報等 →データ参照時の性能を最速に →データ更新、データ参照時の性能を安定させる →データを分散配置することでメモリ使用量を抑える Read ○ データ量 ◎ Write ◎ 同時 接続数 ◎ Read ◎ データ量 △ Write △ 同時 接続数 ◎ 性能 拡張性
21.
ULS Copyright © 2011-2016
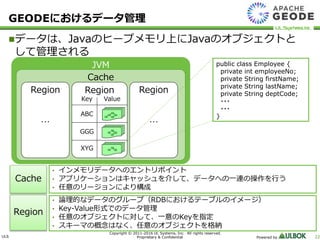
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 22 データは、Javaのヒープメモリ上にJavaのオブジェクトと して管理される GEODEにおけるデータ管理 JVM Cache Region Key Value ABC GGG XYG Region … Region … • インメモリデータへのエントリポイント • アプリケーションはキャッシュを介して、データへの一連の操作を行う • 任意のリージョンにより構成 • 論理的なデータのグループ(RDBにおけるテーブルのイメージ) • Key-Value形式でのデータ管理 • 任意のオブジェクトに対して、一意のKeyを指定 • スキーマの概念はなく、任意のオブジェクトを格納 Cache Region public class Employee { private int employeeNo; private String firstName; private String lastName; private String deptCode; ・・・ ・・・ }
22.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 23 Region定義方法 XMLでRegionを定義 <cache> <region name=“replicateRegion"> <region-attributes refid=“REPLICATE“ /> </region> <region name=“partitionRegion"> <region-attributes refid=“PARTITION“ /> </region> </cache>
23.
ULS Copyright © 2011-2016
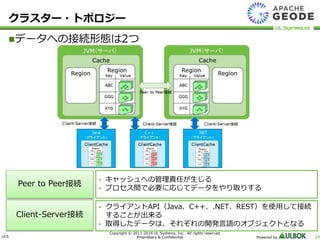
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 24 データへの接続形態は2つ クラスター・トポロジー • キャッシュへの管理責任が生じる • プロセス間で必要に応じてデータをやり取りする • クライアントAPI(Java、C++、.NET、REST)を使用して接続 することが出来る • 取得したデータは、それぞれの開発言語のオブジェクトとなる Peer to Peer接続 Client-Server接続
24.
ULS Copyright © 2011-2016
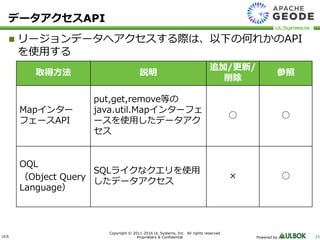
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 25 リージョンデータへアクセスする際は、以下の何れかのAPI を使用する データアクセスAPI 取得方法 説明 追加/更新/ 削除 参照 Mapインター フェースAPI put,get,remove等の java.util.Mapインターフェ ースを使用したデータアク セス ○ ○ OQL (Object Query Language) SQLライクなクエリを使用 したデータアクセス × ○
25.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 26 MapインターフェースAPI Java.util.Map感覚でKeyを指定してデータへアクセス // XMLを指定してCacheを取得 Cache cache = new CacheFactory() .set("cache-xml-file", “cache.xml").create(); // CacheよりexampleRegionを取得 Region<Integer, String> region = cache.getRegion(“exampleRegion"); Integer key = 1; // データ登録 region.put(key, message); // データ取得 String value = region.get(key, message); // データ削除 region.remove(key);
26.
ULS Copyright © 2011-2016
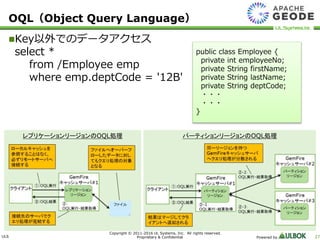
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 27 OQL(Object Query Language) Key以外でのデータアクセス select * from /Employee emp where emp.deptCode = '12B' public class Employee { private int employeeNo; private String firstName; private String lastName; private String deptCode; ・・・ ・・・ } パーティションリージョンのOQL処理レプリケーションリージョンのOQL処理
27.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 28 OQLの実装 OQL専用のクラスを使用してクエリー実行 // XMLを指定してCacheを取得 Cache cache = new CacheFactory().set("cache-xml-file", “cache.xml").create(); // CacheよりQueryService取得 QueryService queryService = cache.getQueryService(); // Query作成 Query query = queryService .newQuery("select * from /Employee emp where emp.deptCode='12B'"); // Query実行 SelectResults result = query.execute(); Collection<?> collection = ((SelectResults<?>)result).asList(); for (Object e: collection) { System.out.println(e); }
28.
ULS Copyright © 2011-2016
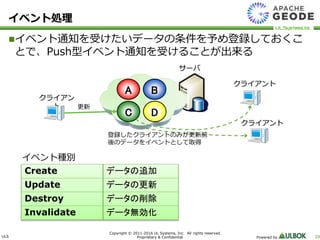
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 29 イベント処理 イベント通知を受けたいデータの条件を予め登録しておくこ とで、Push型イベント通知を受けることが出来る A B C D クライアン ト 更新 サーバ クライアント クライアント 登録したクライアントのみが更新前 後のデータをイベントとして取得 Create データの追加 Update データの更新 Destroy データの削除 Invalidate データ無効化 イベント種別
29.
ULS Copyright © 2011-2016
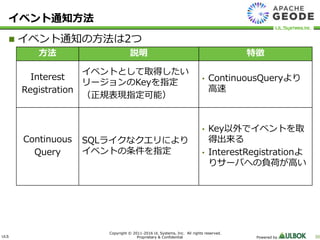
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 30 イベント通知の方法は2つ イベント通知方法 方法 説明 特徴 Interest Registration イベントとして取得したい リージョンのKeyを指定 (正規表現指定可能) • ContinuousQueryより 高速 Continuous Query SQLライクなクエリにより イベントの条件を指定 • Key以外でイベントを取 得出来る • InterestRegistrationよ りサーバへの負荷が高い
30.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 31 イベント処理の実装 XMLでイベント処理を行うクラスを設定 <cache> <region name=“exampleRegion"> <region-attributes refid=“PARTITION“ /> <cache-listener> <class-name>example.MyCacheListener</class-name> </cache-listener> </region> </cache>
31.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 32 イベント処理の実装 イベント処理では、イベント種別に応じたCacheListenerの コールバックメソッドが呼ばれる public class MyCacheListener implements CacheListener<String, String>, Declarable { @Override public void afterCreate(EntryEvent<String, String> event) { // KeyとValueを標準出力へ出力します System.out.println(event.getKey() + "> " + event.getNewValue()); } @Override public void afterUpdate(EntryEvent<String, String> event) { ・・・・ } @Override public void afterDestroy(EntryEvent<String, String> event) { ・・・・ } }
32.
ULS Copyright © 2011-2016
UL Systems, Inc. All rights reserved. Proprietary & Confidential Powered by 33 今後のテーマ ユースケース/事例GEODEハンズオン GEODE その他機能 正式リリースに向けた 追加機能 他の分散処理製品 との違い GEODEの インテグレーション
Editor's Notes
#5
【概念的な背景】 データが増える Txが増える → パフォーマンス求められる スケールアウトが重要
#8
・DBの方もキャッシュぐらいかいとく ・キャッシュや分散DBでもN/W超えるよね ・O/Rマッピングの処理都下も無駄。必要なのはObject。DB依存の処理をしている
#10
・DBは使うけど、ログとか過去データとか
Download
























































![[D35] インメモリーデータベース徹底比較 by Komori](https://cdn.slidesharecdn.com/ss_thumbnails/d35hp-140623212142-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180308-180308093647-thumbnail.jpg?width=640&height=640&fit=bounds)

































