Downloaded 12 times












![PolyBase: statistics
CREATE STATISTICS
CustomerCustKeyStatistics
ON pb_sqlserver.address
(stateprovinceid) WITH FULLSCAN;
SELECT DISTINCT a.city
from [pb_sqlserver].[address] a
where a.stateprovinceid = 9](https://image.slidesharecdn.com/mssql2019bigdataprocessing-190408133358/85/Andriy-Zrobok-MS-SQL-2019-new-for-Big-Data-Processing-14-320.jpg)

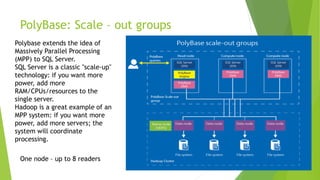




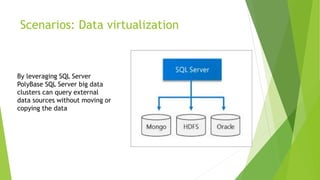
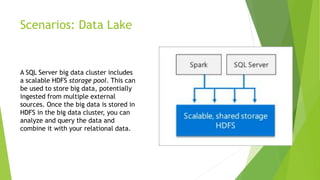




This document discusses MS SQL Server 2019's capabilities for big data processing through PolyBase and Big Data Clusters. PolyBase allows SQL queries to join data stored externally in sources like HDFS, Oracle and MongoDB. Big Data Clusters deploy SQL Server on Linux in Kubernetes containers with separate control, compute and storage planes to provide scalable analytics on large datasets. Examples of using these technologies include data virtualization across sources, building data lakes in HDFS, distributed data marts for analysis, and integrated AI/ML tasks on HDFS and SQL data.











![[db tech showcase Tokyo 2017] C37: MariaDB ColumnStore analytics engine : use...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstoreusecases1-170911080447-thumbnail.jpg?width=640&height=640&fit=bounds)











































































