Downloaded 120 times


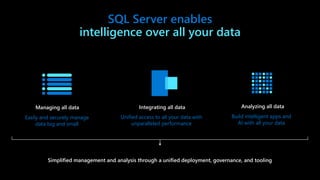


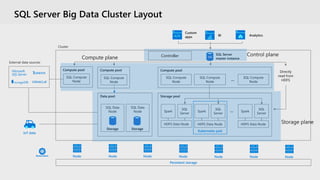




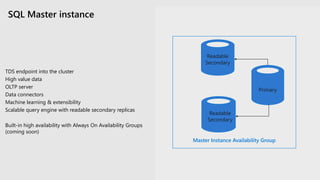

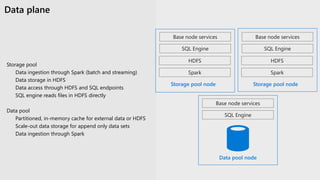




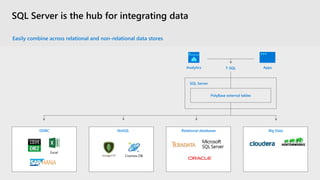

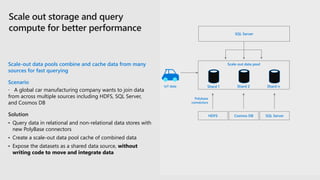






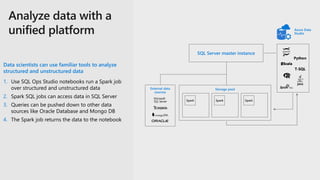









The document provides an overview of SQL Server's integration with big data through a unified deployment framework that simplifies management, analysis, and performance across all data types. It details features such as Kubernetes-based big data clusters, support for HDFS and Spark analytics, as well as real-time data ingestion and analytics capabilities. Enhanced tools for data virtualization, machine learning, and a focus on combining structured and unstructured data are also highlighted, making SQL Server a comprehensive solution for modern data needs.