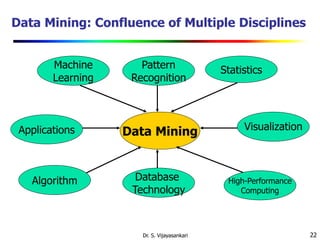
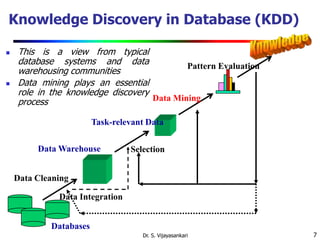
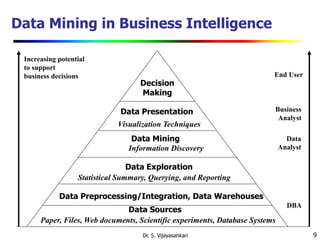
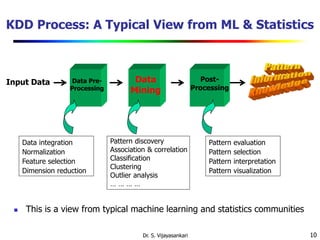
This document provides an introduction to data mining. It discusses why data mining is needed due to the explosive growth of data. It defines data mining as the extraction of interesting and previously unknown patterns from large datasets. The document outlines several key aspects of data mining including the types of data that can be mined, patterns that can be discovered, technologies used, applications targeted, and major issues in the field. It also provides a brief history of data mining and discusses how data mining draws from multiple disciplines like machine learning, statistics, and database technology.












![15
Data Mining Function: Association and
Correlation Analysis
Frequent patterns (or frequent item sets)
What items are frequently purchased together in your
Walmart?
Association, correlation vs. causality
A typical association rule
Diaper Beer [0.5%, 75%] (support, confidence)
Are strongly associated items also strongly correlated?
How to mine such patterns and rules efficiently in large
datasets?
How to use such patterns for classification, clustering, and
other applications?
Dr. S. Vijayasankari](https://image.slidesharecdn.com/dataminingsvs-210529050041/85/Data-mining-Introduction-15-320.jpg)