Downloaded 18 times




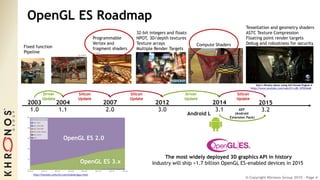


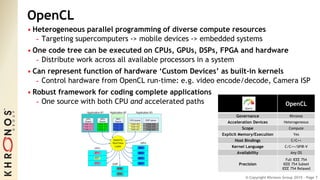
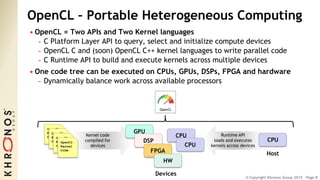
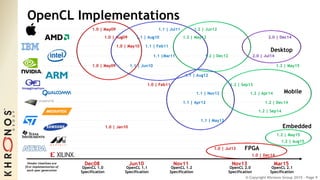
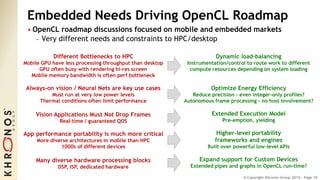
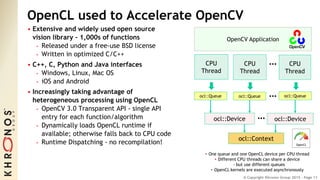
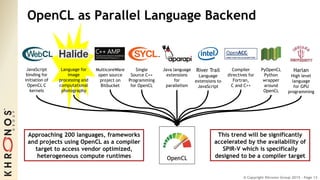





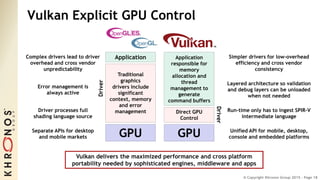
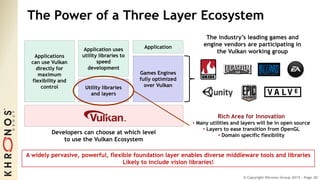



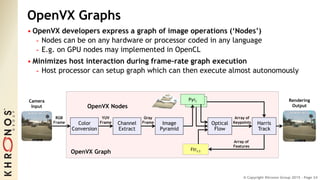
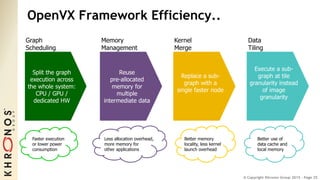
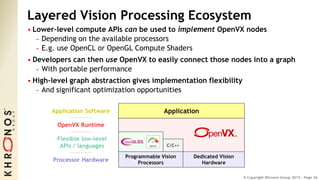
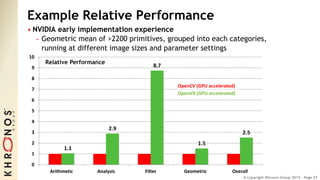
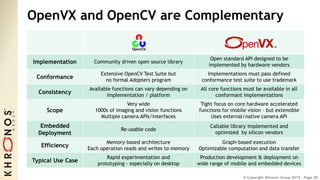

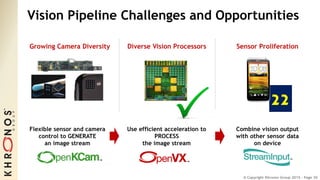
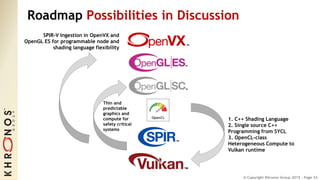


The document outlines the developments and standards of various Khronos Group open standard APIs for vision processing, including OpenGL ES, OpenCL, and Vulkan. It emphasizes advancements in low-power and portable vision processing, heterogeneous parallel processing, and the importance of performance portability across diverse hardware platforms. The document also introduces OpenVX as a high-level abstraction API designed for real-time mobile and embedded platforms, enabling efficient vision processing with minimal host interaction.











































































































