Download to read offline







![• Kernel: function that defines the behavior of each thread
• For example, kernel for vector addition:
__kernel void sumKernel (
__global int* a, __global int* b, __global int* c)
{
int i = get_global_id(0);
c[i] = a[i] + b[i];
}
Written in OpenCL-C: ANSI-C + Set of kernel functions, e.g.:
• get_global_id: obtains thread index
• barrier: synchronizes threads](https://image.slidesharecdn.com/openclbyhammad-170528114127/85/Introduction-to-OpenCL-By-Hammad-Ghulam-Mustafa-7-320.jpg)















![• OpenCL does not provide performance portability
• Alternative to NVIDIA CUDA:
Programming paradigm for NVIDIA GPU cards
• Combinable with other parallel programming models:
OpenMP for SMPs / MPI for MPPs
• Huge ecosystems for OpenCL, e.g. OpenACC:
Develop GPGPU applications using directives
#pragma acc kernels
for(i = 0; i< N; i++)
c[i] = b[i] + a[i];](https://image.slidesharecdn.com/openclbyhammad-170528114127/85/Introduction-to-OpenCL-By-Hammad-Ghulam-Mustafa-24-320.jpg)


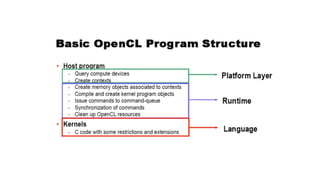
The document provides an overview of OpenCL, its execution model, and its applications in general-purpose computing on graphics processing units (GPGPU). It covers programming basics, including kernel functions, the structure of OpenCL applications, and the role of compute devices, emphasizing data parallelism and the performance benefits it offers. Additionally, it discusses the interoperability of OpenCL with other programming models and its ecosystem, including alternatives like NVIDIA CUDA.



































































