Download to read offline






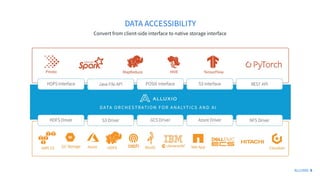

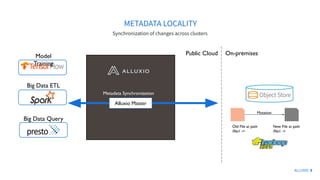
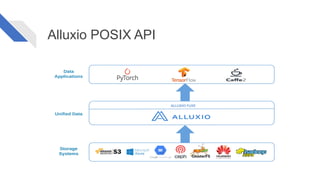
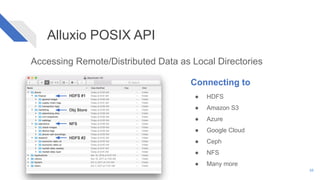


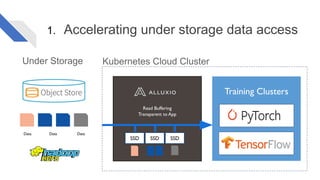





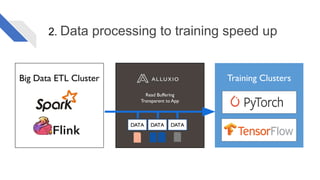

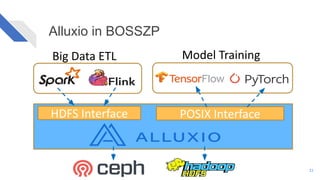

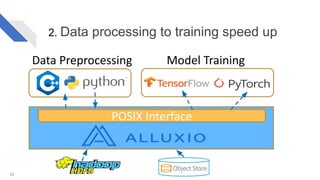

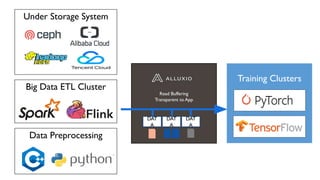
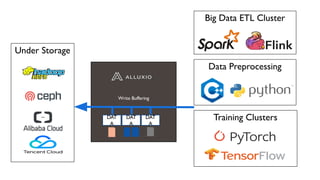


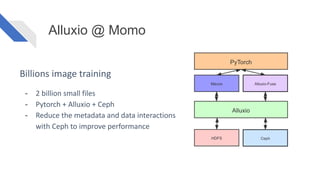





The document discusses how Alluxio can enhance cloud training by providing efficient data access and orchestration through its POSIX API, benefiting applications in machine learning and big data processing. It outlines three main strategies: accelerating storage read access, improving data preprocessing and training, and establishing a robust data orchestration layer. Various integrations and use cases from notable companies illustrate Alluxio's capability to handle large datasets while reducing I/O wait times and enhancing overall performance.



































































