Recommended
PDF
PDF
PDF
PDF
PDF
-SSIIの技術マップ- 過去•現在, そして未来 [領域]認識
PDF
PDF
PDF
次世代セキュリティを牽引する画像解析技術の最新動向 - 距離情報を用いた物体認識技術 -
PPTX
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
SSII2019TS: プロジェクタ・カメラシステムが変わる! ~時間同期の制御で広がる応用~
PDF
PDF
PDF
SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~
PDF
PDF
SSII2019企画: 画像および LiDAR を用いた自動走行に関する動向
PDF
SSII2018TS: コンピュテーショナルイルミネーション
PDF
SSII2019TS: プロジェクタ・カメラシステムが変わる! ~時間同期の制御で広がる応用~
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
PPTX
PPTX
SSII2020TS: 物理ベースビジョンの過去・現在・未来 〜 カメラ・物体・光のインタラクションを モデル化するには 〜
PPTX
[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsuper...
PPTX
[サーベイ論文] Deep Learningを用いた歩行者検出の研究動向
PDF
PPTX
PDF
PPTX
PDF
PPT
More Related Content
PDF
PDF
PDF
PDF
PDF
-SSIIの技術マップ- 過去•現在, そして未来 [領域]認識
PDF
PDF
PDF
次世代セキュリティを牽引する画像解析技術の最新動向 - 距離情報を用いた物体認識技術 -
What's hot
PPTX
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
SSII2019TS: プロジェクタ・カメラシステムが変わる! ~時間同期の制御で広がる応用~
PDF
PDF
PDF
SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~
PDF
PDF
SSII2019企画: 画像および LiDAR を用いた自動走行に関する動向
PDF
SSII2018TS: コンピュテーショナルイルミネーション
PDF
SSII2019TS: プロジェクタ・カメラシステムが変わる! ~時間同期の制御で広がる応用~
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
PPTX
PPTX
SSII2020TS: 物理ベースビジョンの過去・現在・未来 〜 カメラ・物体・光のインタラクションを モデル化するには 〜
PPTX
[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsuper...
PPTX
[サーベイ論文] Deep Learningを用いた歩行者検出の研究動向
PDF
PPTX
PDF
PPTX
Similar to 東工大長谷川修研紹介 2011 (8月1日版)
PDF
PPT
PDF
VIEW2013 Binarycode-based Object Recognition
PDF
SSII2014 詳細画像識別 (FGVC) @OS2
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
PDF
画像局所特徴量と特定物体認識 - SIFTと最近のアプローチ -
PDF
「デザイニング・インターフェース」勉強会 - 第7章
PDF
PPTX
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transfo...
PDF
Towards Scalable Human-aligned Benchmark for Text-guided Image Editing
PPTX
深層学習を用いたバス乗客画像の属性推定 に関する研究
PDF
PPTX
PDF
PDF
RobotPaperChallenge 2019-07
PPTX
PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
PDF
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
PDF
PDF
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
PDF
PMBOK 7th Edition Project Management Process Scrum
PDF
PMBOK 7th Edition_Project Management Context Diagram
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
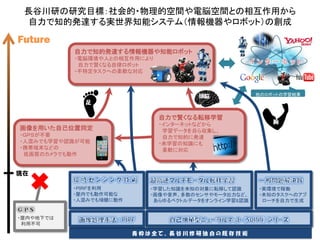
東工大長谷川修研紹介 2011 (8月1日版) 1. 2. 長谷川研の研究目標:社会的・物理的空間や電脳空間との相互作用から
自力で知的発達する実世界知能システム(情報機器やロボット)の創成
Future
自力で知的発達する情報機器や知能ロボット
・電脳環境や人との相互作用により
自力で賢くなる自律ロボット
・不特定タスクへの柔軟な対応
頭脳 他のロボットの学習結果
足
自力で賢くなる転移学習
・インターネットなどから 腕
画像を用いた自己位置同定 学習データを自ら収集し、
・GPSが不要 自力で知的に発達
・人混みでも学習や認識が可能 ・未学習の知識にも
・携帯端末などの 柔軟に対応
低画質のカメラでも動作
現在
・PIRFを利用 ・学習した知識を未知の対象に転移して認識 ・実環境で稼働
・屋内でも動作可能な ・画像や音声、多数のセンサやモータ出力など、 ・未知のタスクへのアプ
・人混みでも頑健に動作 あらゆるベクトルデータをオンライン学習&認識 ローチを自力で生成
・屋内や地下では
利用不可
青枠は全て、長谷川修研独自の既存技術
3. 長谷川研の研究
• 人の生活環境で稼働する、さまざまな人工の
「知能」の構築を通じ、広く社会の発展に寄与す
ることを目標とする。
• 上記でいう知能とは、私たちが日常的に行って
いるのと同じように、人工物が「見て、聞いて、
覚えて、考えて、行動する」ためのものである。
• これを確実に実現する従来技術は存在しない。
そこで、長谷川らの独自技術であるSOINNを
活用した実世界知能情報処理機構の構築から
取り組む。
4. 5. 6. 7. 8. Google で「顔検出」と検索すると、
トップに下記の論文が表示される。
林伸治、長谷川修 : “低解像度画像からの顔検出”,
画像電子学会誌, Vol.34, No.6, pp.726-737, (2005)
つまり、この論文は度々検索され、読まれている。
この英訳は、IEEE Conference on Computer Vision and
Pattern Recognition (CVPR 2006) にも採録
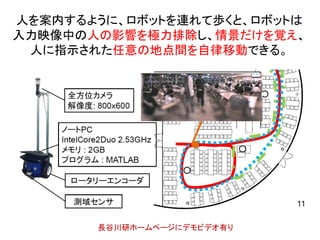
長谷川研ホームページにデモビデオ有り
9. この研究では、従来困難であった
「小さい顔」の検出を実現した。
これにより、画像サイズを縮小して
からでも顔検出が可能になった。
これは画像処理量の大幅な
従来の顔検出 削減につながり、デジカメの非力な
CPUでも顔検出を可能とした。
現在、この技術は市販の多くの
デジカメやビデオに利用されている。
提案手法(小さい顔も検出)
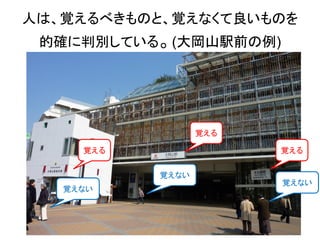
10. 11. 12. 13. この機能は、実環境で人と共存するロボットには不可欠。
以下は、移動ロボット分野における性能評価のための世界標準データの一つ。
移動ロボットが以下の情景の中をループ状に2回周回する。2周目には、1周目の
どの情景と一致するかを当てる。
1周目に居た、人や車が居なくなっても当たるか?
14. 15. PIRF:動いているカメラから、止まっている
ものと、動いているものを見分ける技術
たまたま通り
SIFT : 普通に処理すると、あらゆるところから画像特徴が出る。 かかった人。
PIRFは出て
いない。
15
PIRF: 提案手法の処理結果例
16. PIRF: algorithm Current image
過去の画像を参照し、
共通するSIFT特徴を
抽出して、その位置の
特徴表現とする。
16
17. 18. 19. 20. 21. さらなる実験
東工大学食での実験
エキストラでない不特定多数の人が利用
21
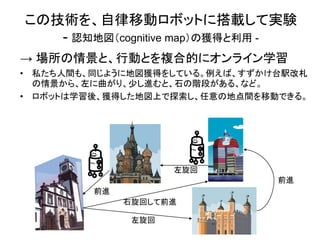
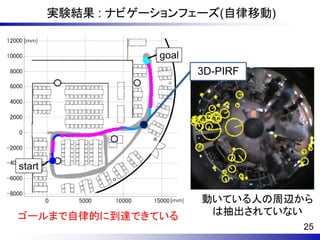
22. 23. この技術を、自律移動ロボットに搭載して実験
- 認知地図(cognitive map)の獲得と利用 -
→ 場所の情景と、行動とを複合的にオンライン学習
• 私たち人間も、同じように地図獲得をしている。例えば、すずかけ台駅改札
の情景から、左に曲がり、少し進むと、石の階段がある、など。
• ロボットは学習後、獲得した地図上で探索し、任意の地点間を移動できる。
左旋回
前進
前進
右旋回して前進
左旋回
24. 25. 26. この技術は移動支援IRTへの活用を検討中
• 屋外だけでなく、GPSが利用できない地下や屋内の人混みでも
自律移動
• 搭乗者、歩行者、双方の安全・安心の実現
• 移動のための地図は、患者や高齢者を含む誰もが簡単に作成
可能(従来法は膨大な手間)
• まず、電動車椅子への搭載を検討。人の生活環境で活動するロ
ボット全般に利用可能。
26
27. この技術は、携帯カメラでも稼働する
テスト画像
手持ちのiPhone4
のカメラで撮影
学習画像
手持ちの家庭用
ビデオカメラ
で撮影
下が学習画像で、上がテスト画像。人が居ても、人の影響を受け
ずに上下は同位置と正しく判定している。
テスト画像にはiPhone4の画像を使用。
27
GPSの使えない屋内や地下でも利用可能
28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. なので、まだロボットには使えない
ロボットは総合学であり、本来は
見て、聞いて、感じて、覚えて、考えて、動いて、
労働するもの。
“Robot” はチェコ語で強制労働を意味する
“robotnik” から作られた造語
39. 40. 41. 42. 現在のロボットの問題
• ロボットに命令するだけでも大変
– 現状では、専門家が決められた手順に沿って、手間
をかけてプログラムしている
– お年寄りや子供たちには、とても無理
– 人間がロボットの都合にあわせるのは絶対イヤだ!
• 「人間中心の」情報処理技術の必要性
• ロボットにやって欲しいこと
– どのようなことでも、「掃除して」、「洗濯して」、
などと言うだけで、やって欲しい。
42
43. 専用機 vs 汎用機
現存する人工物は、全て
特定の目的のために作られた専用機。
VS
注)PCはハードウエアは汎用だが、 注)汎用機が人の姿を
ソフトウエアが専用なので、「専用機」。 しているとは限らない。
44. これからは、「汎用機」の研究と
実用化の推進が急務
SOINN !!
Self-Organizing Incremental Neural Network
45. SOINNとは?
東工大 長谷川修研で独自開発
コンピュータやロボットが
「見て、聞いて、覚えて、考えて、行動する」
ための脳をヒントにした情報処理技術 45
46. 47. 48. 49. 超高速オンライン転移学習
東京工業大学
木村大毅, Kankuekul Pichai,
Aram Kawewong, 長谷川修
画像センシングシンポジウム 2011
50. 51. 52. 53. 54. 55. 本研究の成果と意義
• 下記を兼ね備えた、現実的な物体認識 手法
を構築。
– 転移学習を導入
• 実世界を少数の基本的な属性知識の組合せで認識(
例:赤+球+果物=リンゴ)
– 命令するだけで「自力で・直ちに」賢くなる
• 学習データはインターネットから自動収集
• 超高速にオンライン追加学習&認識
– 画像以外にも多様・Noisy・曖昧な情報に対応
• 多様な曖昧情報を複合的に利用可能
55
56. 57. 58. Transfer Learning (転移学習)
• 対象について学習するのではなく、
基本的な概念(「属性」と呼ぶ)を学習
• 属性の組み合わせで未学習物体も認識
窓 ダイヤル
学
習
ボール 箱 転移
画
像
電子レンジ
ダイヤルと窓がある箱型のもの= 電子レンジ
人間が定義
59. Transfer learning (転移学習)
• この関係はアルファベットと辞書の関係に類似
– 英語の場合、26文字の組合せで数十万の単語。
– 前頁の例では「ダイヤル+箱=金庫」もわかる。
• さらに、提案手法はベクトルデータ全般を属性
として超高速オンライン追加学習可能。
– 画像、音声、各種センサデータ、モータの制御信号
など、あらゆるパターンデータが入力可能。
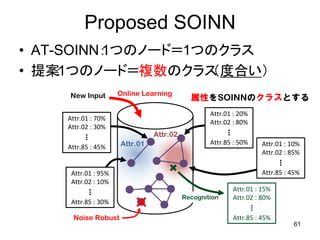
60. 61. Proposed SOINN
• AT-SOINN:
1つのノード=1つのクラス
• 提案1つのノード=複数のクラス
: (度合い)
New Input Online Learning
属性をSOINNのクラスとする
Attr.01 : 20%
Attr.01 : 70%
Attr.02 : 80%
Attr.02 : 30%
・
・
・
・ Attr.02 ・
・ Attr.85 : 50%
Attr.85 : 45% Attr.01 Attr.01 : 10%
Attr.02 : 85%
・
・
・
Attr.01 : 95% Attr.85 : 45%
Attr.02 : 10%
・
・ Attr.01 : 15%
・ Recognition Attr.02 : 80%
Attr.85 : 30%
・
・
・
Noise Robust Attr.85 : 45%
61
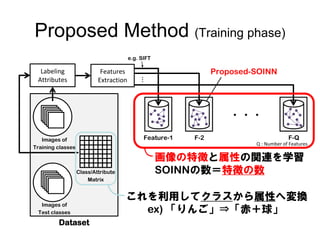
62. Proposed Method (Training phase)
e.g. SIFT
Labeling Features Proposed-SOINN
…
Attributes Extraction
・・・
Images of Feature-1 F-2 F-Q
Q : Number of Features
Training classes
画像の特徴と属性の関連を学習
Class/Attribute SOINNの数=特徴の数
Matrix
これを利用してクラスから属性へ変換
Images of
Test classes ex) 「りんご」⇒「赤+球」
Dataset
63. Proposed Method (Test phase)
e.g. SIFT
Labeling Features Proposed-SOINN
…
Attributes Extraction
・・・
Images of Feature-1 F-2 F-Q
Training classes 与えられた特徴から
各々の属性の度合いを算出
Class/Attribute Calculate Attributes using statistical recognition
Matrix
未知クラスも属性のみは知っている
Images of Guess the Class according to these Attributes
Test classes
Q : Number of Features
Dataset 各々の属性からクラスへ変換
ex) 「赤+球」⇒「りんご」
64. SOINN [Shen, Hasegawa, NN06]
• 自己増殖型ニューラルネットワーク
– オンラインかつ追加的に学習可能
– クラス数や分布の形などの事前知識が不要
– 実世界での運用を考慮したノイズ耐性
– マルチモーダルなパターン情報を学習可能
強力な
ノイズ耐性
入力情報 SOINN内の情報
65. 66. 提案手法の発展例
• 従って、こんなことが出来る。
他のロボットの学習結果
楽チン!
イ ン タ ー ネ ット
膨大な情報 物理的経験 学習
オンラインで 人の命令 データ
準備不要
超高速に学習
属性知識
獲得した属性知識を 「箱+窓+ダイヤル+チン♪」
未知対象に適用し認識 ⇒電子レンジ
67. Experiments
• Lampertら[1]の動物の画像で比較実験
– 50種類の動物
• ライオン、シマウマ、豚、シロクマ、イルカなど
– 85種類の属性(基本的な概念)
• 肉食動物、尻尾がある、速く走る、賢いなど
– 6種類の画像特徴
• SIFT、SURF、pHOG、rgSIFT、LSS、CQの
それぞれのヒストグラム(Bag-of-Features)
※上で挙げた従来手法以外にも多くの論文で使用されている
68. Experiments
例)未知の豚を当てる方法 草食動物
飛べない
肉食動物 だろう
だろう
足が短い
飛べない
肉食動物 学習動物 見たことがない
動物
40 10
足が短い 種類
草食動物
属性
を転移 種類
飛べる 足が長い 足が短い
だろう
飛べない
ライオン コウモリ 足が短く飛べない草食動物
馬
=豚?!
未知動物も属性の組み合わせは知っている
69. Results
オンライン学習 バッチ学習
AT-
提案手法 SOINN[2]
DAP[1] IAP[1]
認識率 26.82% 26.96% 40.51% 27.83%
学習時間 7分 6時間 >70日
認識時間 1分半 4時間 >2日
データ量 1,825 347,082 -
(ノード数)
99.47%削減
SOINNの数 6 1020 -
なお学習時間と認識時間は、特徴検出の時間を含めない
70. Results
オンライン学習 バッチ学習
AT-
提案手法 SOINN[2]
DAP[1] IAP[1]
曖昧な
属性※ ○ × × ×
属性の
追加 ○ △ × ×
※曖昧な属性とは、連続値での属性の定義が出来るという意味である
提案手法は、
54枚/秒で学習、16ミリ秒/枚で認識
更に、曖昧な属性や柔軟な属性の追加が可能
71. 更なる展開:インターネットの活用
例)
• その場で、直ちに賢くなる
– 高速性やオンライン学習性を活用
• 複雑な実環境では、有効な属性を事前に
想定するのは困難。
• 有効な属性を、人や環境とのインタラクションを通じて
決定。
– ネットの情報は極めてノイジー
• SOINNのノイズ耐性を活用
– 大規模評価実験の実施を予定
72. 主要参考文献
[1] C. H. Lampert, H. Nickisch, and S. Harmeling, “Learning to detect
unseen object classes by between-class attribute transfer”, CVPR
2009.
[2] A. Kawewong, Sirinart Tangruamsub, Pichai Kankuekool and
Osamu Hasegawa, “Fast Online Incremental Transfer Learning for
Unseen Object Classification Using Self-Organizing Incremental
Neural Networks”, The 2011 International Joint Conference on
Neural Networks (IJCNN).
[3] F. Shen, O. Hasegawa, “An Incremental Network for On-line
Unsupervised Classification and Topology Learning”, Neural
Networks 2006.
73. 74. 75. 長谷川研の研究目標:社会的・物理的空間や電脳空間との相互作用から
自力で知的発達する実世界知能システム(情報機器やロボット)の創成
Future
自力で知的発達する情報機器や知能ロボット
・電脳環境や人との相互作用により
この実現のための、
自力で賢くなる自律ロボット
・不特定タスクへの柔軟な対応
最初のアプローチ
頭脳 他のロボットの学習結果
足
自力で賢くなる転移学習
・インターネットなどから 腕
画像を用いた自己位置同定 学習データを自ら収集し、
・GPSが不要 自力で知的に発達
・人混みでも学習や認識が可能 ・未学習の知識にも
・携帯端末などの 柔軟に対応
低画質のカメラでも動作
現在
・PIRFを利用 ・学習した知識を未知の対象に転移して認識 ・実環境で稼働
・屋内でも動作可能な ・画像や音声、多数のセンサやモータ出力など、 ・未知のタスクへのアプ
・人混みでも頑健に動作 あらゆるベクトルデータをオンライン学習&認識 ローチを自力で生成
・屋内や地下では
利用不可
青枠は全て、長谷川研独自の既存技術
76. 問題点と本研究の着眼
従来手法
• 殆どの場合、膨大な学習データの収集
や教師ラベル付与は人が行う。
• 長谷川研の顔検出実験では、5万枚
以上の画像から、3万枚以上の顔画
像だけを人手で抽出した。
本研究
• ネット上には、ノイジーだが膨大な情報が存在する。
• ネットの情報は、世界中で日々更新・蓄積されている。
• ここから意味のある情報を取り出せれば、学習に使える!
• SOINNのノイズ除去機能やオンライン学習機能を活用
76
77. 78. 79. さらに、実験では異なる条件で2つのシステムを構成
• 野菜学習システム vs 人工物学習システム
野菜や果物の画像を学習 人工物の画像を学習
Learn from:
Learn from:
- Human objects
- Fruits and Vegetables
Training object classes:
Training object classes:
- soda-can, computer-keyboard,
- Tomato, cinnamon, and broccoli
shipping box
Testing object classes:
Testing object classes:
- cucumber, lemon and watermelon
- Bottle, Tennis-ball, Microwave
Attributes:
Attributes:
- stick, sphere
- cylinder, buttons, cubic
80. 人工物学習システム
Computer-keyboard
• Learn three attributes
– ‘cylinder’, ‘has buttons’ and
‘cubic’
• Classify on Soda-can
– Bottle, tennis-ball and
microwave Shipping-boxes
Step Learnt Attributes Avg. Acc. (%)
1 ‘cylinder’, ‘has buttons’ 61.40
and ‘cubic’
自動収集した学習画像は、各200枚程度。属性の組み合わせで認識
するので、「たったそれだけ」で上記の認識率が得られることが判明。
81. 野菜学習システム
属性のオンライン追加学習により、認識率が向上することを確認。
Step 1: Learn only ‘sphere’ and ‘stick’ attributes (from tomato,
cinnamon and broccoli)
Step Learnt Attributes Avg. Acc. (%)
1 Sphere, Stick 38.89
Step 2: add color attributes
- learn 'red’, ‘green’ and ‘brown’ attributes from the same training
object classes
- learn ‘yellow’ attribute from new object class banana
Step Learnt Attributes Avg. Acc. (%)
1 Sphere, Stick 38.89
2 Sphere, Stick + Red, green, 56.51
brown, yellow
82. 「システムが、システムに教える」実験
人工物システムが、野菜システムに学習済み ”cylinder” の属性
データを転送し、野菜システムの認識率を向上させた。
人工物学習システム 野菜学習システム
Transfer ‘cylinder’
attribute from the system II
Learn three attributes Step Learnt Attributes Avg. Acc.
• ‘cylinder’,
(%)
• ‘has buttons’
• and ‘cubic’ 1 sphere, stick 38.89
2 sphere, stick + red, green, 56.51
brown, yellow
3 sphere, stick, red, green, brown, 70.11
yellow +cylinder
83. 84. 長谷川研の研究目標:社会的・物理的空間や電脳空間との相互作用から
自力で知的発達する実世界知能システム(情報機器やロボット)の創成
Future
自力で知的発達する情報機器や知能ロボット
・電脳環境や人との相互作用により
自力で賢くなる自律ロボット
・不特定タスクへの柔軟な対応
頭脳 他のロボットの学習結果
足
自力で賢くなる転移学習
・インターネットなどから 腕
画像を用いた自己位置同定
この実現のための、
・GPSが不要
・人混みでも学習や認識が可能
学習データを自ら収集し、
自力で知的に発達
・未学習の知識にも
アプローチ
・携帯端末などの
低画質のカメラでも動作
柔軟に対応
現在
・PIRFを利用 ・学習した知識を未知の対象に転移して認識 ・実環境で稼働
・屋内でも動作可能な ・画像や音声、多数のセンサやモータ出力など、 ・未知のタスクへのアプ
・人混みでも頑健に動作 あらゆるベクトルデータをオンライン学習&認識 ローチを自力で生成
・屋内や地下では
利用不可
青枠は全て、長谷川研独自の既存技術
85. ロボットに応用問題を解かせる
• 現在の問題点
– ロボットは、プログラムした限定タスクしかできない。
• 提案手法:
– ロボットの腕を持って、基本的な動作(コップを持つ、コップから注
ぐなど)を個別に教示する。
– ロボットは、上記の動作群を組み合わせ、指示されたタスク解決
のための一連の挙動を自力で推論・生成し、達成する。(ポットか
ら急須に湯を注ぎ、湯呑みにお茶を淹れて、指定の場所に置く、
など。)
– 基本的な動作は、いつでも、ピンポイントで追加できる。
(新たな動作をオンライン追加学習でき、その結果としてロボットの
問題解決能力(知的レベル)が向上する。)
86. 87. 88. 89. 学習器の評価(1):
オンライン学習と追加学習
オンライン学習(Online Learning)
多数の学習データを一括して処理するのではなく、入力される
データを逐次学習すること。言い換えれば、入力データを N 個
学習したときの学習結果を θ N として、 1 個目の入力データ
N
と θ N から θ N1 を順次求める学習手法
⇔ バッチ学習(Batch Learning)、オフライ ン学習(Offline Learnig)
追加学習(Incremental Learning)
過去の学習データを破壊することなく、新しい入力データを学
習できること。動的に形状が変化する非定常な分布も学習可能
である、学習器に適応性があるとも解釈できる
※ 逐次学習(Incremental Learning)と表記される場合もあるの
で注意が必要。この場合、多くは本発表における「オンライ
ン学習」を意味している 89
90. 学習器の評価(2):
有限メモリと計算量O(1)
有限メモリ(Finite Memory)
各ステップの学習時に計算のために確保するメモリ量が、学習
データ数が無限になった際に一定値、または有限値を取ること
計算量O(1) (Time Complexity)
各ステップの学習に要する計算量のオーダーが学習データ数 N
に対して 1 、つまり学習データ数に依らず一定であること。
例えば、バッチ学習は学習の度に過去の全ての学習データを確
認する必要があるため、少なくとも N となる
90
91. 学習器の評価(3):
オープンエンド学習
SOM SOINN GNG
・多層パーセプトロン
・SVM(SGD)
・HMM(オンラインEM)
・LVQ
計算量
O(1)
有限メモリ ・k-means
追加学習 ・SVM
・HMM
オンライン学習
バッチ学習
(狭義の)オープンエンド学習 (広義の)オープンエンド学習
91
92. SOINNシリーズ(1)
全て長谷川研で独自に研究開発
高速最近傍識別器の提案
パラメータ数を削減 半教師あり
Adjusted SOINN 能動学習への応用
Original SOINN Classifier
[神谷ら 2007] SSA-SOINN
[Shen et al. 2005] [桜井ら 2007]
2005 2007
E-SOINN
[小倉ら 2007]
SOINNを用いた
近似能力の維持と ロボットの言語獲得
構造・パラメータ数の
[Xe et al. 2007]
簡略化を同時に実現
92
93. SOINNシリーズ(2)
全て長谷川研で独自に研究開発
時系列パターン
認識への応用 パターンベース SOINNを用いた
推論の実現 ロボットの一般問題解決
SOINN-DP [巻渕ら 2010]
[岡田ら 2008] SOINN-PBR
[須藤ら 2008]
2008 2010
AT-SOINN
[Aram et al. 2010]
SOIAM GAM
[須藤ら 2008] [Shen et al. 2010] 属性情報を用いた
転移学習への応用
連想記憶の実現 系列データを想起可能な
連想記憶システム
93
























































![SOINN [Shen, Hasegawa, NN06]
• 自己増殖型ニューラルネットワーク
– オンラインかつ追加的に学習可能
– クラス数や分布の形などの事前知識が不要
– 実世界での運用を考慮したノイズ耐性
– マルチモーダルなパターン情報を学習可能
強力な
ノイズ耐性
入力情報 SOINN内の情報](https://image.slidesharecdn.com/2011ver4-110731220550-phpapp01/85/2011-64-320.jpg)


![Experiments
• Lampertら[1]の動物の画像で比較実験
– 50種類の動物
• ライオン、シマウマ、豚、シロクマ、イルカなど
– 85種類の属性(基本的な概念)
• 肉食動物、尻尾がある、速く走る、賢いなど
– 6種類の画像特徴
• SIFT、SURF、pHOG、rgSIFT、LSS、CQの
それぞれのヒストグラム(Bag-of-Features)
※上で挙げた従来手法以外にも多くの論文で使用されている](https://image.slidesharecdn.com/2011ver4-110731220550-phpapp01/85/2011-67-320.jpg)

![Results
オンライン学習 バッチ学習
AT-
提案手法 SOINN[2]
DAP[1] IAP[1]
認識率 26.82% 26.96% 40.51% 27.83%
学習時間 7分 6時間 >70日
認識時間 1分半 4時間 >2日
データ量 1,825 347,082 -
(ノード数)
99.47%削減
SOINNの数 6 1020 -
なお学習時間と認識時間は、特徴検出の時間を含めない](https://image.slidesharecdn.com/2011ver4-110731220550-phpapp01/85/2011-69-320.jpg)
![Results
オンライン学習 バッチ学習
AT-
提案手法 SOINN[2]
DAP[1] IAP[1]
曖昧な
属性※ ○ × × ×
属性の
追加 ○ △ × ×
※曖昧な属性とは、連続値での属性の定義が出来るという意味である
提案手法は、
54枚/秒で学習、16ミリ秒/枚で認識
更に、曖昧な属性や柔軟な属性の追加が可能](https://image.slidesharecdn.com/2011ver4-110731220550-phpapp01/85/2011-70-320.jpg)

![主要参考文献
[1] C. H. Lampert, H. Nickisch, and S. Harmeling, “Learning to detect
unseen object classes by between-class attribute transfer”, CVPR
2009.
[2] A. Kawewong, Sirinart Tangruamsub, Pichai Kankuekool and
Osamu Hasegawa, “Fast Online Incremental Transfer Learning for
Unseen Object Classification Using Self-Organizing Incremental
Neural Networks”, The 2011 International Joint Conference on
Neural Networks (IJCNN).
[3] F. Shen, O. Hasegawa, “An Incremental Network for On-line
Unsupervised Classification and Topology Learning”, Neural
Networks 2006.](https://image.slidesharecdn.com/2011ver4-110731220550-phpapp01/85/2011-72-320.jpg)



















![SOINNシリーズ(1)
全て長谷川研で独自に研究開発
高速最近傍識別器の提案
パラメータ数を削減 半教師あり
Adjusted SOINN 能動学習への応用
Original SOINN Classifier
[神谷ら 2007] SSA-SOINN
[Shen et al. 2005] [桜井ら 2007]
2005 2007
E-SOINN
[小倉ら 2007]
SOINNを用いた
近似能力の維持と ロボットの言語獲得
構造・パラメータ数の
[Xe et al. 2007]
簡略化を同時に実現
92](https://image.slidesharecdn.com/2011ver4-110731220550-phpapp01/85/2011-92-320.jpg)
![SOINNシリーズ(2)
全て長谷川研で独自に研究開発
時系列パターン
認識への応用 パターンベース SOINNを用いた
推論の実現 ロボットの一般問題解決
SOINN-DP [巻渕ら 2010]
[岡田ら 2008] SOINN-PBR
[須藤ら 2008]
2008 2010
AT-SOINN
[Aram et al. 2010]
SOIAM GAM
[須藤ら 2008] [Shen et al. 2010] 属性情報を用いた
転移学習への応用
連想記憶の実現 系列データを想起可能な
連想記憶システム
93](https://image.slidesharecdn.com/2011ver4-110731220550-phpapp01/85/2011-93-320.jpg)




![-SSIIの技術マップ- 過去•現在, そして未来 [領域]認識](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2014-os-recognition-140612-140611032253-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsuper...](https://cdn.slidesharecdn.com/ss_thumbnails/struct2depth0301-190304050917-thumbnail.jpg?width=640&height=640&fit=bounds)
![[サーベイ論文] Deep Learningを用いた歩行者検出の研究動向](https://cdn.slidesharecdn.com/ss_thumbnails/pedsurvey-161216014456-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

































