Download to read offline


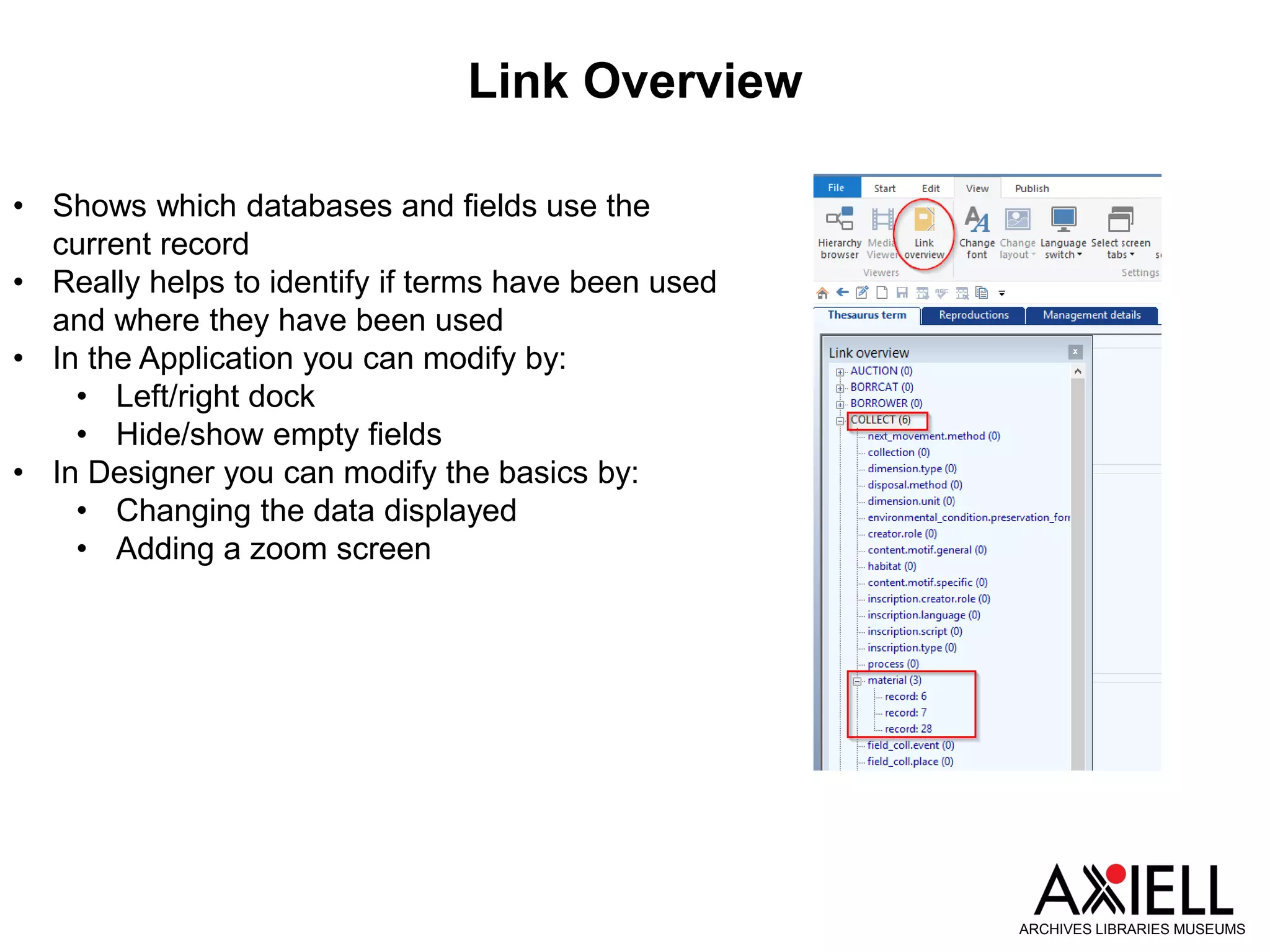



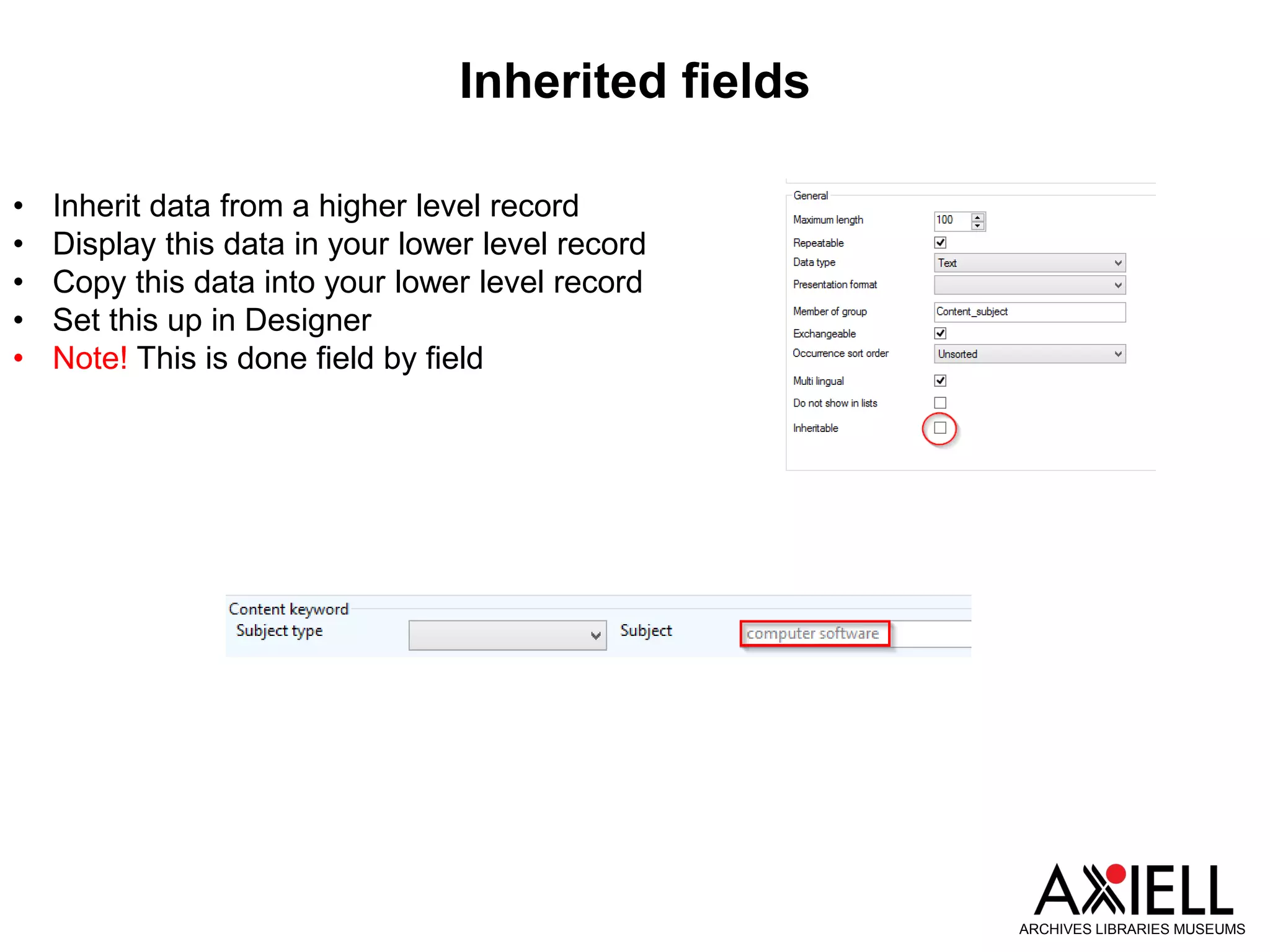
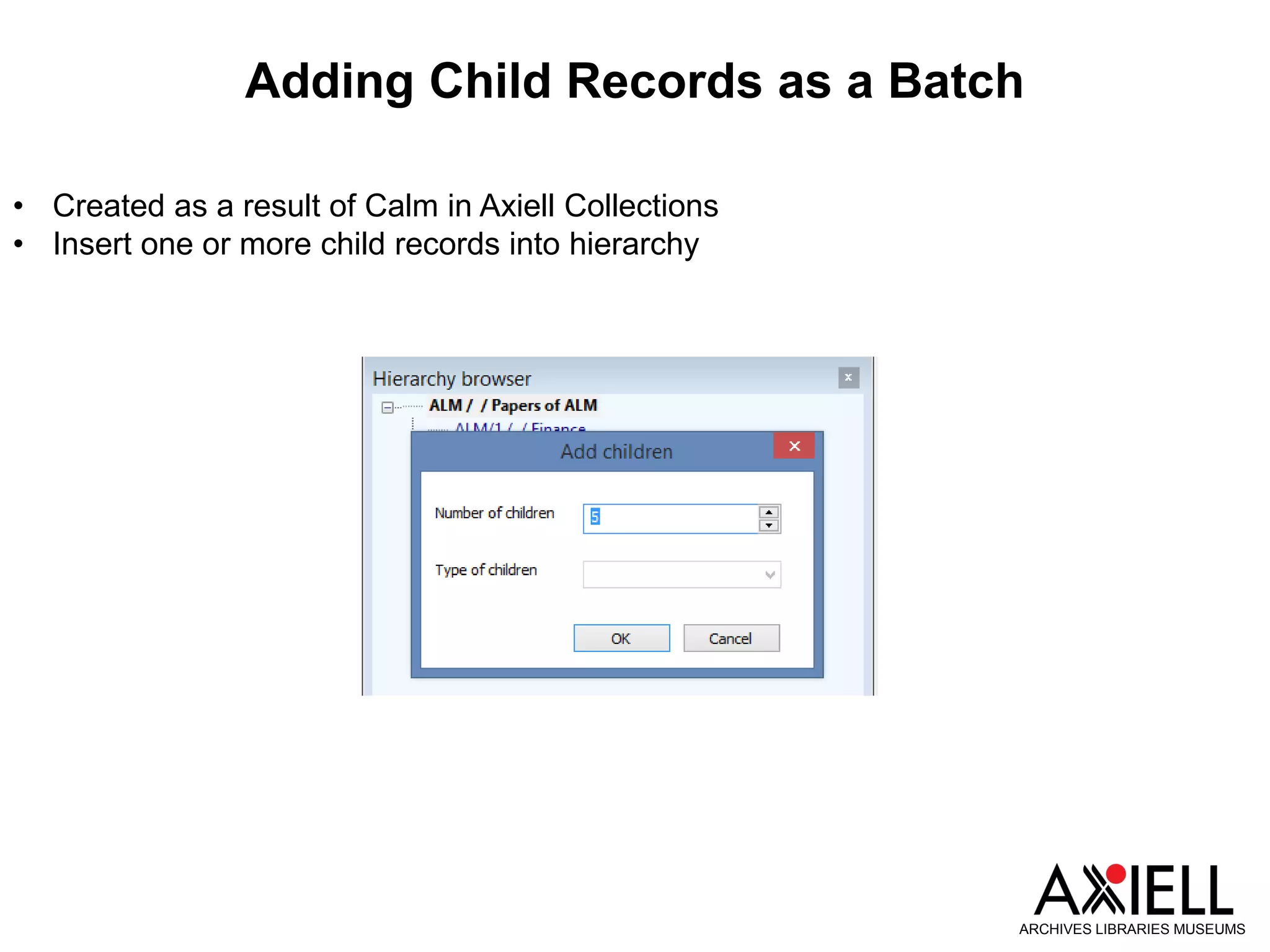
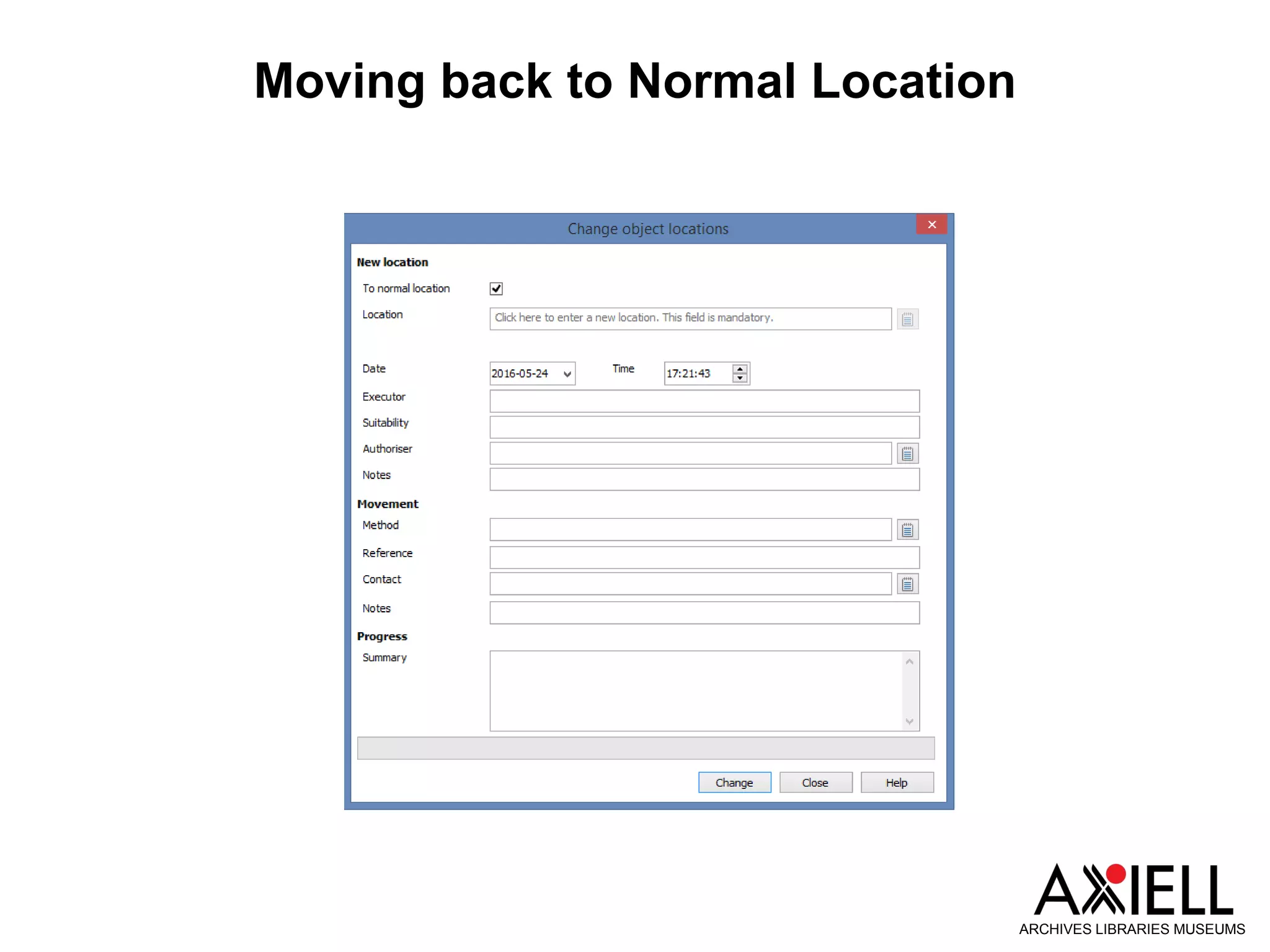

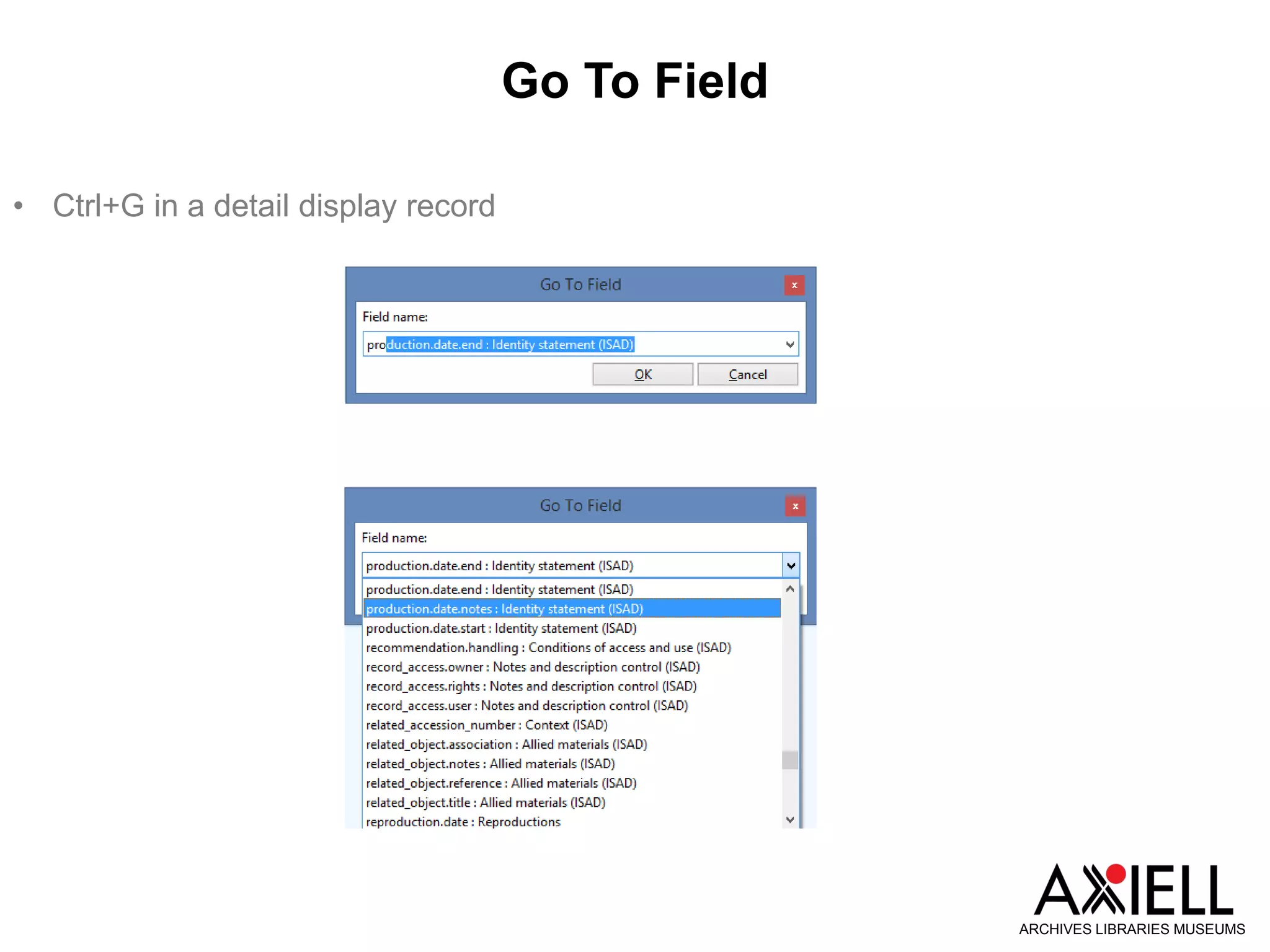


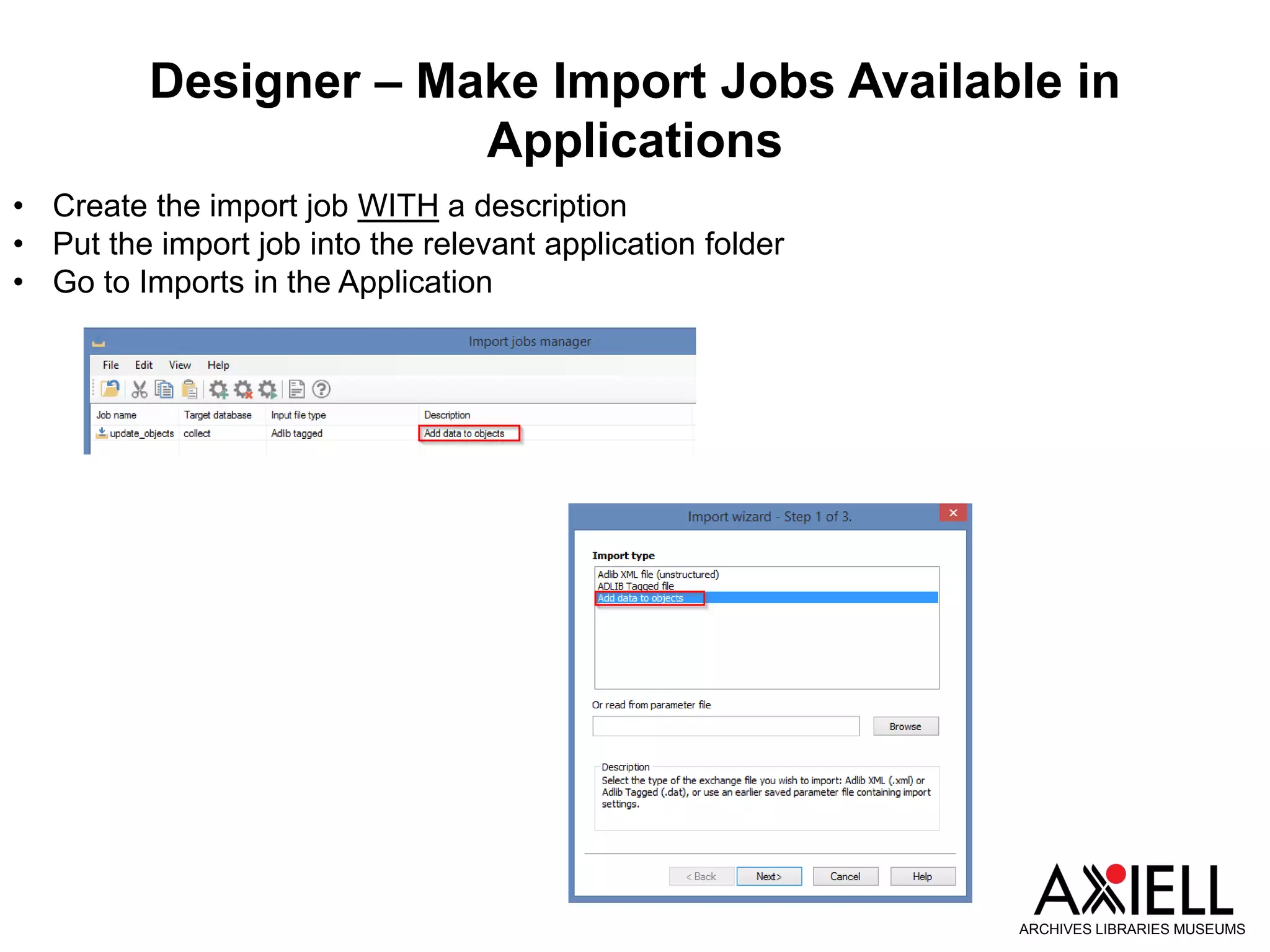



This document provides an overview of new features in Adlib version 7.3, including: 1) Obsolete and rejected terms in authority databases can now be marked as such and prevented from being used. 2) A new "Group" status allows terms in authority databases to be used in hierarchies but not in catalog records. 3) Hierarchy browsers now support displaying multiple hierarchies. 4) Fields can now inherit data from parent records in hierarchies. 5) Child records can now be added to hierarchies in batches.


































































