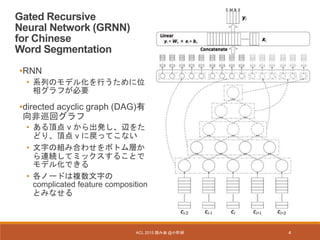
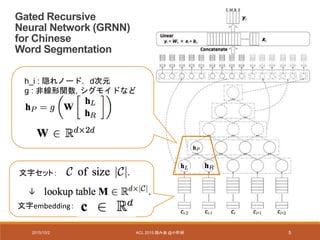
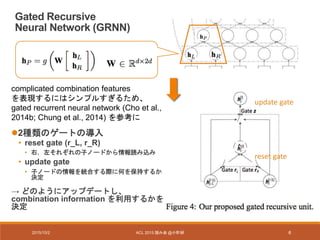
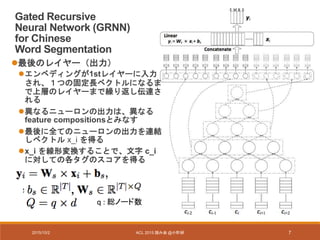
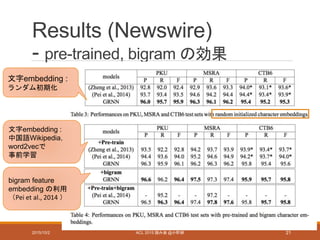
Experiments (Newswire)
- データセット
•PKU,MSRA
• the second International Chinese Word Segmentation Bakeoff
(Emerson, 2005) で提供
• Training set:train data中の90%
• Development set : train data中の10%
•CTB6
• Chinese TreeBank 6.0 (LDC2007T36) (Xue et al., 2005) による
• 分かち書き、POSタグ付け済み、選択的な形式主義において完全に構
造化されたコーパス
• Training, Development, Test のデータセットの分割は(Yang and Xue,
2012) らにならう
→ 前処理:中国語の熟語、英字、数字 は特殊記号で置き換える
2015/10/2 ACL 2015 読み会 @小町研 15
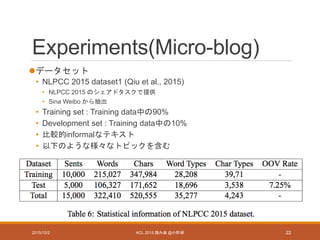
Experiments(Micro-blog)
データセット
• NLPCC 2015dataset1 (Qiu et al., 2015)
• NLPCC 2015 のシェアドタスクで提供
• Sina Weibo から抽出
• Training set : Training data中の90%
• Development set : Training data中の10%
• 比較的informalなテキスト
• 以下のような様々なトピックを含む
2015/10/2 ACL 2015 読み会 @小町研 22
















![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190920dlhack-190920011134-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DLHacks]Fast and Accurate Entity Recognition with Iterated Dilated Convoluti...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-180604045159-thumbnail.jpg?width=640&height=640&fit=bounds)







![[読会]P qk means-_ billion-scale clustering for product-quantized codes](https://cdn.slidesharecdn.com/ss_thumbnails/pqk-meansbillion-scaleclusteringforproduct-quantizedcodes-211229095124-thumbnail.jpg?width=640&height=640&fit=bounds)
![Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介](https://cdn.slidesharecdn.com/ss_thumbnails/graph2sequencelearningusinggatedgraphneuralnetworkacl18-190507010338-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl1211-191213002847-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)












