Downloaded 120 times


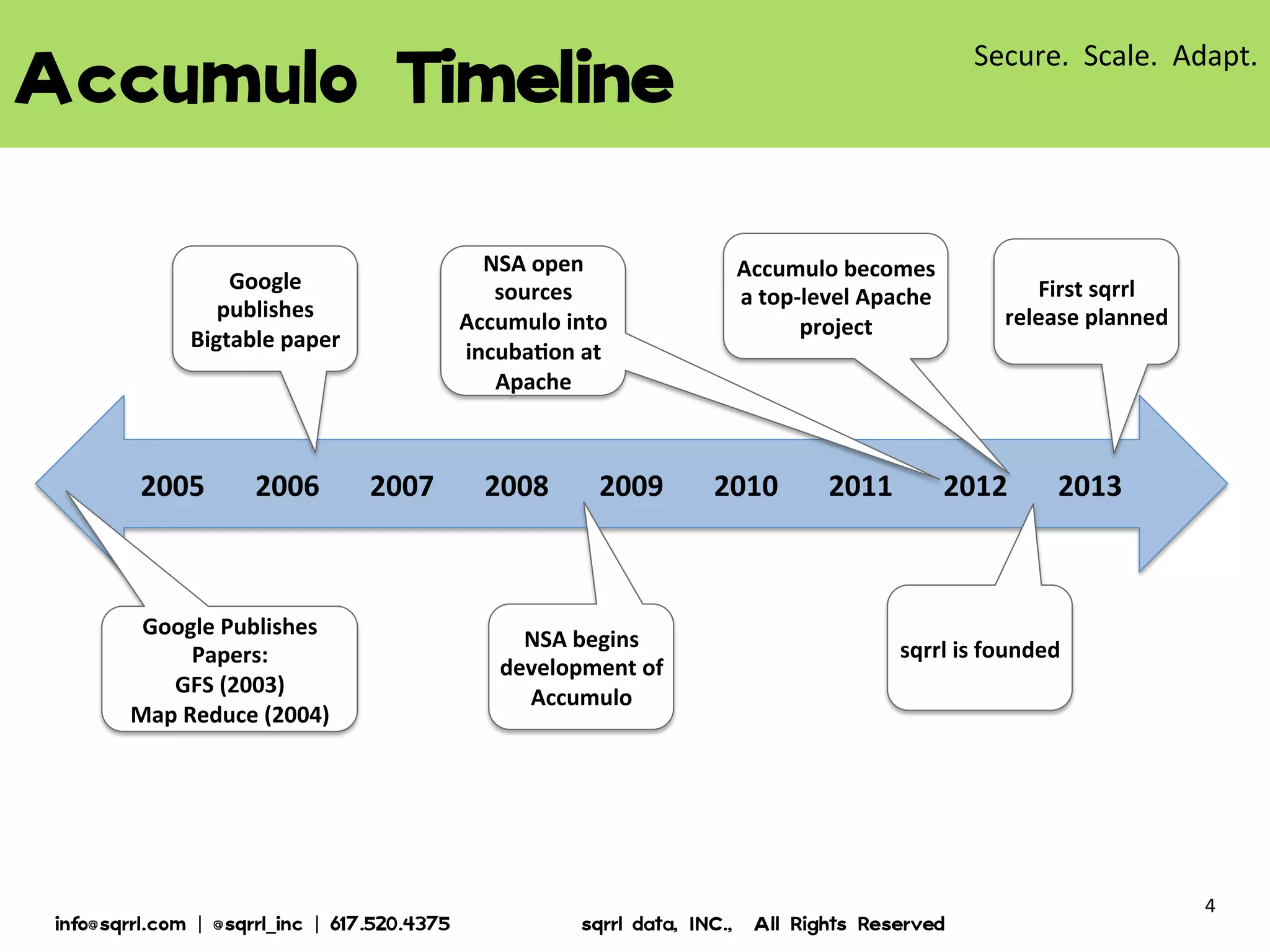


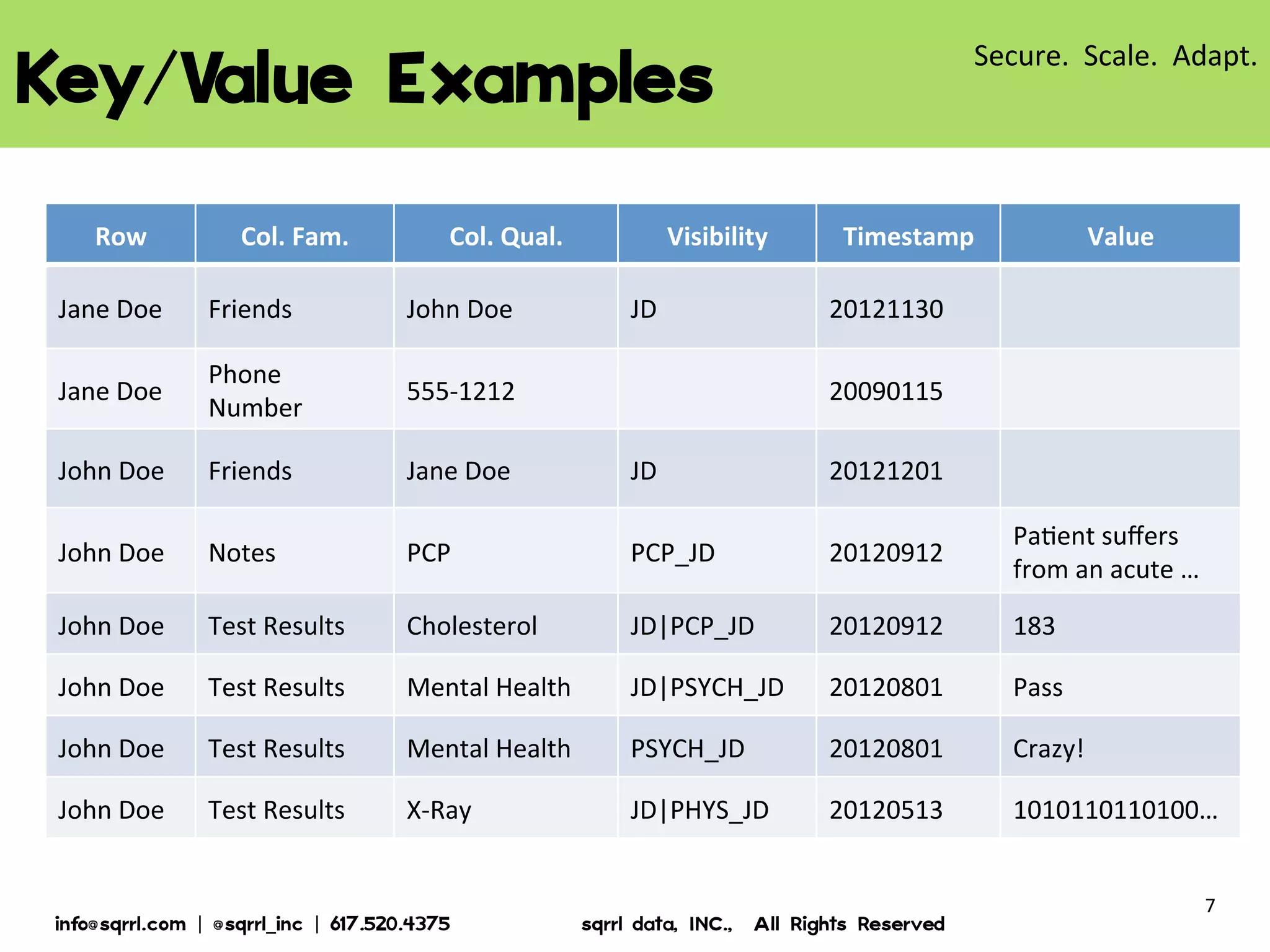

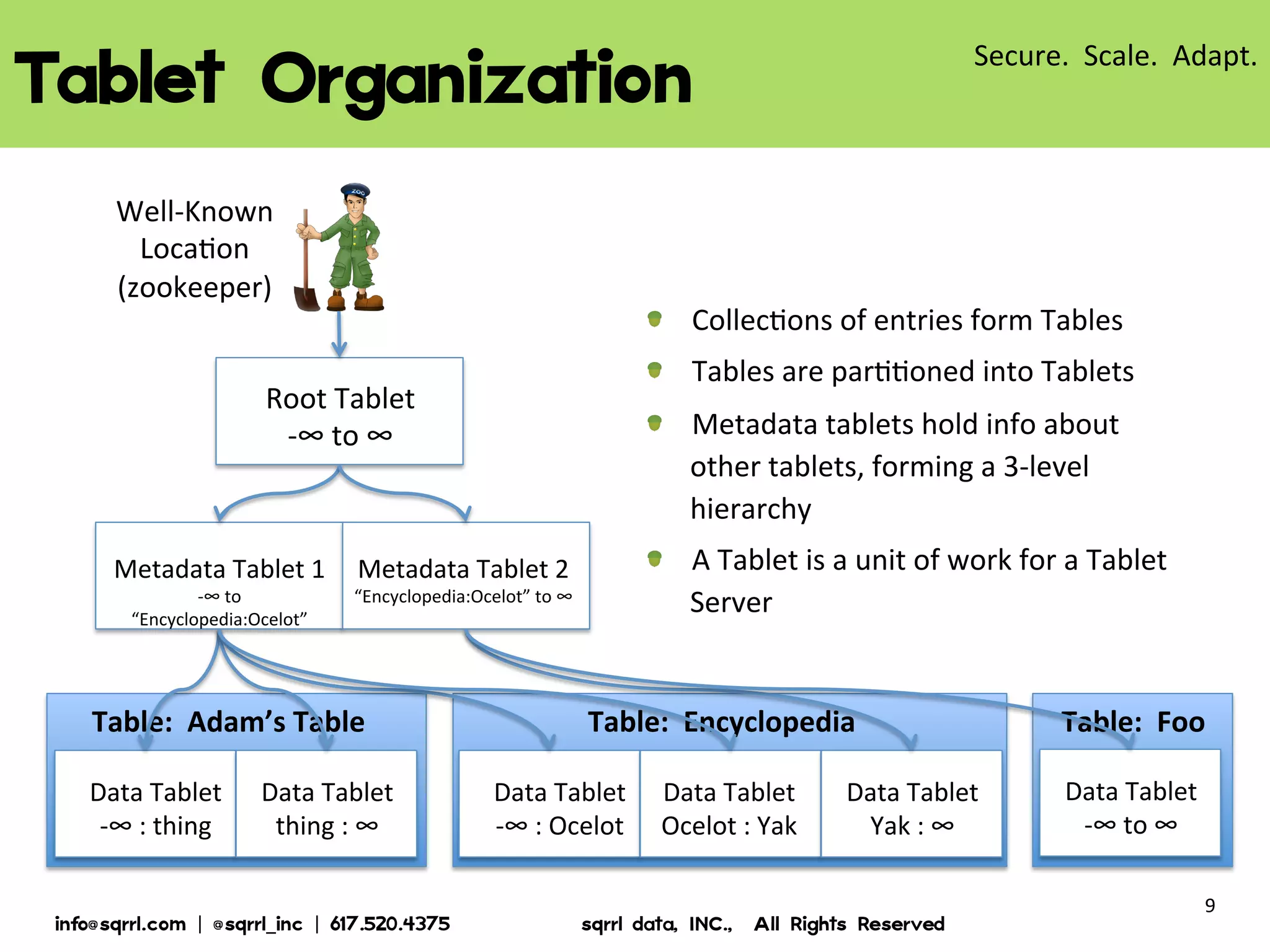
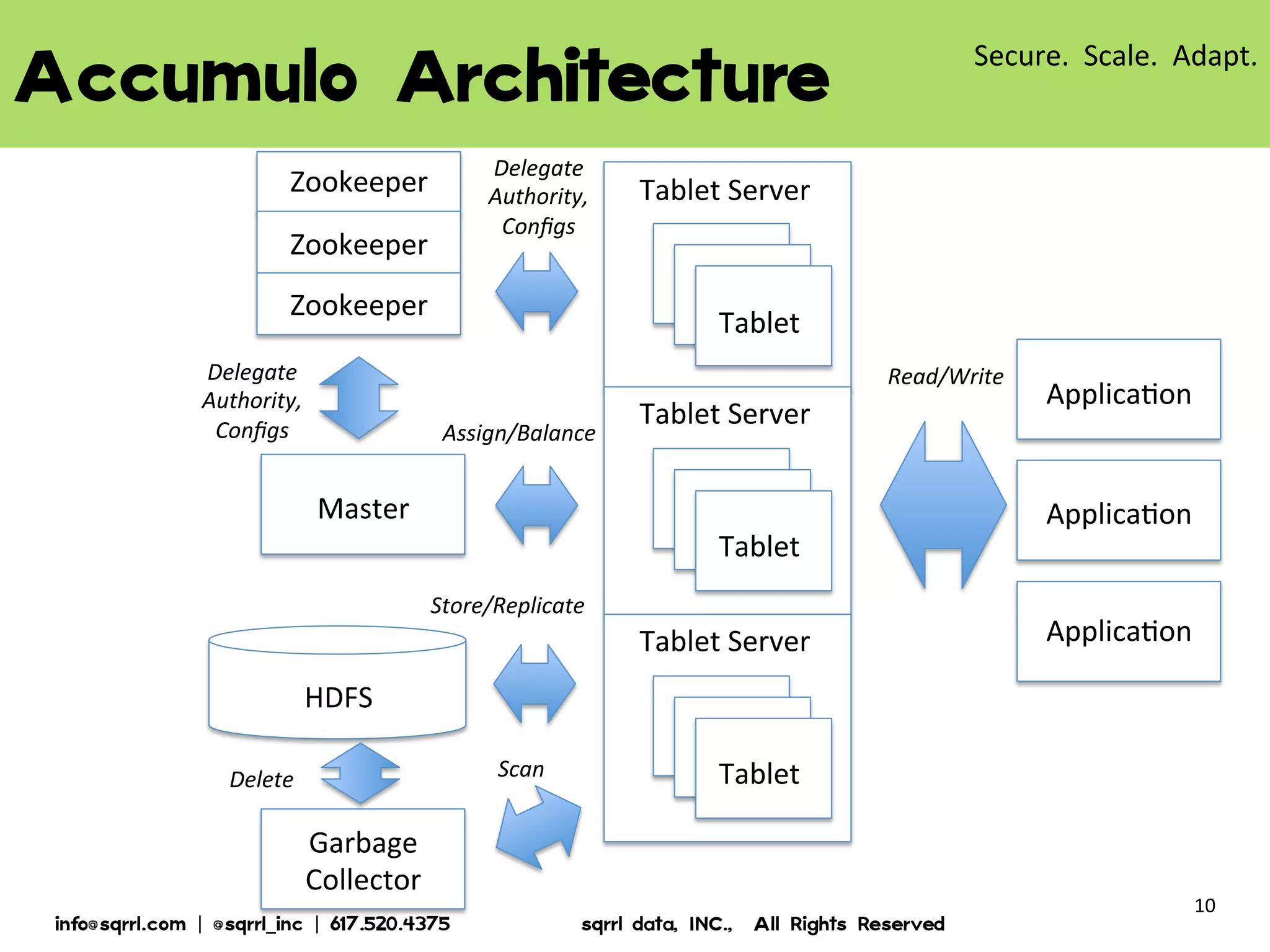
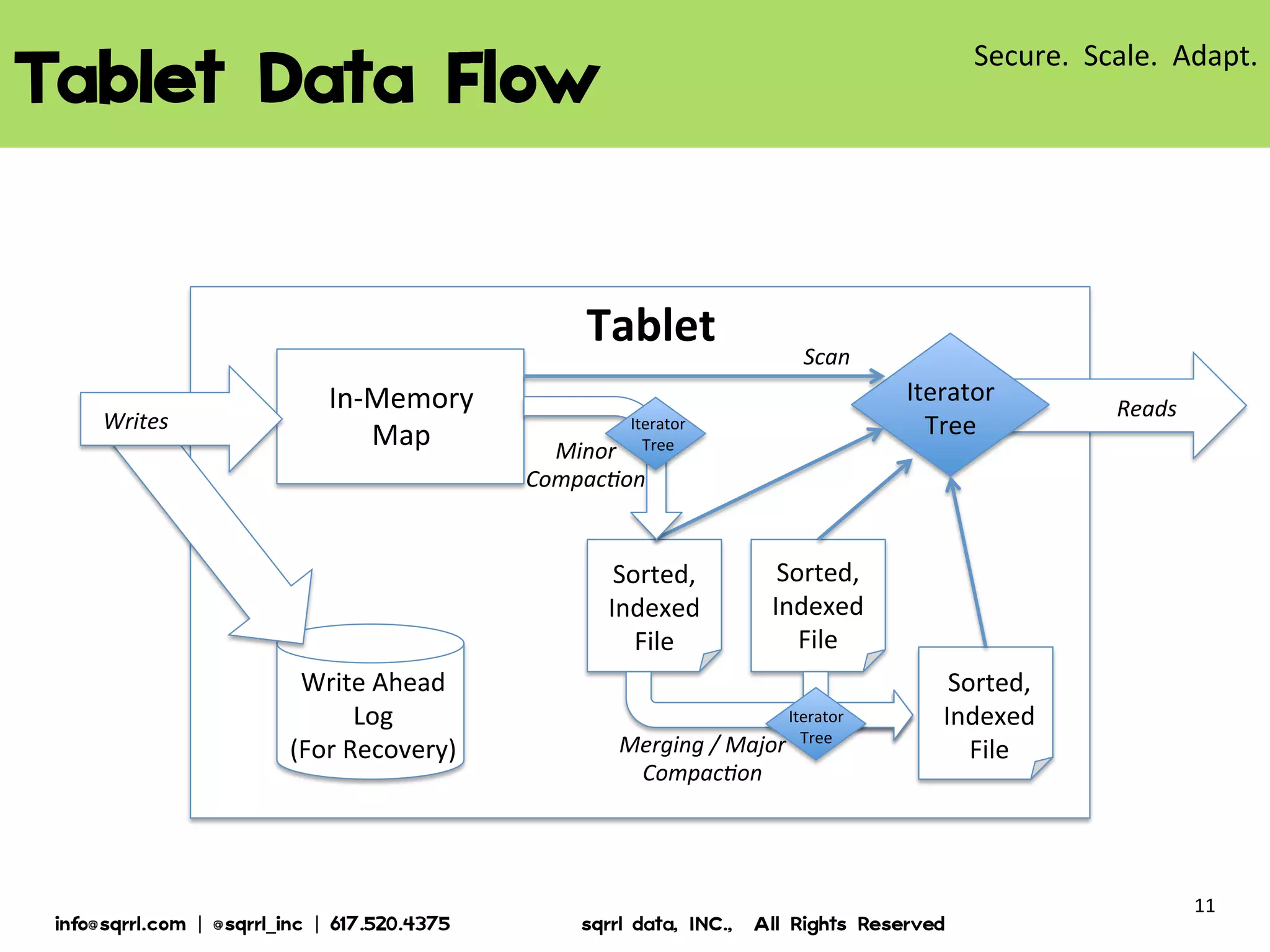
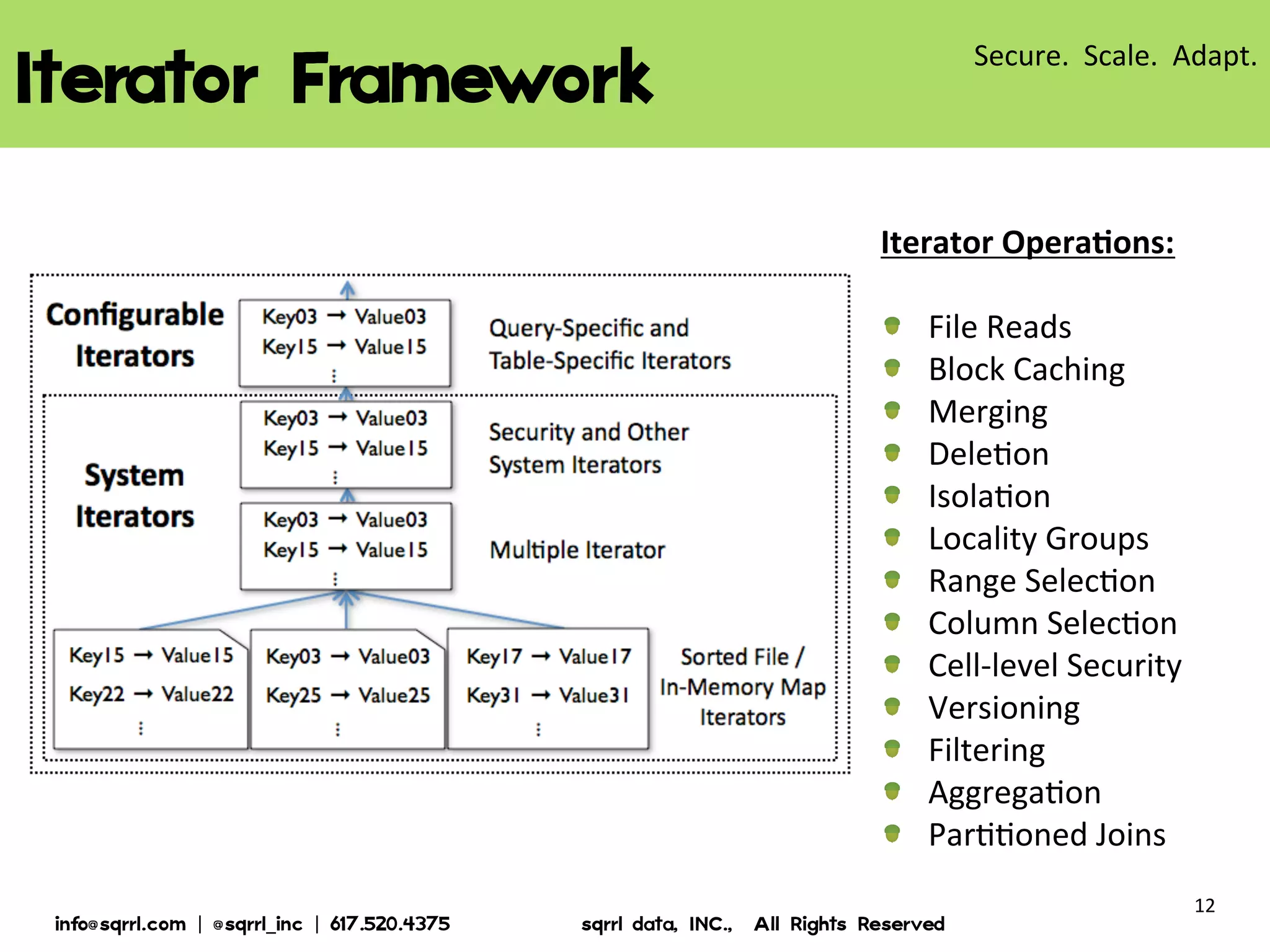
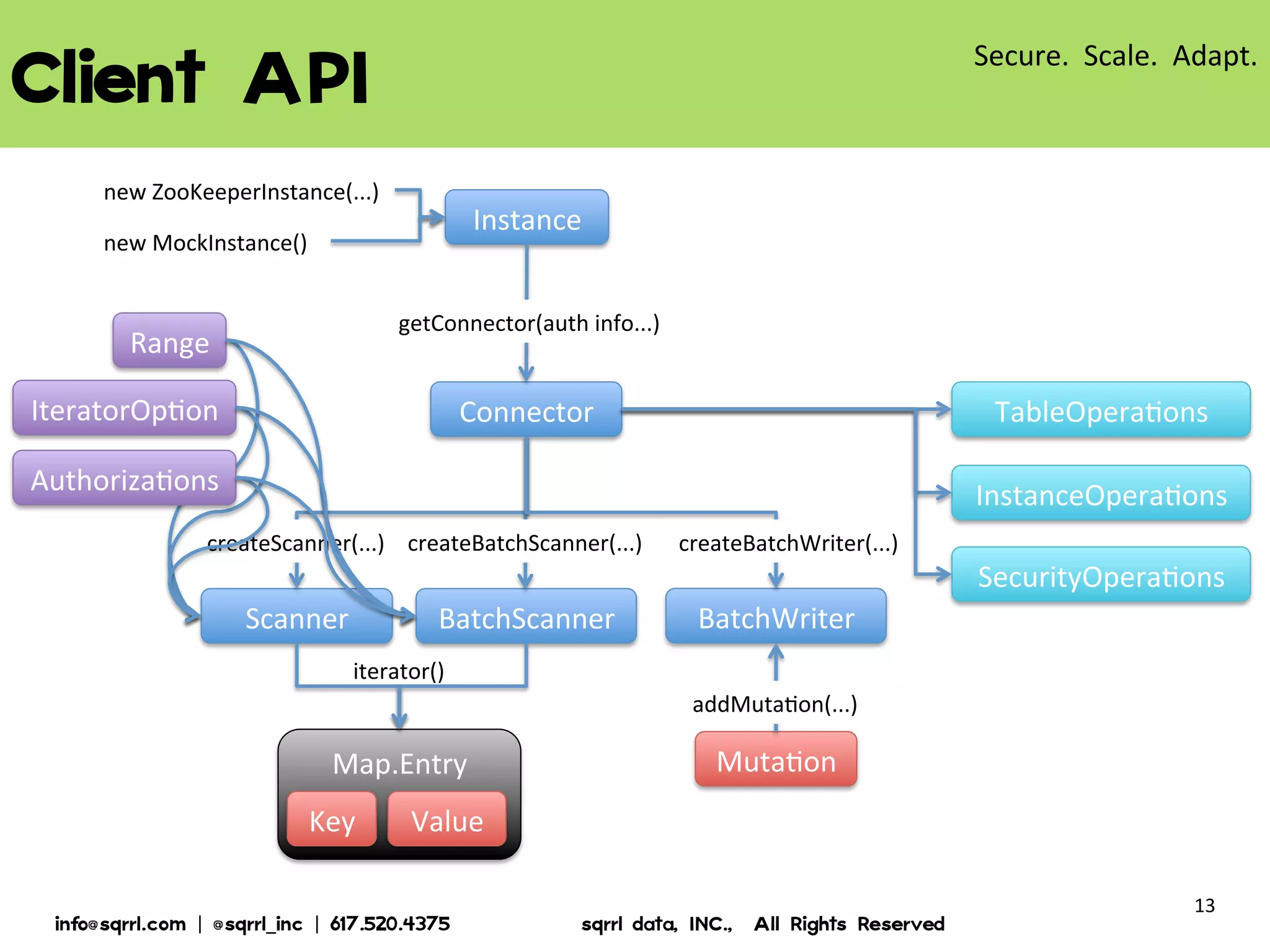
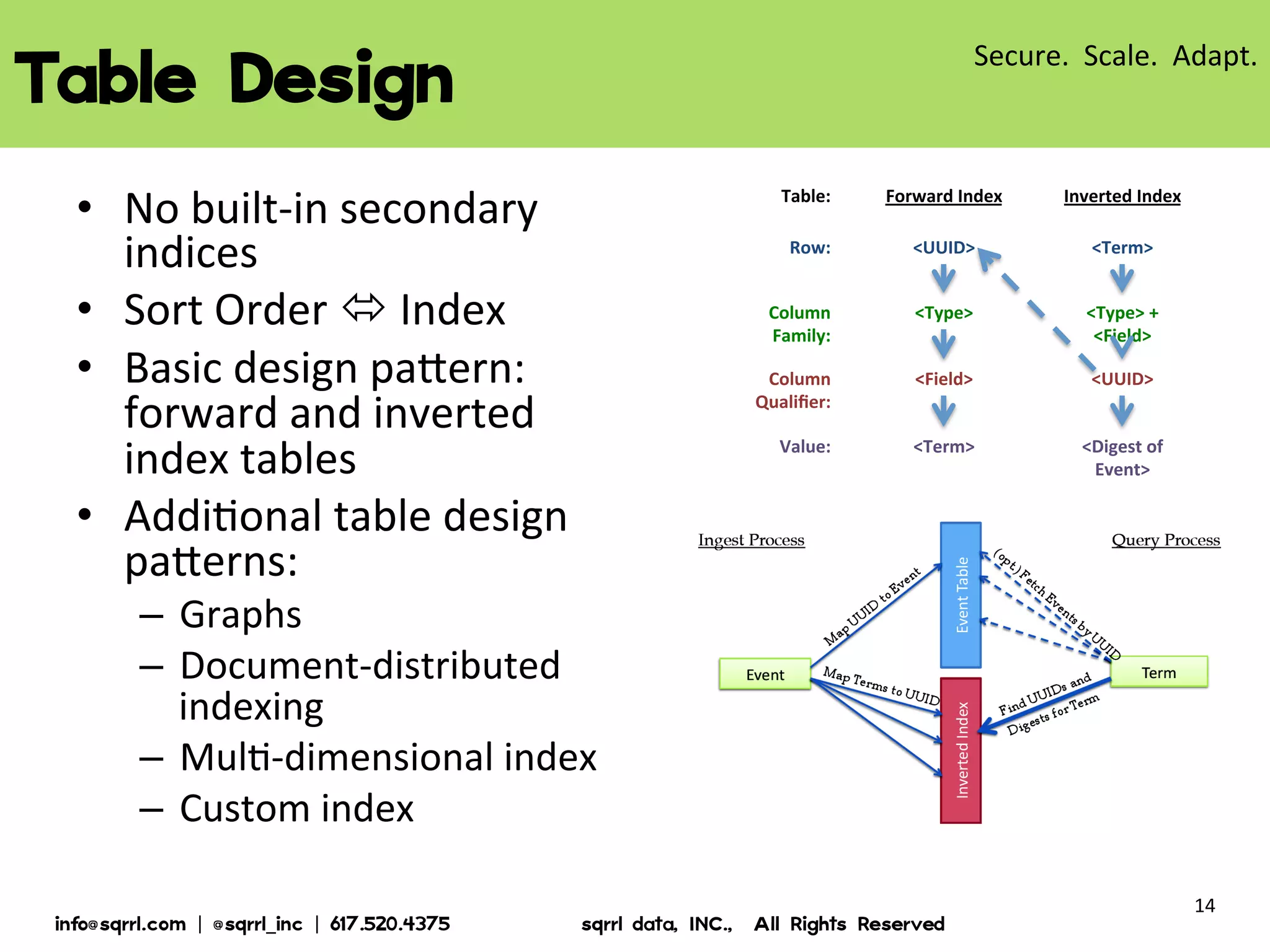

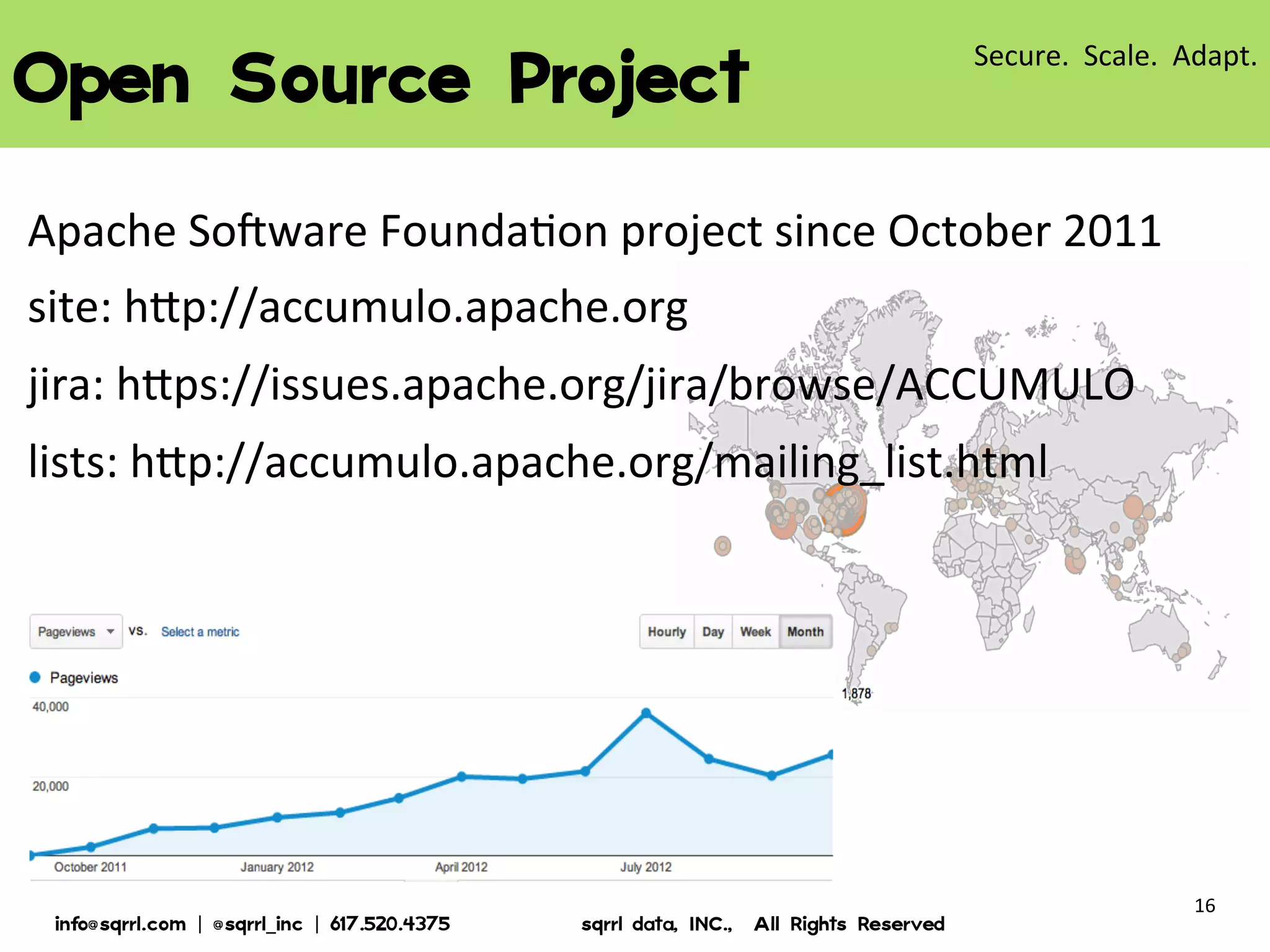
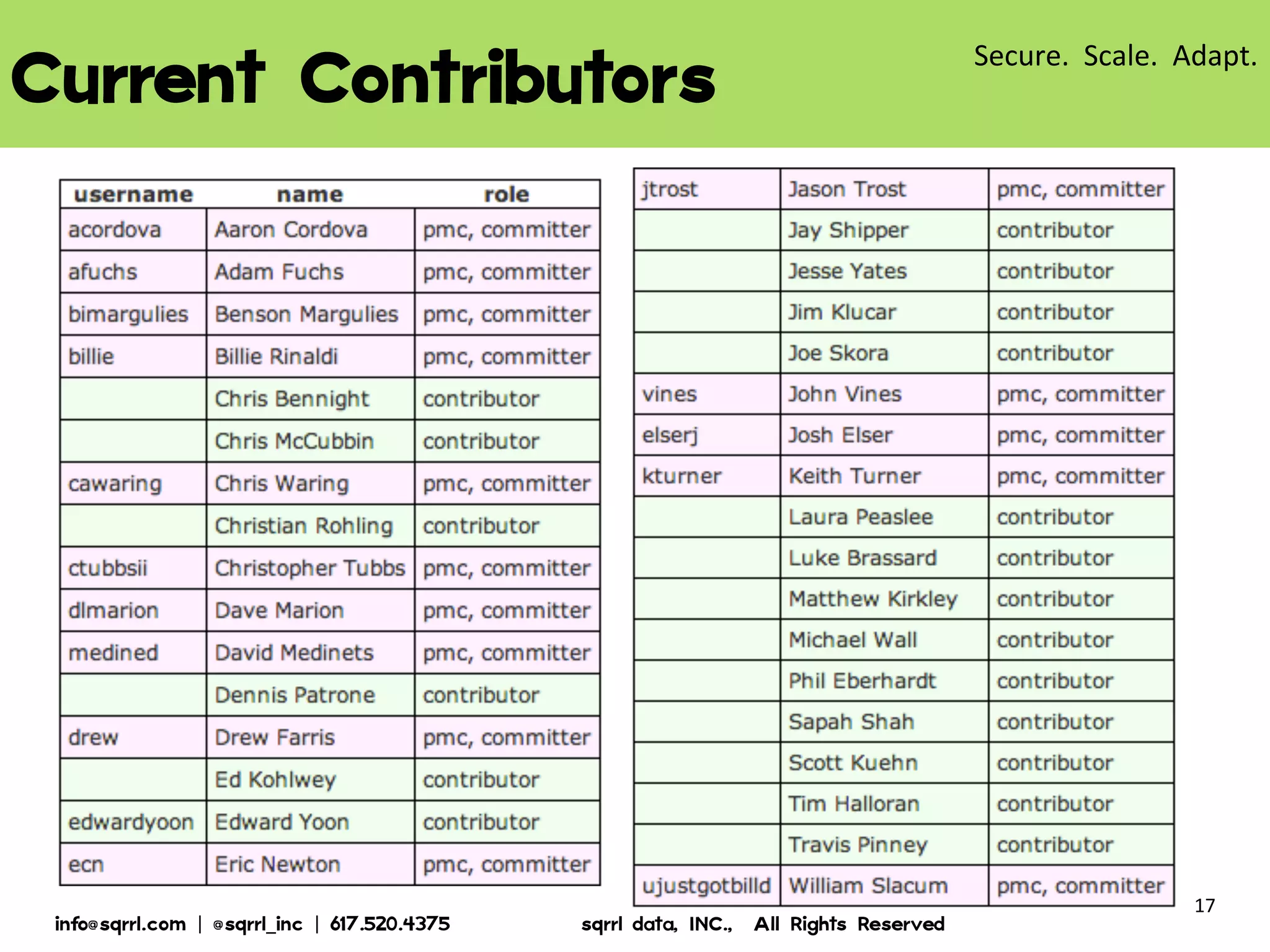


The document discusses Apache Accumulo, an open source distributed key-value store based on Google's Bigtable design. It provides an overview of Accumulo, including its timeline, strengths in security, scalability and adaptability. It describes Accumulo's basic schema of sorted key-value pairs with row, column family, qualifier, visibility and timestamp. It also outlines Accumulo's architecture, tablet organization, data flow, iterator framework and table design strategies.


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















